1. 3D Vision Topics

2. 3D Shape Representations
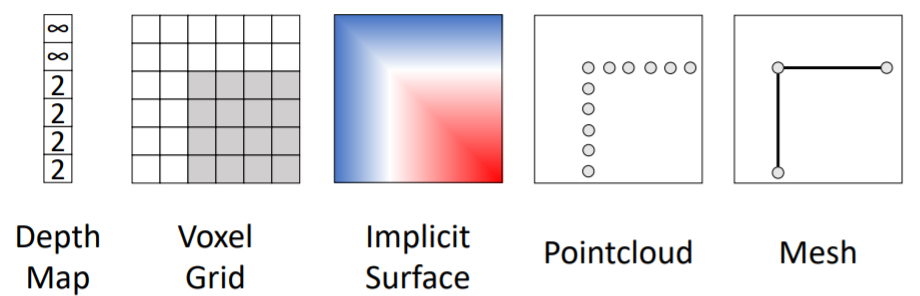
2.1 3D Shape Representations: Depth Map

- Depth map은 각 pixel에 대해 카메라와 픽셀 사이의 거리를 구함
- 기존 segmentation 처럼 FC를 통해 pixel 별로 계산할 수 있다
- 이를 통해 Predicted Depth Image와 Ground-Truth image와의 Per-pixel loss를 계산하여 학습할 수 있음
- 하지만 우리 눈에서는 작고 가까이 있는 물체와 크고 멀리 있는 물체의 크기를 구분하지 못함

- 위 문제를 해결하기 위해, Scale invariant loss를 사용한다고 함 (위 논문 참고)
※ Scale invariant loss란: 시스템이나 함수, 통계 정보에 특정 양만큼 scale을 해주어도 그들의 모형이나 성질이 변하지 않는 경우 (불변성의 의미)
※ 멀리서 보나 가까이서 보나 변하지 않는다면, Scale invariance라고 말할 수 있음.
2.2) 3D Shape Representations: Surface Normals

- 초록색은 왼쪽 혹은 오른쪽 방향을, 보라색은 윗방향을, 붉은색은 앞쪽을 가리킴

- FC를 걸쳐서 각 픽셀당 3-dim vector을 계산하고, ground-truth와 예측한 값에 대한 벡터의 각도를 비교함
💢 단점: 가려진 부분에 대해서는 측정할 수 없음. 사실상 2.5D 이미지라고 함
2.3) 3D Shape Representations: Voxels

💢 문제점: 더 구체적이고, 디테일한 표현을 위해서는 촘촘한 3D grid가 필요. 하지만 높은 해상도로 확장하는 것은 어렵다
2.3.1) Processing Voxel Inputs: 3D Convolution

- 1은 channel이고 30x30x30은 공간 차원
- 1channel은 3d voxel grid가 채워져있는지 아닌지에 대한 것을 나타내는 feature
2.3.2) Generating Voxel Shapes: 3D Convolution

| Input (Image) | Output (Voxels) |
| 3(RGB) x (112 x 112) | 1(Voxel grid ON/OFF) x (V x V x V) |
| RGB 2차원 이미지 | voxel grid로 이루어진 3차원 voxel grid |
- output을 만들기 위해서는 새로은 extra spatial dimension이 필요함.(2차원에서 3차원을 생성해야하므로).
- 그리고 voxel grids를 predict하는 쉬운 방법 중 하나는 3d와 4d tensor간의 차이를 fc-layer을 통해서 계산하는 것.
- input이미지에 대해 2D CNN을 통과하고 나면 CxHxW의 3d feature map이 나오고 이를 큰 하나의 vector로 flattening시킴. 그리고 fc-layers를 통해 4d tensors로 reshape시킴. 이후, 3D CNN을 가지고
upsampling시켜주어 최종 voxel grid를 생성.
💢 단점: 계산이 많이 필요
2.3.3) Generating Voxel Shapes: "Voxel Tubes"
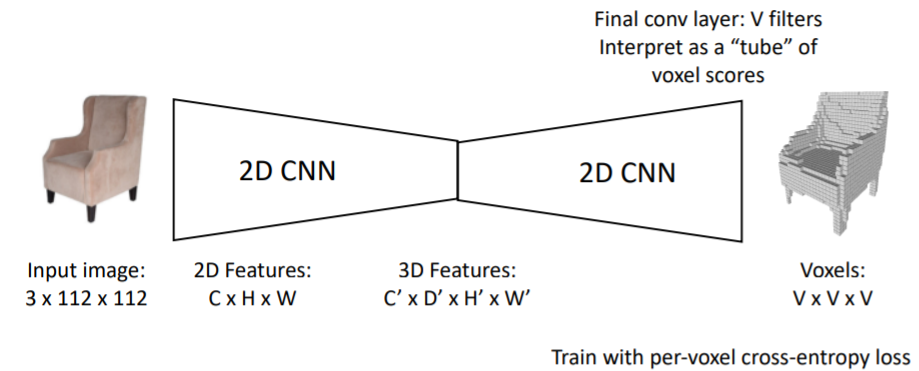
- output으로는 V*V*V의 형태로 나타냄. x*y*z 형태로
2.3.4) Voxel Problems: Memory Usage
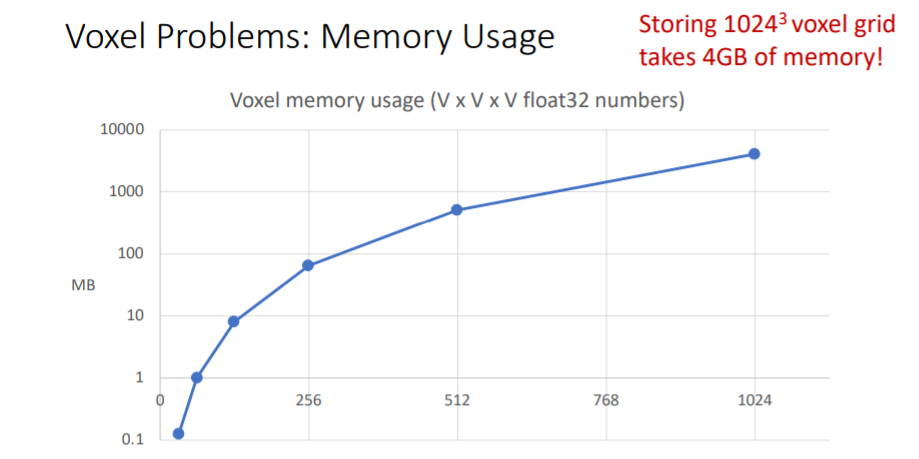
- high resolution voxel grid를 얻기 위해서는 많은 메모리가 필요. 따라서 very high spatial resolutions에서는 naive voxel grids를 사용하기에 적합하지 않음.
💢 하지만, scaling 방법을 통해서 가능하게 하는 방법이 존재
2.4) Scaling Voxels
2.4.1) Oct-Trees
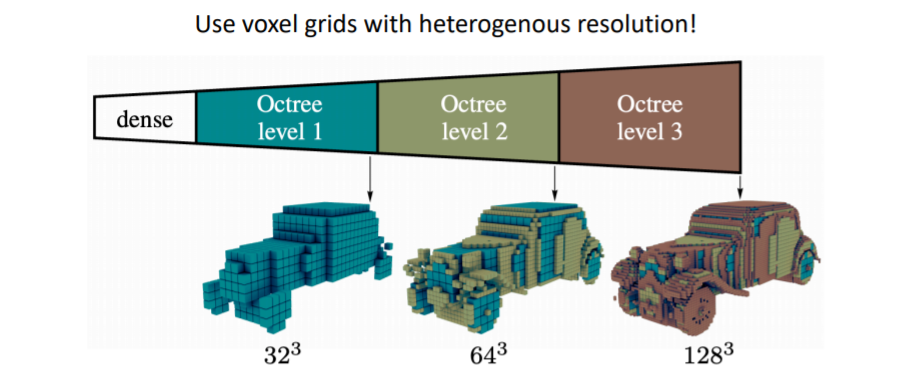
- 이를 통해 coarse voxels를 생성하고 세부적인 디테일은 fine voxels(higher resolution)을 사용하여 표현
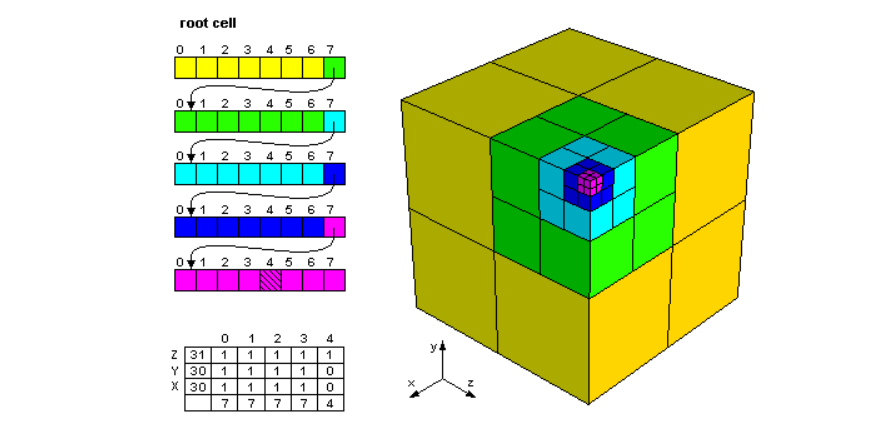
2.4.2) Nested Shape Layers
- Full 3d shape를 dense voxel grid로 전부 표현하기 보다 겉의 fine voxel에서 속 안의 보이지 않는 dense voxel을 빼고, 다시 조금 내부의 fine voxel을 더하고, 그 속을 빼고 이런 과정을 반복


2.5) 3D Shape Representations: Implicit Functions

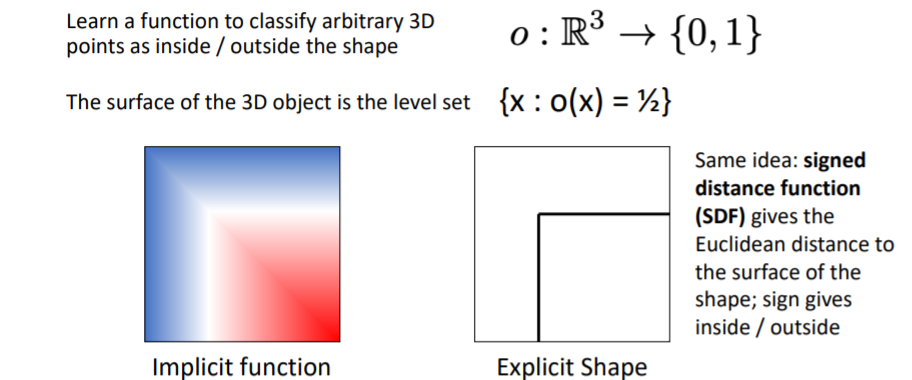
- object의 외부 표면(exterior surface)은 {x:o(x)=1/2}를 만족하는 level set(레벨 집합)이다. 즉 값이 0.5가 나오는 모든 좌표들의 집합은 표면을 나타낸다.
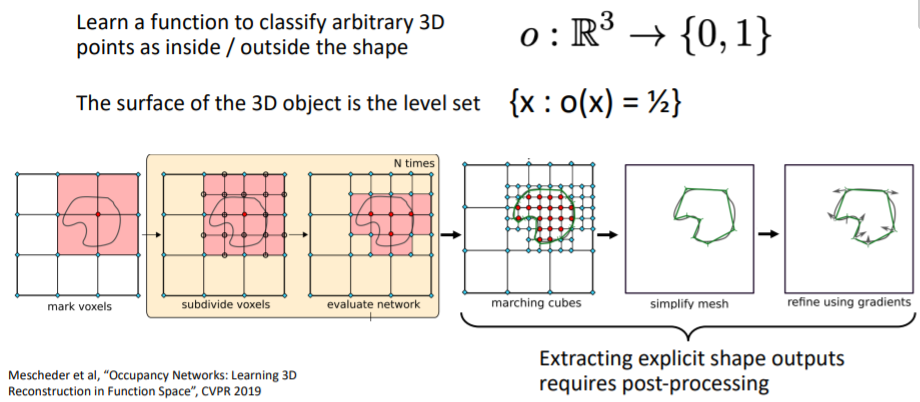
- 3d voxel grid등으로 implicit function을 학습하고 이를 explicit하게 표현하여 물체의 표면을 확인할 수 있다. ?????
2.6) 3D Shape Representations: Point Cloud
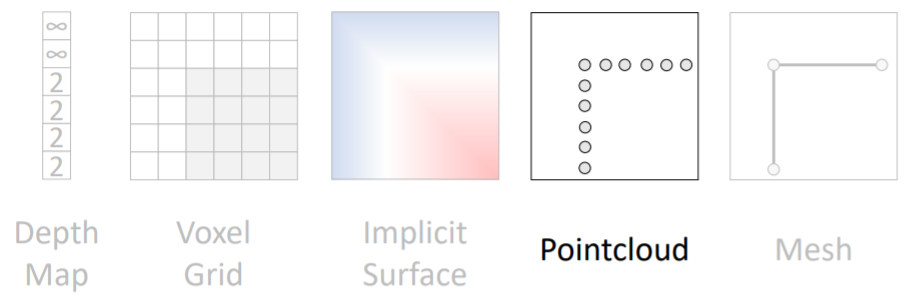

- point cloud는 voxel grid보다 좀 더 쉽게 조정이 가능하다.
- voxel grid에서 fine detail을 위해서는 high resolution이 필요했음
- 하지만 point cloud에서는 우리가 디테일을 살리고 싶은 부분에만 더 많은 points를 할당해주면 됨.
- 그러나 points는 매우 작기 때문에 point cloud를 명시적으로 나타내려면 points를 공크기로 부풀려서 렌더링 해야 함 (post-processing이 필요함)
2.6.1) Processing Pointcloud Inputs: PointNet
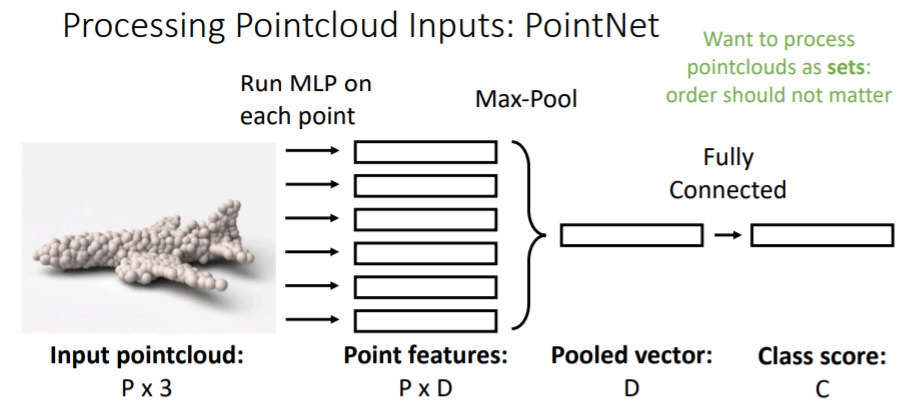
- point cloud로 된 input을 받는다(P개의 points x 3(x,y,z 좌표)). 그리고 이를 가지고 classification을 한다.
- 여기에서 흥미로운 점은 point cloud input에서 P points set은 순서가 중요하지 않음.
- (x,y,z) 좌표가 있는 각각의 point들을 독립적으로 작은 MLP에 넣는다. 즉 P개의 작은 MLP에 독립적으로 연산시킨다. 그리고 D차원의 point feature을 얻는다.
- 이들을 전부
Max pooling하여 D차원의 feature vector(pooled vector)을 만든다. 이를fc-layer에 연결하여 class score을 구한다.
- 위의 방식은 하나의 매우 간단한 연산 층을 나타낸 것이고 보통 실제로는
- pooled vector을 갖고 와서 다시 모든 point features vector과 concatenate하고 다시 작은 MLP에 독립적으로 넣고 또 여러가지 Pooling을 거치는 과정을 반복한다.
2.6.2) Generating Pointcloud Outputs

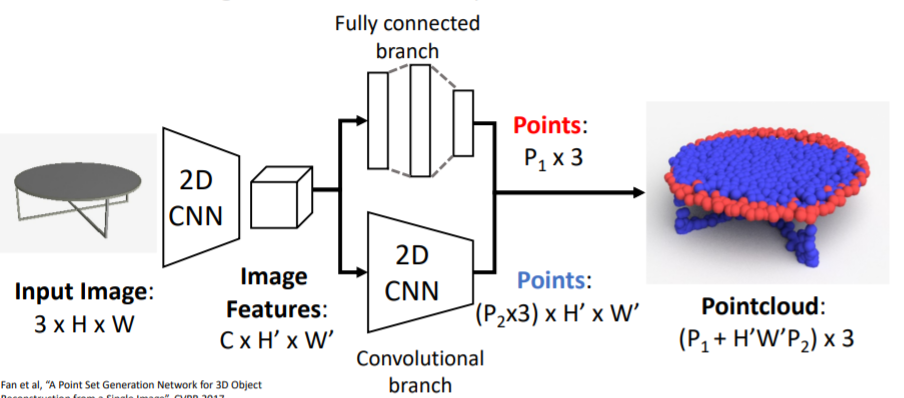
- RGB이미지를 input으로 넣어서 3d shape를 나타내는 pointcloud를 출력한다.
2.6.3) Predicting Point Clouds: Loss Function
- predicted point cloud와 GT point cloud 사이의 Loss를 계산하는 방식을 소개한다. pointclouds를 sets로 비교하고, 미분가능한 Loss가 필요하다.
- We need a (differentiable) way to compare pointclouds as sets!pointclouds를 비교할 때(S1,S2 를 비교) 보통 Chamfer distance를 사용한다.
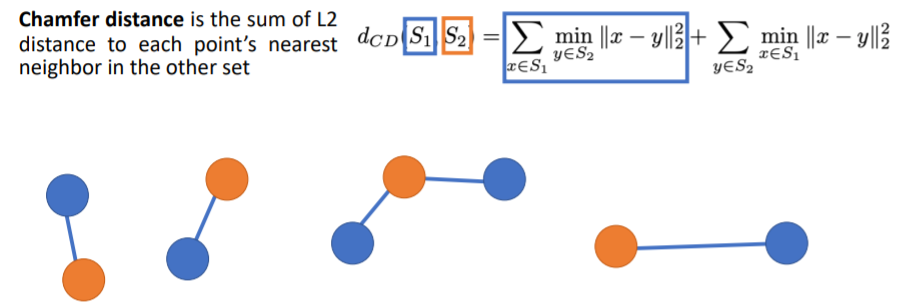
- 우선 2 sets of points를 input으로 식에 넣는다(S1,S2). (파란색, 주황색)
- chamfer distance는 이 두개의 sets of points가 얼마나 다른지를 나타내준다.
- 먼저 식에서 첫번째 term은 각 blue points 에 대해 가장 가까운 orange point (nearest neighbor orange point)를 찾아서 둘 사이의 Euclidean distance를 계산.
- 그리고 이들 거리를 모두 더하는 과정이다.
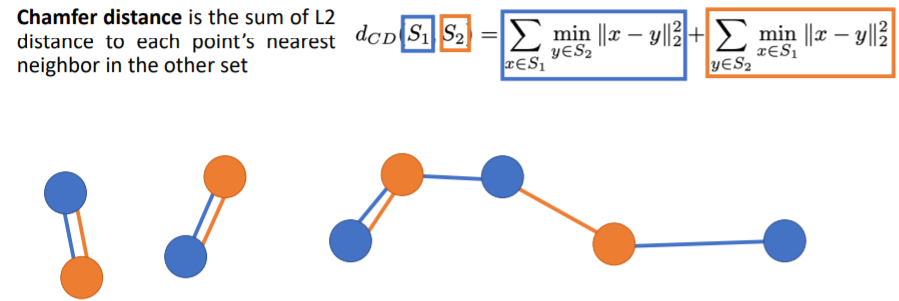
- 두번째 term은 각 orange points 에 대해 가장 가까운 blue points 를 찾아 둘 사이의 Euclidean distance를 계산하고 이들을 모두 더한다.
- 그리고 이 두 term을 더해서 최종 Loss값이 나온다.
- 이 식에서 Loss=0이 되려면 두 pointclouds가 정확히 일치해야한다(coincide perfectly).
- 각 orange points가 정확히 각 blue points위에 있어야 한다(그 반대도).
2.7) 3D Shape Representations: Triangle Mesh

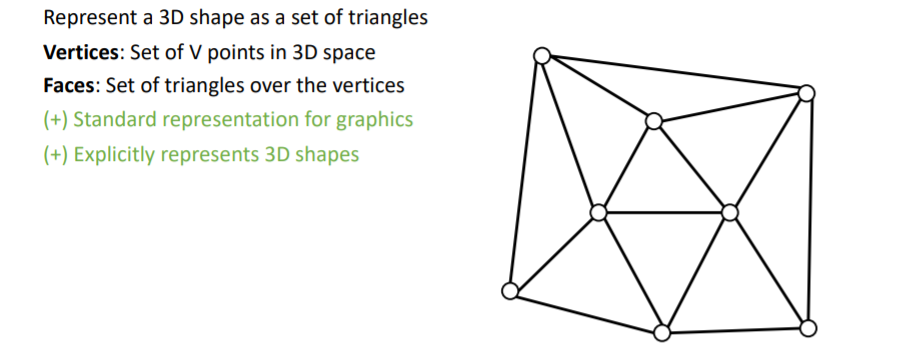
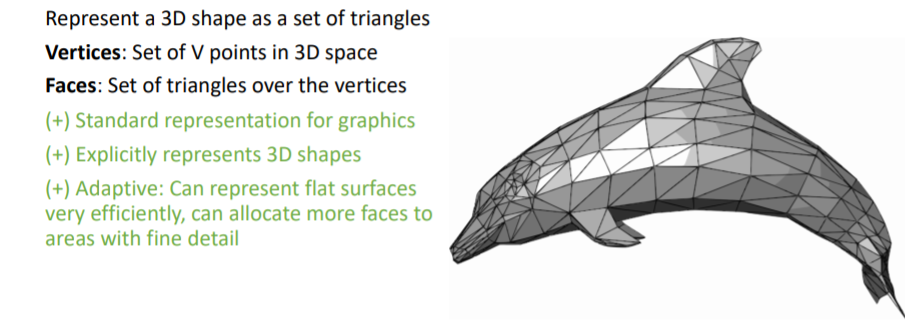
- 평평한 표면을 나타낼 때 효과적이고, 삼각형 Faces 의 크기를 조정하여 여러 detail을 표현할 수 있다.

- 또한 각 vertex 에 feature이 포함되어있는 경우
coordinate interpolation등을 사용하여 Faces (표면 전체)에 이들 정보를 넣어줄 수도 있는 장점이 있다. (위 지구 지도처럼 표면에 그림 정보들이 들었는 경우)
💢 하지만 쉽지 않다!
2.7.1) Predicting Meshes: Pixel2Mesh
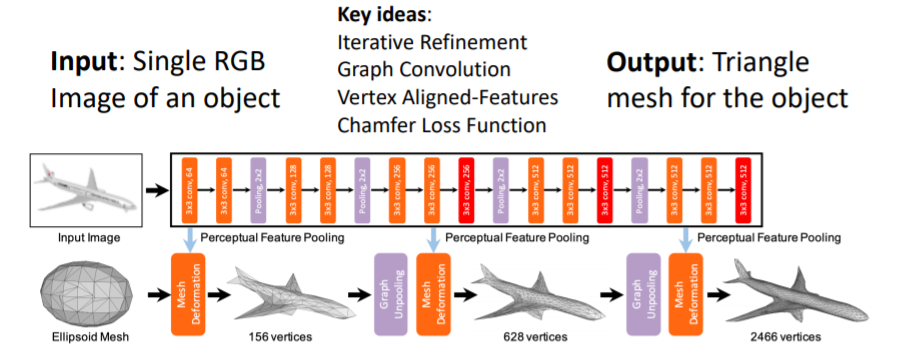
- single RGB이미지를 input으로 넣어 full 3d shape triangle mesh를 출력한다.
- 이들은 몇가지의 key ideas를 제시하였다.
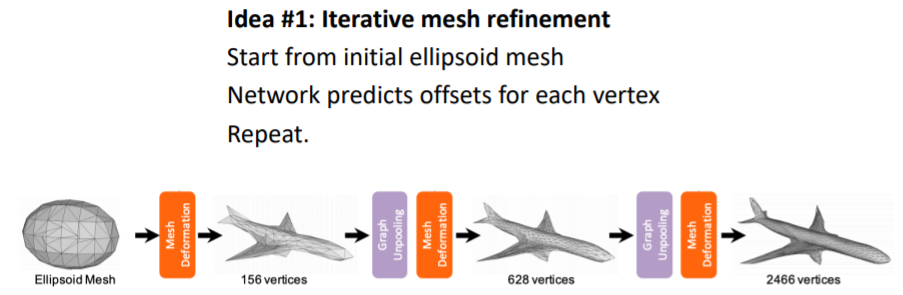
1. Predicting Triangle Meshes: Iterative Refinement (반복적으로 mesh를 미세화)
- 처음부터 디테일한 mesh를 얻기는 힘들기 때문에 처음에는 initial template mesh를 가지고 시작한다. 그리고 이를 final mesh output으로 변형한다.
- Predicting Triangle Meshes: Graph Convolution
- 우리는 mesh structured data를 operate할 수 있는 network layer이 필요하다. 이를 위해 Graph Convolution을 사용한다.
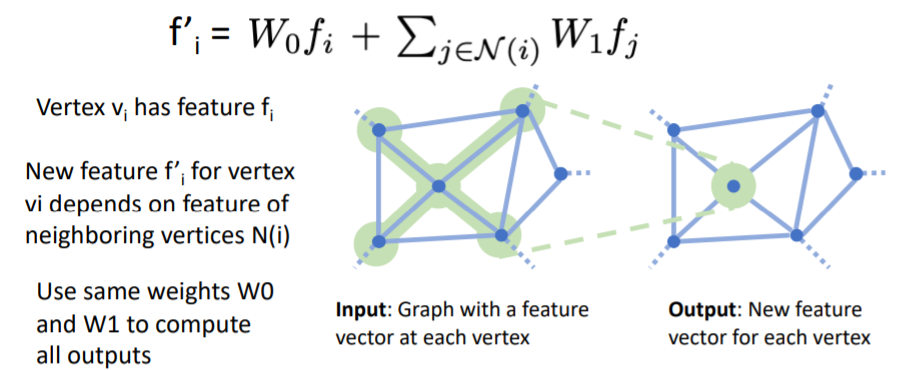
- Graph Convolution의 Input은 각 vertex에 feature vector이 포함된 Graph이고, Output은 각 vertex에 대해 새로운 feature vector을 계산한다.
- 이때 각 vertex의 새로운 feature vector은 input graph의 local receptive field의 feature vector에 의존하여 계산된다.
- i′=W0fi+j∈N(i)∑W1fj 식에서 vi vertex의 feature fi와, vi의 neighboring vertices N(i)들의 features fj에 대해 weighted sum을 하여 new feature vector fi′를 계산한다.
- 그리고 모든 vertex에 대해서 같은 함수를 적용하여 계산한다.
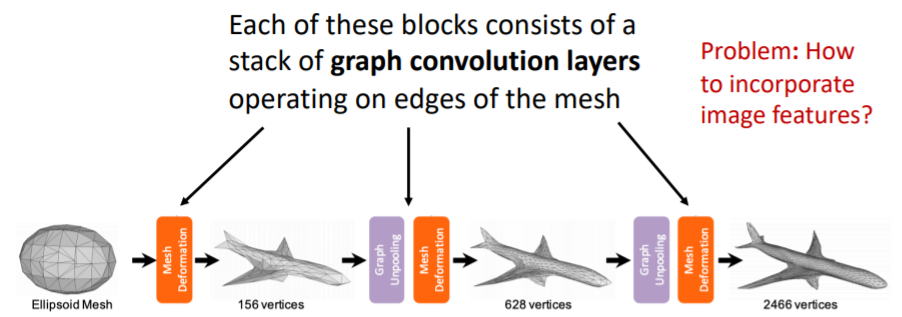
- 네트워크의 각 block들은 위의 여러 층의 graph convolution layers를 포함하고 있으며 이를 통해 coordinate features를 변형한다.
- 그런데 어떻게 RGB input 이미지와 triangle mesh를 연결지을까?
- Predicting Triangle Meshes: Vertex-Aligned Features
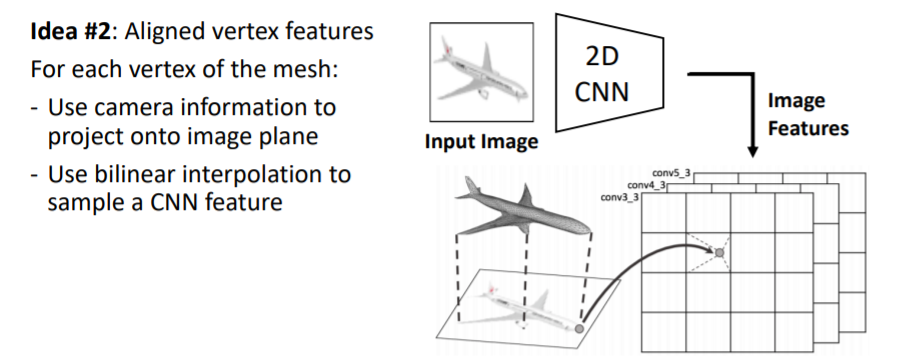
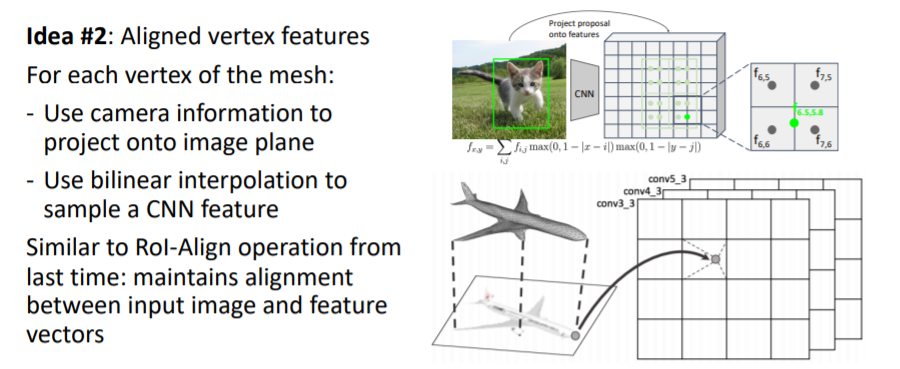
- mesh의 모든 vertex에 대해 이미지로부터 feature vector(vertex의 위치에 있는 이미지가 어떻게 보이는지에 대한visual appearance)을 가져온다.
- 이를 위해 input 이미지를 2d CNN에 넣어 2d feature map을 얻는다.
- 그리고 mesh의 verticies를 image plane에 projection시킨다(3d → 2d projection operator).
- 2d image plane에 projection된 vertices를 각각 bilinear interpolation 을 사용해서 정확한 위치에 대한 image feature vector을 가져온다.
- Predicting Meshes: Loss Function
- predict한 mesh와 Gt mesh를 비교하는데 한가지 문제점이 있다. 바로 같은 shape를 나타낼 수 있는 방법이 여러가지인 것이다.
- 예를 들어 사각형을 predict할 때 아래 그림처럼 여러 방법이 존재한다.
- 그러나 우리는 하나의 shape에 대해 하나의 방법을 원하기 때문에 아래와 같은 방법을 사용하여 비교한다.
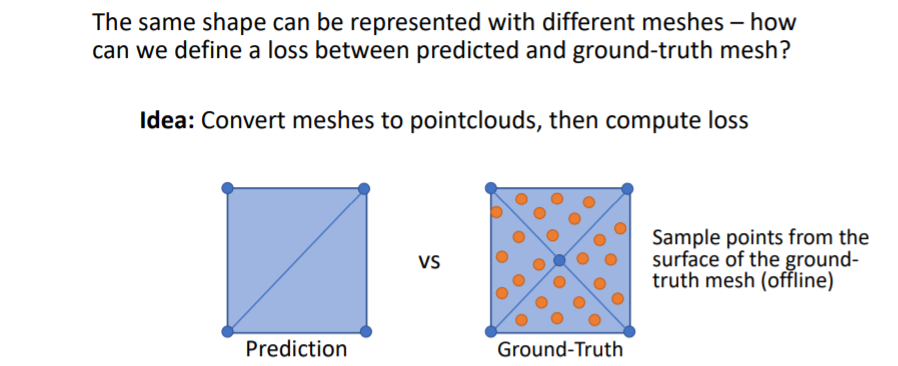
- mesh에 points를 찍어서 pointcloud로 만든다.
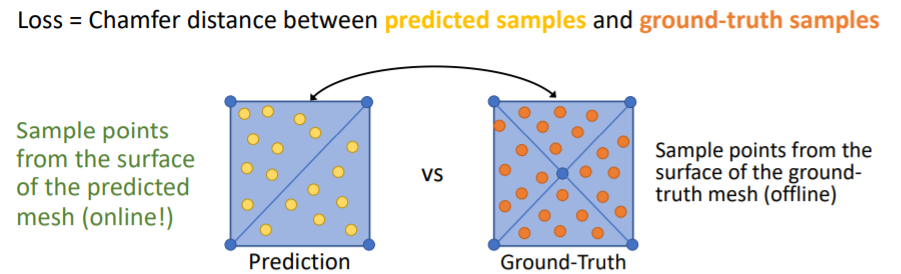
- 그리고 chamfer distance를 사용하여 이 두 point clouds를 비교한다.
- 그러나 문제가 있다.
1. Need to sample online! Must be efficient!
2. Need to backprop through sampling!
- GT mesh는 우리가 학습 이전에 offline에서 point sampling을 해줄 수 있지만 predited mesh의 points는 학습중에 online에서 sampling해야 한다.
- 따라서 이를 효율적으로 빠르게 하는 방법이 필요하고, 이들 points사이의 Loss를 사용하기 때문에 sampling에 따라 backprop이 진행된다.
3. Shape Comparison Metrics
3.1) Shape Comparison Metrics: Intersection over Union
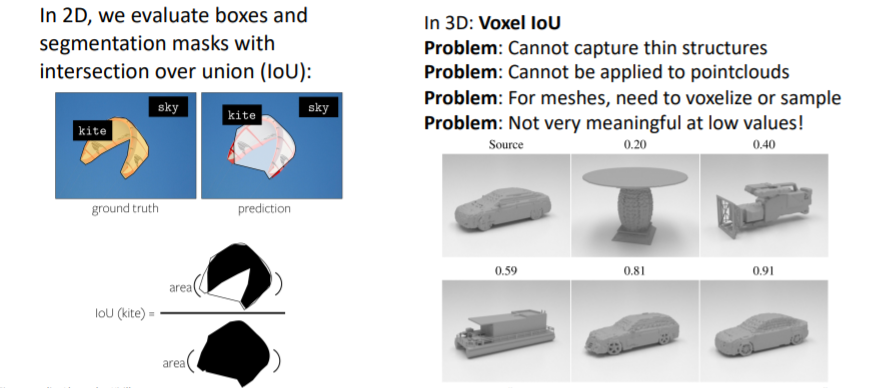
- 우리는 2D이미지를 다룰 때 IoU를 사용하여 성능을 측정하는 방법을 다루었었다.
- 그러나 3D에서는 IoU는 그다지 의미있거나 유용한 metric은 아니다.
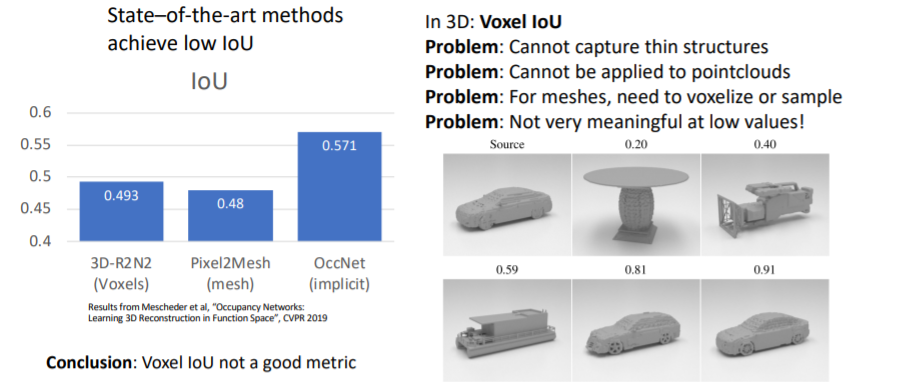
3.2) Shape Comparison Metrics: Chamfer Distance
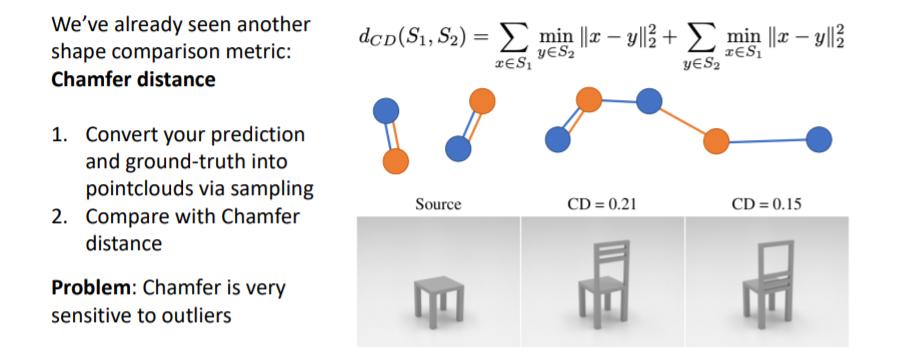
- 이전에 봤던 것처럼 서로 다른 3d shape representations에 points를 sampling하여 point clouds를 만들고 이들을 비교한다.
- 그러나 L2 distance를 사용하기 때문에 outliers에 매우 sensitive하다.
3.3) Shape Comparison Metrics: F1 Score (Best)
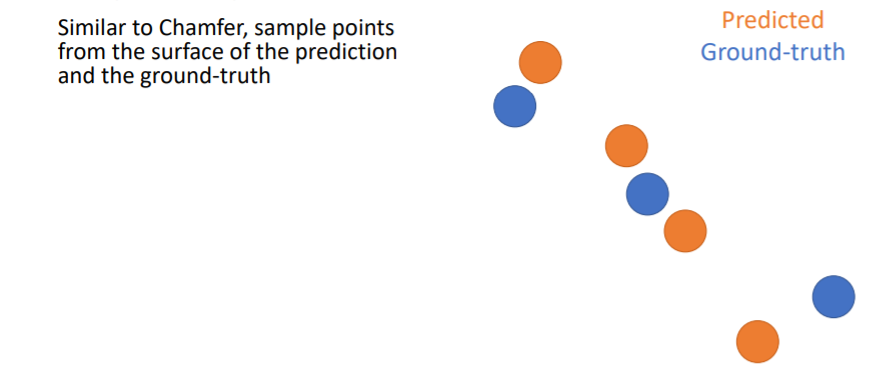
- Chamfer distance를 계산하는 것과 비슷하게 우선 prediction과 GT에서 points를 sampling한다.
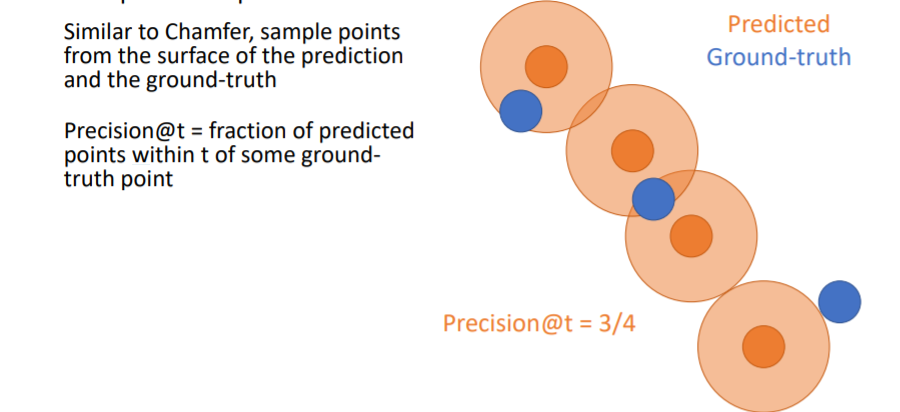
- 그리고 predicted points에 일정 크기의 원을 할당하여 만약 여기 안에 GT point가 들어온다면 그 point는 true predicted point로 설정한다.
- 위 그림에서는 4개의 predicted points중에 3개의 predicted points가 true이므로 Precision = 3/4 이다.
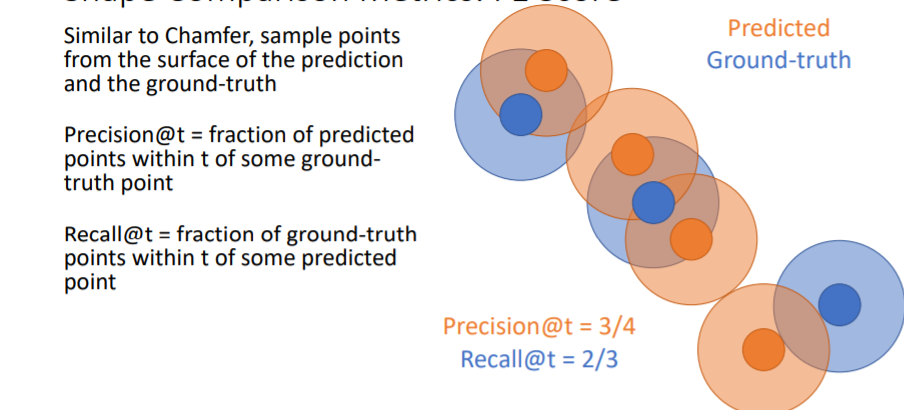
- Recall은 GT points에 일정 크기의 원을 할당하여 여기 안에 predicted point가 들어오면 true로 한다. 위 그림에서 Recall = 2/3 이다.-

- F1 score은 outliers에 robust하기 때문에 가장 좋은 metric이라고 할 수 있다.
4. Cameras
View Coordinates :카메라의 viewpoint를 기준으로 방향이 결정된다.
4.1) Cameras: Canonical vs View Coordinates
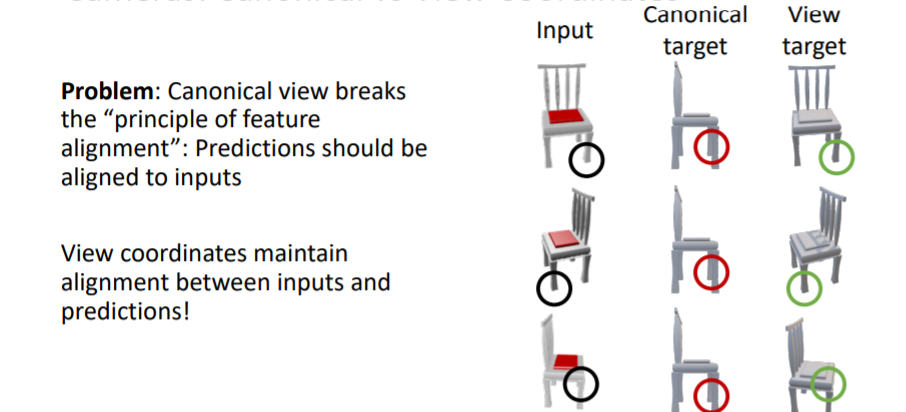
⇒ 많은 논문에서는 Coordinates 위 방식을 사용한다고 함
- 그러나 canonical coordinates는 카메라의 viewpoint와 predicted 3d shape의 방향이 서로 align되지 않는 문제가 있다.
- 대신에 view coordinates는 input과 prediction사이에 view coordinates가 유지된다는 장점 존재

- 실제로 view coordinates를 사용하여 학습시킨 결과가 더 좋은 부분이 있는 것을 확인할 수 있다. 새로운 shape이나 categories에 대해 일반화가 더욱 잘된다.
- 따라서 view coordinate system을 선호하여 사용하라고 한다.
4.2) View-Centric Voxel Predictions
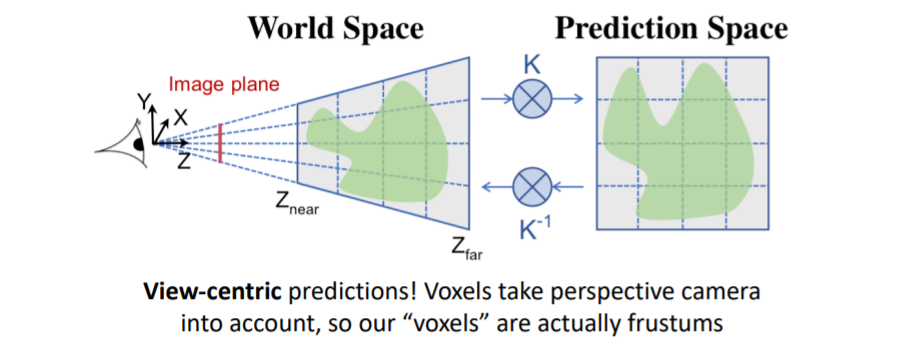
5. 3D Datasets
5.1) 3D Datasets: Object-Centric

6. 3D Shape Prediction: Mesh R-CNN
※ Mask R-CNN은 객체 검출(Object Detection)과 객체 분할(Object Segmentation)을 동시에 수행하는 딥러닝 기반의 모델로, 객체의 경계 상자를 찾고 객체 내부의 픽셀 수준에서의 분할 마스크를 생성하는 기술
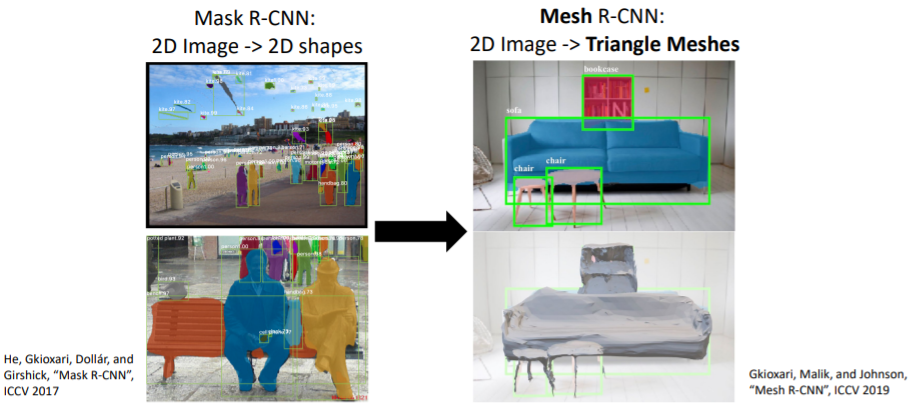
- Mask R-CNN을 기반으로 하여 Mesh head를 추가함. 여기에서 3D triangle mesh를 output으로 출력
6.1) Mesh R-CNN: Hybrid 3D shape representation
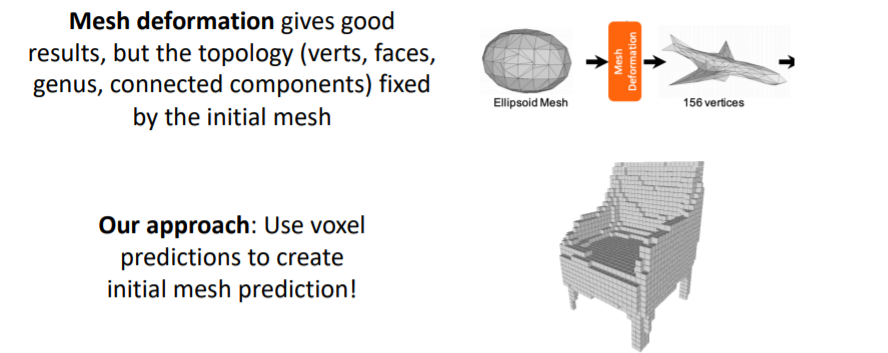
- Mesh R-CNN에서는 Hybrid 3D shape representation을 사용한다.
- 앞서 다루었던 triangle mesh의 Mesh deformation은 initial mesh의 topology(위상)에 고정되어있다는 문제가 존재함. ⇒ 변형이 어렵다는 단점 . 고정되어 있기에
- 따라서 Mesh R-CNN에서는 coarse voxel prediction을 먼저 만들고, 이를 mesh(점)로 convert시켜준다. 그리고 이를 initial mesh로 사용한다.
6.2) Mesh R-CNN Pipeline
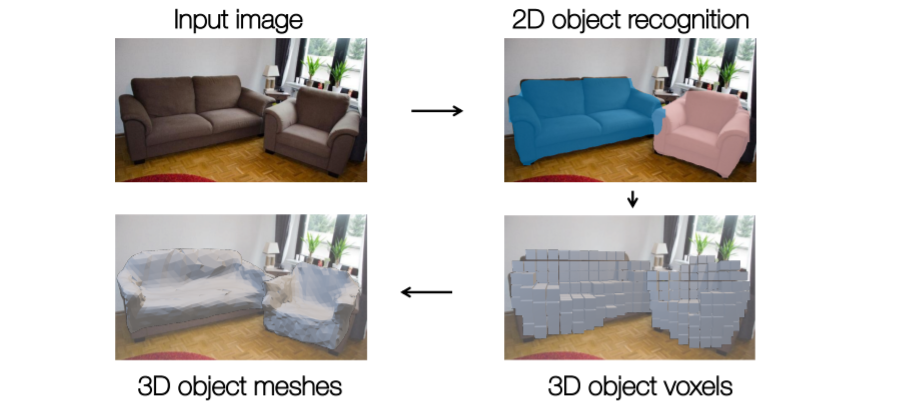
- 2D object recognition까지는 기존 mask R-CNN과 동일하다 (RPN을 사용한다던지 등..)
- 그런데 이제 여기에서 voxel tube network 를 사용하여 coarse voxel prediction을 진행한다.
- 그리고 이를 blocky mesh representation으로 convert시키고 initial mesh로 사용한다.
- 최종적으로 3d object meshes를 출력한다.
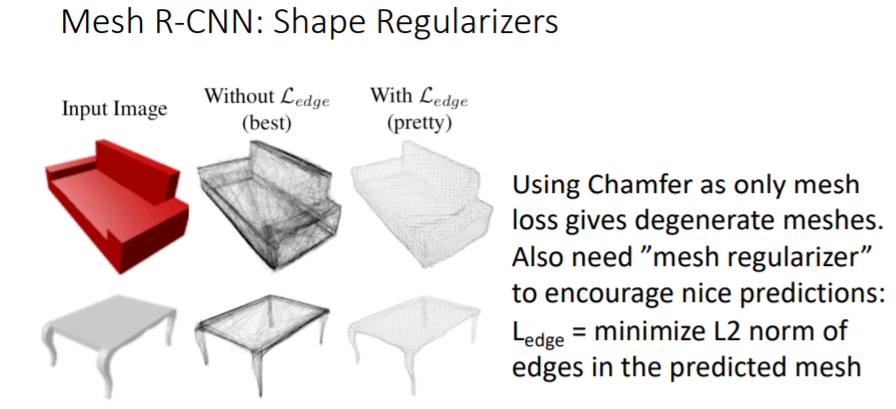
- 그리고 Chamfer Loss만 사용하지 않고 mesh regularizer을 추가로 사용하여 더 좋은 prediction결과를 얻음
6.3) Mesh R-CNN Results

- sphere로 initial mesh를 주는 Pixel2Mesh와 비교해보면 이미지의 물체에 있는 구멍을 잘 표현하는 것을 볼 수 있다. sphere로 initialize된 mesh는 위상적으로 구멍을 만들어낼 수 없다.

- 물체의 보이지 않는 뒷부분까지 mesh로 출력할 수 있다.

- object detection으로 많은 objects를 predict할 수 있지만 완벽하지는 않다.

- Amodal completion 이라는 특징을 갖는다. 위 그림처럼 개에게 가려진 소파이지만 가려진 부분도 predict가 가능하다.

- 그러나 위 그림에서 segmentation fail이 mesh prediction fail로 이어지는 것처럼 2D recognition fails가 3d recognition fail를 불러옴
정리

https://velog.io/@onground/EECS-498-007-598-005-강의정리-17강-3D-Vision#5-3d-datasets
이 분 정리된거 한줄 한줄 가져오면서 이해하였음. 정말 감사합니다.
영어 자막은 .. 못보겠음
'Deep Learning > [D&A] 2023 Conference' 카테고리의 다른 글
| [4주차] <주제 변경> 체형별 옷입히기 사전 조사 (0) | 2023.08.10 |
|---|---|
| [3주차] 건물 3D화 모델 찾기 (1) | 2023.07.28 |
| [2주차] 3D Generation Model Github 탐색 (1) | 2023.07.17 |
| [1주차] NeRF: Representing Scenes asNeural Radiance Fields for View Synthesis (0) | 2023.07.13 |



