728x90
반응형
5-1) 계산 그래프
- 계산 과정을 그래프로 나타낸 것
- 노드(node)/ 에지(edge): 노드 사이의 직선을 에지라고 부름
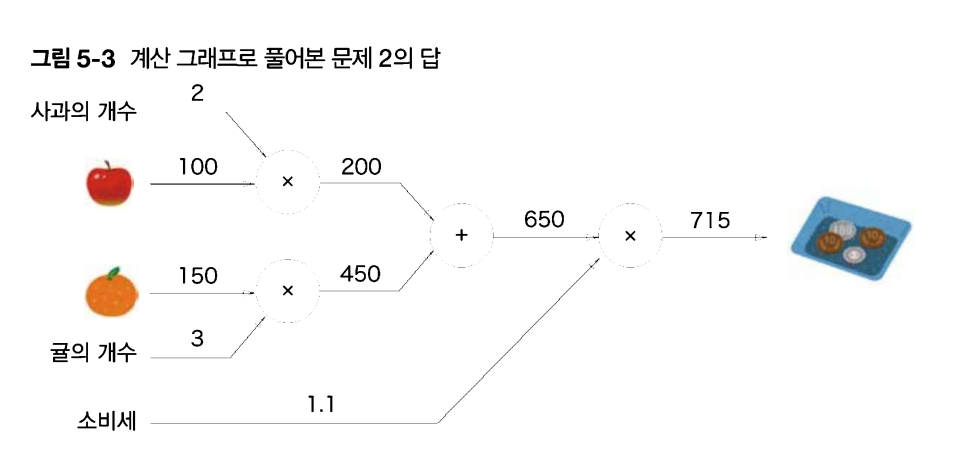
⇒ 순전파라고 함(왼쪽에서 오른쪽으로 진행)
국소적 계산
- 전체적으로 보면 복잡한 계산식이지만 파고들면 간단한 수식으로 이루어져 있는 ⇒ 국소적 계산이라고 함.( 전체 식은 개복잡 but, 안으로 들어가면 덧셈 뺄셈으로 이루어짐)
계산 그래프의 이점
- 국소적 계산
- 전체가 복잡해도 안에서는 간단하게 문제 단순화해서 풀 수 있음
- 중간 중간의 계산 결과 저장 가능
- 역전파를 통해 ‘미분’을 효율적으로 계산 가능
5-2) 연쇄 법칙
- 합성 함수의 미분에 대한 성질
- 합성 함수의 미분: 합성 함수를 구성하는 각 함수의 미분의 곱으로 나타낼 수 있다
5-3) 역전파
5-3-1) 덧셈 노드의 역전파
- 그냥 다음 노드로 출력함 (덧셈 함수의 경우, 미분하면 1이 되므로) ex) z= x+y
5-3-2) 곱셈 노드의 역전파
- 앞의 출력값 x 미분값

5-4) 단순 계층 구현
- 곱셈 계층
class MulLayer: def __init__(self): self.x = None self.y = None def forward(self, x, y): self.x = x self.y = y out = x * y return out def backward(self, dout): dx = dout * self.y # x와 y를 바꾼다. dy = dout * self.x return dx, dyfrom layer_naive import * apple = 100 apple_num = 2 tax = 1.1 # 계층들 mul_apple_layer = MulLayer() mul_tax_layer = MulLayer() # 순전파 apple_price = mul_apple_layer.forward(apple,apple_num) price = mul_tax_layer.forward(apple_price,tax) print(price) # 220 # 역전파 dprice = 1 dapple_price, dtax = mul_tax_layer.backward(dprice) dapple, dapple_num = mul_apple_layer.backward(dapple_price) print(dapple, dapple_num, dtax) # 2.2 110 200- 덧셈 계층
class AddLayer: def __init__(self): pass def forward(self, x, y): out = x + y return out def backward(self, dout): dx = dout * 1 dy = dout * 1 return dx, dy
5-5) 활성화 함수 계층 구현(ReLU, Sigmoid)
ReLU 계층


class Relu: def __init__(self): self.mask = None def forward(self, x): self.mask = (x <= 0) out = x.copy() out[self.mask] = 0 return out def backward(self, dout): dout[self.mask] = 0 dx = dout return dx- x가 0보다 크면 역전파의 경우, 상류 값을 하류로 그대로 전달
- x가 0보다 작으면 0으로 전달
Sigmoid 계층

- 구체화 버전(식)

- 간소화 버전


- 역전파의 경우, 순전파 출력(y)만으로 구현 가능
class Sigmoid: def __init__(self): self.out = None def forward(self, x): out = sigmoid(x) # 순전파의 출력을 out에 보관한 후 역전파 계산 때 그 값을 사용 self.out = out return out def backward(self, dout): dx = dout * (1.0 - self.out) * self.out return dx
5-6) Affine/Softmax 계층 구현
Affine 계층
- 순전파 때 수행하는 행렬의 곱: affine 변환
- 어파인 변환을 수행하는 처리: affine 계층이라고 칭함

- affine 계층의 역전파
배치용 Affine 계층
- 데이터 N개를 묶은 경우
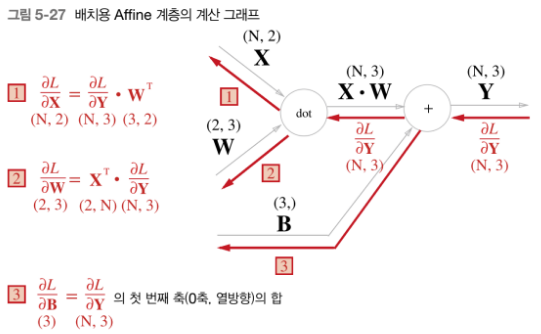
class Affine: def __init__(self, W, b): self.W = W self.b = b self.x = None self.original_x_shape = None # 가중치와 편향 매개변수의 미분 self.dW = None self.db = None def forward(self, x): # 텐서 대응 self.original_x_shape = x.shape x = x.reshape(x.shape[0], -1) self.x = x out = np.dot(self.x, self.W) + self.b return out def backward(self, dout): dx = np.dot(dout, self.W.T) self.dW = np.dot(self.x.T, dout) self.db = np.sum(dout, axis=0) dx = dx.reshape(*self.original_x_shape) # 입력 데이터 모양 변경(텐서 대응) return dx- 순전파의 편향 덧셈: 각 데이터에 편향이 더해짐
- 역전파의 편향: 데이터의 합을 구한 뒤 미분으로 편향 구함
Softmax-with-Loss 계층
- 소프트 맥수: 정규화, 출력층에서 사용, 출력합: 1
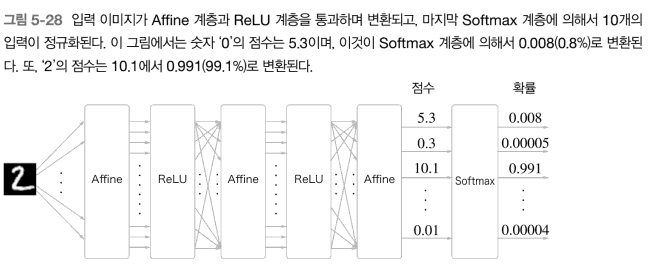
- 점수를 확률의 범위로 (0~1 사이로 정규화)
- but 추론할 때는 굳이 점수 중 높은 값을 고르면 되기에 확률로 변환해줄 필요가 없음 ⇒ 소프트 맥스 사용 안씀 (학습 시에는 사용)
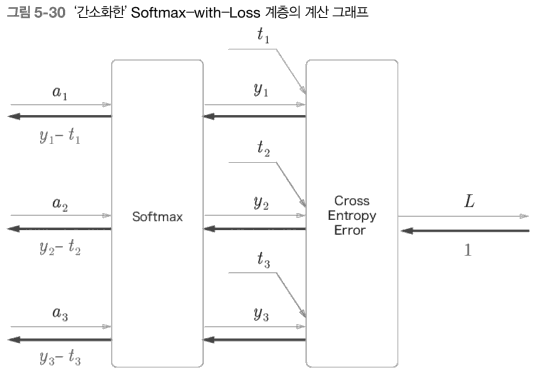
- 출력값-정답값( softmax 계층의 출력과 정답 레이블의 차분을 의미)
- 신경망의 목표는 출력값이 정답과 가까워지도록 가중치 매개변수를 조정하는 것임.
- (출력-정답값) 이 오차가 앞 계층에 전달됨 ⇒ 오차를 효율적으로 앞 계층에 전달해야.
class SoftmaxWithLoss: def __init__(self): self.loss = None # 손실함수 self.y = None # softmax의 출력 self.t = None # 정답 레이블(원-핫 인코딩 형태) def forward(self, x, t): self.t = t self.y = softmax(x) self.loss = cross_entropy_error(self.y, self.t) return self.loss def backward(self, dout=1): batch_size = self.t.shape[0] if self.t.size == self.y.size: # 정답 레이블이 원-핫 인코딩 형태일 때 dx = (self.y - self.t) / batch_size else: dx = self.y.copy() dx[np.arange(batch_size), self.t] -= 1 dx = dx / batch_size return dx
5-7) 오차역전파법 구현
구현 단계
- 전제: 가중치와 편향을 훈련 데이터에 적응하도록 조정하는 과정(=학습)
- 1단계- 미니배치
- 무작위 데이터 산출(미니배치), 미니배치의 손실 함수 값을 줄이는 것이 목표
- 2단계- 기울기 산출
- 손실함수 값을 줄이기 위해 각 가중치 매개변수의 기울기를 구함 ⇒ 손실함수 값 작도록 방향 제시
- 3단계- 매개변수 갱신
- 기울기 방향으로 갱신
- 4단계- 1~3단계 반복
코드
import sys, os sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정 import numpy as np from common.layers import * from common.gradient import numerical_gradient from collections import OrderedDict class TwoLayerNet: def __init__(self, input_size, hidden_size, output_size, weight_init_std = 0.01): # 가중치 초기화 self.params = {} self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size) self.params['b1'] = np.zeros(hidden_size) self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size) self.params['b2'] = np.zeros(output_size) # 계층 생성 self.layers = OrderedDict() #값 저장(역전파 때 input 바꿔서 계산하기 때문!) self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1']) self.layers['Relu1'] = Relu() self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2']) self.lastLayer = SoftmaxWithLoss() def predict(self, x): for layer in self.layers.values(): x = layer.forward(x) return x # x : 입력 데이터, t : 정답 레이블 def loss(self, x, t): y = self.predict(x) return self.lastLayer.forward(y, t) def accuracy(self, x, t): y = self.predict(x) y = np.argmax(y, axis=1) if t.ndim != 1 : t = np.argmax(t, axis=1) accuracy = np.sum(y == t) / float(x.shape[0]) return accuracy # x : 입력 데이터, t : 정답 레이블 def numerical_gradient(self, x, t): loss_W = lambda W: self.loss(x, t) grads = {} grads['W1'] = numerical_gradient(loss_W, self.params['W1']) grads['b1'] = numerical_gradient(loss_W, self.params['b1']) grads['W2'] = numerical_gradient(loss_W, self.params['W2']) grads['b2'] = numerical_gradient(loss_W, self.params['b2']) return grads def gradient(self, x, t): # forward self.loss(x, t) # backward dout = 1 dout = self.lastLayer.backward(dout) layers = list(self.layers.values()) layers.reverse() for layer in layers: dout = layer.backward(dout) # 결과 저장 grads = {} grads['W1'], grads['b1'] = self.layers['Affine1'].dW, self.layers['Affine1'].db grads['W2'], grads['b2'] = self.layers['Affine2'].dW, self.layers['Affine2'].db return grads기울기 검증하기
- 수치 미분 vs (해석적 수식)오차역전파법
- 수치미분과 오차역전파법의 결과를 비교 ⇒ 오차역전파법을 제대로 구현했는가에 대한 검증 ⇒ 기울기 확인
import sys, os sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정 import numpy as np from dataset.mnist import load_mnist from two_layer_net import TwoLayerNet # 데이터 읽기 (x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True) network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10) x_batch = x_train[:3] t_batch = t_train[:3] grad_numerical = network.numerical_gradient(x_batch, t_batch) grad_backprop = network.gradient(x_batch, t_batch) # 각 가중치의 절대 오차의 평균을 구한다. for key in grad_numerical.keys(): diff = np.average( np.abs(grad_backprop[key] - grad_numerical[key]) ) print(key + ":" + str(diff))
728x90
반응형
'Deep Learning > 2023 DL 기초 이론 공부' 카테고리의 다른 글
| [밑바닥부터 시작하는 딥러닝 2] chap6(게이트가 추가된 RNN) (0) | 2023.07.09 |
|---|---|
| [밑바닥부터 시작하는 딥러닝 2] chap8(어텐션) (0) | 2023.07.08 |
| [밑바닥부터 시작하는 딥러닝 1] chap2(퍼셉트론) (0) | 2023.07.08 |
| [밑바닥부터 시작하는 딥러닝 1] chap4(신경망 학습) (0) | 2023.07.08 |
| [밑바닥부터 시작하는 딥러닝 1] chap3(신경망) (0) | 2023.07.08 |



