<기본 용어>
Self Supervised learning
https://brunch.co.kr/@b047a588c11b462/45
: 비지도 학습 방식의 일종으로서 라벨링되지 않은 데이터셋을 활용하여 인공지능이 스스로 분류작업을 수행하도록 함
: 스스로 태스크를 설정하여 모델을 학습한다는 점에서 기존의 비지도 학습 방식과 차이가 존재하며, 인터넷상 크롤링을 통해 수집할 수 있는 텍스트, 이미지, 비디오 등 다양한 종류의 데이터셋을 활용할 수도 있음
: 모델이 확장되기 위해서는 대량의 데이터를 필요로 하지만, 라벨링된 데이터를 지속적으로 확보하기 위해서는 많은 비용이 요구된다는 단점이 존재
: 자기 지도 학습은 라벨링되지 않은 학습 데이터만 확보하더라도 모델의 규모를 증가시킬 수 있으며 이에 따라 정확도 역시 향상시킬 수 있다는 장점이 존재
<지도학습의 두 가지 방법>
1) Self Prediction
: 하나의 데이터 샘플 내에서, 데이터의 일부를 활용해 나머지 부분을 예측하는 방법

2) Contrastive Learning
: 데이터 샘플들 간의 관계를 예측하는 태스크를 수행하며, 유사한 샘플들 간 거리를 가깝게 하고 유사하지 않은 샘플들 간 거리는 멀게 하는 것.
: 유사 여부의 기준이 되는 데이터셋을 anchor라고 함
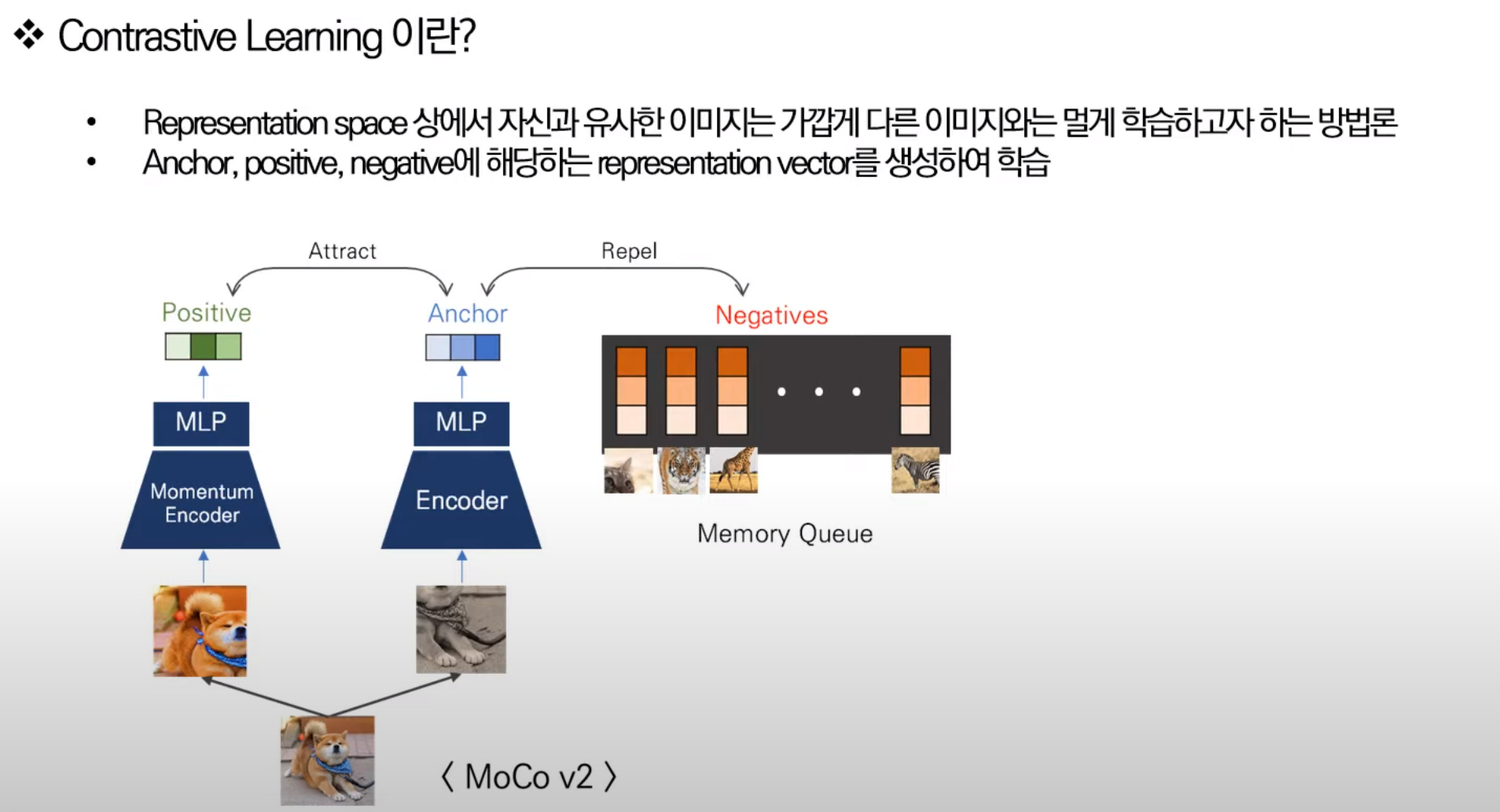
: anchor(회색)와 유사한 샘플을 positive point(시바)로, anchor와 positive pair를 이룸.
: 반대로 anchor와 유사하지 않은 샘플은 negative sample(호랭이)로써 anchor과 negative pair를 이룸
: Contrastive 학습 방식은 다양한 관점들로부터 공통된 정보를 추출하고자 하는 목적을 가짐
: ex) 고양이 이미지에 노이즈를 추가한 이미지와 원본 이미지가 있을 때, 두 이미지 간 공통된 정보에 해당하는 고양이 부분만 학습대상으로 인식되며, 그 외의 배경이나 노이즈는 학습과정에서 고려되지 않음
: contrastive learning의 성능에는 positive sample과 negative sample의 선정방식이 큰 영향을 미침.
: Positive pair는 augmentation 기법들을 활용하여 원본을 변형시키거나, 하나의 데이터에 대한 상이한 관점을 취하는 방식으로 선정됨.
: 한 데이터셋 내에서 anchor이 아닌 샘플들은 negative pair로 여겨지며 negative sample 개수가 많을수록 효과적으로 representation collapse를 방지할 수 있음.
("negative sample" 개수가 많을수록, 모델은 다양한 클래스 간의 차이를 이해하고 구분하는 능력이 향상)
➡️ 하지만 negative sample을 사용할 때, 배치 사이즈 크기나 증강기법 선택 등에 따른 성능 편차가 크게 나타나기 때문에 학습 시 고려해야할 점이 많다는 문제점이 존재
BYOL : Boostrap Your Own Latent

: 기존 negative sample을 사용할 때, 배치 사이즈 고려나, 증강 기법에 따른 성능 편차가 크기 때문에 골칫덩어리었음.
: 따라서, BYOL은 positive sample 만을 사용했다고 함 ⇒ 한 이미지에서 augmentation 한 두 개의 이미지를 input으로 활용(회색이 anchor(target), 색조 이미지가 positive sample(online))
: BYOLO의 구조는 Online network와 Target network로 구성
: Online network로 predictor까지 예측해서 anchor(target network)의 predict을 예측하는 방식임
: 이 때, L2 loss를 통해서 online network gradient를 업데이트 해주고, 업데이트한 파라미터 값과, 기존 target network의 파라미터 값을 활용해서 이동평균 해서 target 을 업데이트 함
※ L2 loss를 사용하는 이유는 negative sample이 없기 때문

※ 여기서 momentum encoder는 online network에서 나온 파라미터 값과 target network 파라미터로 이동평균해서 target값을 업데이트 해주는 방식을 의미하고, 업데이트 규칙이 기존 momentum처럼 처음에는 0.99로 가중치를 줬다가 점점 줄이는 방식으로 업데이트해서 붙여진 말 같음.
추가 기본 용어
ViT
: ViT(Vision Transformer)는 vision task를 위한 Transformer 아키텍처를 이미지 처리에 적용한 딥러닝 모델로, 이미지를 일정 크기의 패치로 분할하여 Transformer의 self-attention 메커니즘을 활용해 특징을 추출하는 방식

Self Distillation
: 레이블이 없는 데이터를 활용하여 학습된 모델인 학생 모델과, 해당 모델의 지식을 전달해주는 모델인 선생님 모델 사이의 유사성을 최적화하는 방법으로, 지식 전달을 통해 학생 모델의 성능을 향상시키는 기법
🌻 DINO요약
: Self-distillation with no labels

: ViT (vision Transformer)에 SSL (Self-Supervised Learning)을 적용해보자!
: DINO의 경우, 객체에만 attention map이 활성화 되어있음
⇒ 배경 정보에는 덜 의존한다 라고 말할 수 있음 ↔️ classification의 경우, 배경 정보도 활용
<주요 특징>
(1) Cross-entropy loss
(2) multi-crop
(3) mean teacher
(4) centering, sharpening
0. ABSTRACT
: 이 논문은 Vision Transformer(ViT)에 대해 Self-Supervised learning)이 conv와 비교해서 새로운 특성을 제공하는지에 대해 의문을 제기
특징
1) DINO는 image의 sementic segmentaion에 대한 명시적인 정보를 포함함
2) 우수한 K-NN 분류기
3) Momentum encoder, multi-crop, 작은 패치 사용의 중요성 강조
1. INTRODUCTION
: Transformer는 최근에 컨볼루션 신경망(convnets) 대안으로 등장
: 본 논문에서는 모델을 지도학습의 사용으로 설명될 수 있는지에 대해 의문을 제기함
: 기존 NLP에서 Transformer의 성공의 주요 구성 중 하나가 BERT 및 GPT의 자기지도 학습의 사용이었음
: 이를 동기 삼아 ViT에 SSL을 적용함
2. RELATED WORK2-1) Self-supervised learning.
: instance classification은 자기 지도 학습의 한 종류로써, 이미지들을 서로 다른 클래스로 간주해서 모델을 훈련하는 방법임
: 주로 data augmentation을 사용해서 이미지를 구분
↔️ 하지만 이 방법의 경우, 이미지 수가 증가함에 따라 확장성이 떨어진다는 문제 존재
: 이를 해결하기 위해 최근 연구들은 instance를 구분하는 것 대신 이미지 간의 유사성을 학습해서 비지도 특징을 학습할 수 있다는 것을 보여줌 (이미지들의 특성을 추출하고 이 특성들을 서로 매칭해서 학습 ⇒ 더 많은 이미지를 처리하는데 유리함)
: 그 중에서도 BYOL이라는 방법은 momentum encoder라는 방법을 사용해서 이미지들의 특성을 매칭하고, 학습함
: BYOL은 자기 지도 학습의 가능성을 보여줌 + 레이블이 없는 상태에서도 높은 성능을 달성
➡️ 따라서, BYOL을 영감으로 + 교사/학생 architecture을 사용함
2-2) Self-training and knowledge distillation.
: 작은 네트워크를 훈련하여 큰 네트워크의 출력을 모방하여 모델을 압축하는 데 사용
3. APPROACH


3-1) SSL with Knowledge Distillation
: knowledge distillation
➡️ 교사 네트워크 gθt의 출력과 일치하도록 학생 네트워크 gθs를 훈련하는 학습 방식
(gθt는 사전에 훈련된 미리 준비된 네트워크로, 학생 네트워크 gθs는 gθt의 출력과 일치하도록 학습하는 과정에서 업데이트되는 네트워크임)
: θs와 θt는 각각 학생 네트워크와 교사 네트워크의 매개변수(모델의 가중치를 의미)
: 이미지 x가 주어졌을 때 두 네트워크 모두 K차원의 확률 분포 Ps와 Pt(각각의 output 값)를 출력함
: 이 때, 확률 분포 P는 네트워크 g의 출력을 softmax function으로 정규화해서 얻음

: τs>0 와 τt>0는 temperature parameter이며 출력 분포의 뾰족한 정도를 조절함 (뒤에서 설명)
: 고정된 teacher 네트워크 gθt가 주어진 상태에서, student 네트워크의 매개변수 θs에 대해 분포를 일치시키기 위해 교차 엔트로피 손실을 최소화하려고
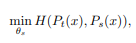
※ H(a,b)=−alogb
: Ps(a)와 Pt(a)는 각각 student와 teacher 네트워크가 출력한 동일한 클래스 a에 대한 확률
: student 네트워크는 teacher 네트워크의 출력 분포와 유사한 출력 분포를 생성하도록 유도됨( 학생이 선생님처럼 되도록 학습됨 )
👻 self-supervised learning에 적용하는 방법
: multi-crop을 사용해서 주어진 하나의 이미지에서 두 가지의 view로 구성함
- 전체 이미지를 담고 있는 글로벌 뷰(global view)
- 224x224 해상도의 2개의 전역 뷰와 원본 이미지의 큰 영역 (예: 50% 이상)을 포함
- 이미지의 작은 지역만을 포함하는 로컬 뷰(local view)
- 96x96 해상도의 여러 로컬 뷰와 원본 이미지의 작은 영역 (예: 50% 미만)을 포함하는 방식을 사용
1) local + global (student input으로 들어감)
2) global (teacher input으로 들어감)
➡️ local에서 global 대응을 유도했음 (글로벌 뷰를 기준으로 로컬 뷰와의 관계를 학습)
: 아래의 loss를 최소화함

⇒ 두 네트워크 모두(선생, 학생) 다 같은 architecture을 가지지만, 서로 다른 파라미터 θs와 θt 를 가짐
: θs는 SGD(확률적 경사 하강법)을 사용해서 매개변수를 업데이트함 (선생은 이미 학습되어있음-아래 참고)
Teacher network
: Knowledge distillation과 다르게 사전 지식으로 teacher network gθt를 갖기 않기에, teacher network를 student network의 이전 iteration으로 구축하였음
: <Freeze> Teacher Network는 한 epoch 동안 동결(freeze)됨. 이는 학생 네트워크를 훈련하는 동안 teacher network의 가중치를 업데이트하지 않고 고정하여 사용하는 것을 의미함
👻 teacher network 어떤걸로?
: <학생 가중치를 teacher 가중치로 > student의 가중치를 teacher의 가중치로 직접 복사하는 방법이 시도되었으나, 수렴하지 않아서 좋은 결과를 얻지 못했다고 함
: <momentum encoder> Student의 가중치에 exponential moving average (EMA)를 사용하는 momentum encoder를 사용했다고.
⇒ 업데이트 규칙: θt ← λθt + (1 - λ)θs
: λ는 훈련 중에 0.996에서 1로 증가하는 코사인 스케줄을 따름
: 원래는 momentum encoder가 contrastive learning에서 사용되었으나, DINO는 큐(잘몰라)나 contrastive loss가 없기에 momentum encoder가 mean teacher(두 모델의 출력을 평균해서 새로운 목표 특징을 생성하고, 학생 모델을 이 새로운 목표 특징으로 훈련 ⇒ 학생의 선생 특징을 더 학습 잘하게끔)의 역할을 함
: 학습 중에는 teacher가 student보다 더 성능이 좋으며, teacher가 target feature들을 고품질로 제공하여 student의 학습을 guide함
Network architecture
: 모델(g)는 ViT나 ResNet backbone f (ViT [19] 또는 ResNet [34])와 projection head h로 구성됨
: (g=h∘f) Projection head는 layer 3개의 MLP, L2정규화, 가중치가 정규화된 FC layer로 구성
: ViT 아키텍처는 기본적으로 batch 정규화(BN)를 사용하지 않음
: 전체 architecture에 BN이 없음
Avoiding collapse
※ collapse: 모델이 입력 데이터를 적절하게 다양한 방식으로 인코딩하지 않고, 각 입력에 대해 일정한 특정한 값으로 수렴하여 정보를 잃어버리는 현상 (특정 차원이 지나치게 우세해져서, 모델이 그 차원에 대한 정보만을 사용하여 결과를 예측하는 상태를 말함)
: self-supervised 방법이 contrastive loss, clustering constraints, predictor, BN 등의 다양한 방법으로 collapse를 피하려고 함
⇒ DINO는 momentum teacher output을 정렬하고, centering 및 sharpening으로 해결함
1) Centering
: 원점을 기준으로 중심화(특징들의 평균을 계산하여 해당 값을 특징들에서 빼는 방)
: 어떤 특정 차원이 다른 차원에 비해 지나치게 우세해지는 것을 방지
: 즉, 특정 차원이 지나치게 큰 값을 가지지 않도록 보정하는 역할을 함
: centering이 적용되면 모델의 특징들이 균일한 분포로 변환됨. 즉, 모델의 출력 특징들이 모두 비슷한 값으로 수렴하게 되는데, 이로 인해 모든 입력 데이터가 거의 동일한 특징으로 사상되는 문제가 발생하게 됨
2) Sharpening
: 특징들의 분포를 조절해서, 더 뚜렷하고 선명한 분포를 얻는 것을 의미.
: Temperature parameter (τ)라는 하이퍼파라미터를 조절하여 softmax 함수의 선명도를 조절.
: Temperature 값이 낮을수록 softmax 함수의 분포가 더 sharp해지고, 값이 높을수록 더 균일한 분포가 됨
⇒ 붕괴를 방지함. But, centering을 함으로써 안정성은 얻지만, batch에 대한 의존성이 줄어든다고 함 (centering에서의 평균값 사용은 해당 배치의 특징들에 대한 통계 정보이기 때문에, 다른 배치에 대해서는 성능이 떨어질 수 있다는 말임)
⇒ 1차 배치 통계에만 의존한다고.
: 결국, centering과 sharpening의 역할은 teacher에 bias 항을 추가하는 것과 같은 뜻임.
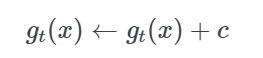
: c는 EMA로 업데이트 됨. batch size가 다르더라도 잘 작동한다고 함
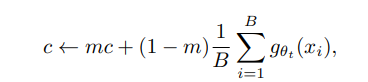
: m>0 은 이동평균을 계산하는데 사용하는 비율 파라미터 (현재 데이터를 얼마나 중요하게 받을건지에 대한 가중치 파라미터 - 람다랑 같은 역할인 듯)
: B는 batch size
3-2) Implementation and evaluation protocols
Vision Transformer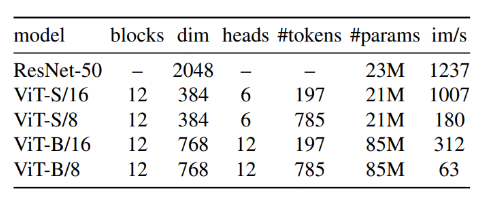
: ViT 아키텍처는 해상도 N × N의 겹치지 않는 이미지 patch grid를 입력으로 받음
: N = 16 (" /16 ") 또는 N = 8 (" /8 ")을 사용
: 패치들은 선형 레이어를 통해 임베딩 집합으로 변환
: 전체 정보를 볼 수 있도록 토큰 하나를 추가함 + 출력에 projection head h를 연결
: 이 토큰은 어떠한 레이블이나 supervision에 연결되지는 않지만 기존 연구들과의 일관성을 위해 클래스 토큰 [CLS-Special Classificaiton token]이라 부름 (첫번째 시작 토큰)
: 패치 토큰과 [CLS] 토큰은 pre-norm layer normalization을 가진 표준 Transformer network에 입력됨
: Transformer는 self-attention과 feed-forward layer의 시퀀스이며 skip connection 사용
: Self-attention layer는 attention mechanism으로 다른 토큰 표현을 보고 각 토큰 표현들을 업데이트
Implementation details
: 데이터셋: ImageNet 데이터셋에 레이블 없이 사전 학습
: batch size 1024, adamw optimizer, 16 GPUs
: learning rate는 처음 10 epoch만 0.005×batchsize/256까지 warm up 후 cosine schedule로 decay
: weight decay: cosine schedule로 0.04에서 0.4
: τs=0.1, τt는 0.04에서 0.07로 초반 30 epoch동안 linear-warmup
: BYOL의 data augmentation (color jittering, Gaussian blur and solarization)과 multi-crop을 사용
Evaluation protocols
- 생략
<참고>
http://dmqm.korea.ac.kr/activity/seminar/310
https://kyujinpy.tistory.com/44
https://kimjy99.github.io/논문리뷰/dino/
'Deep Learning > [논문] Paper Review' 카테고리의 다른 글
| Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization (0) | 2023.08.13 |
|---|---|
| STAR: Sparse Trained Articulated Human Body Regressor(2020) (0) | 2023.08.10 |
| Expressive Body Capture: 3D Hands, Face, and Body from a Single Image (0) | 2023.08.04 |
| BodyNet: Volumetric Inference of 3D Human Body Shapes (0) | 2023.08.03 |
| mixup: Beyond Emprical Risk Minimization (0) | 2023.08.03 |



