728x90
반응형
지난 시간에 이어, 오늘은 나머지 train.py, config.py, dataset.py 파일을 구현했다.
https://www.youtube.com/watch?v=ISNdQcPhsts
이 분 코드를 바탕으로 구현하였습니다.
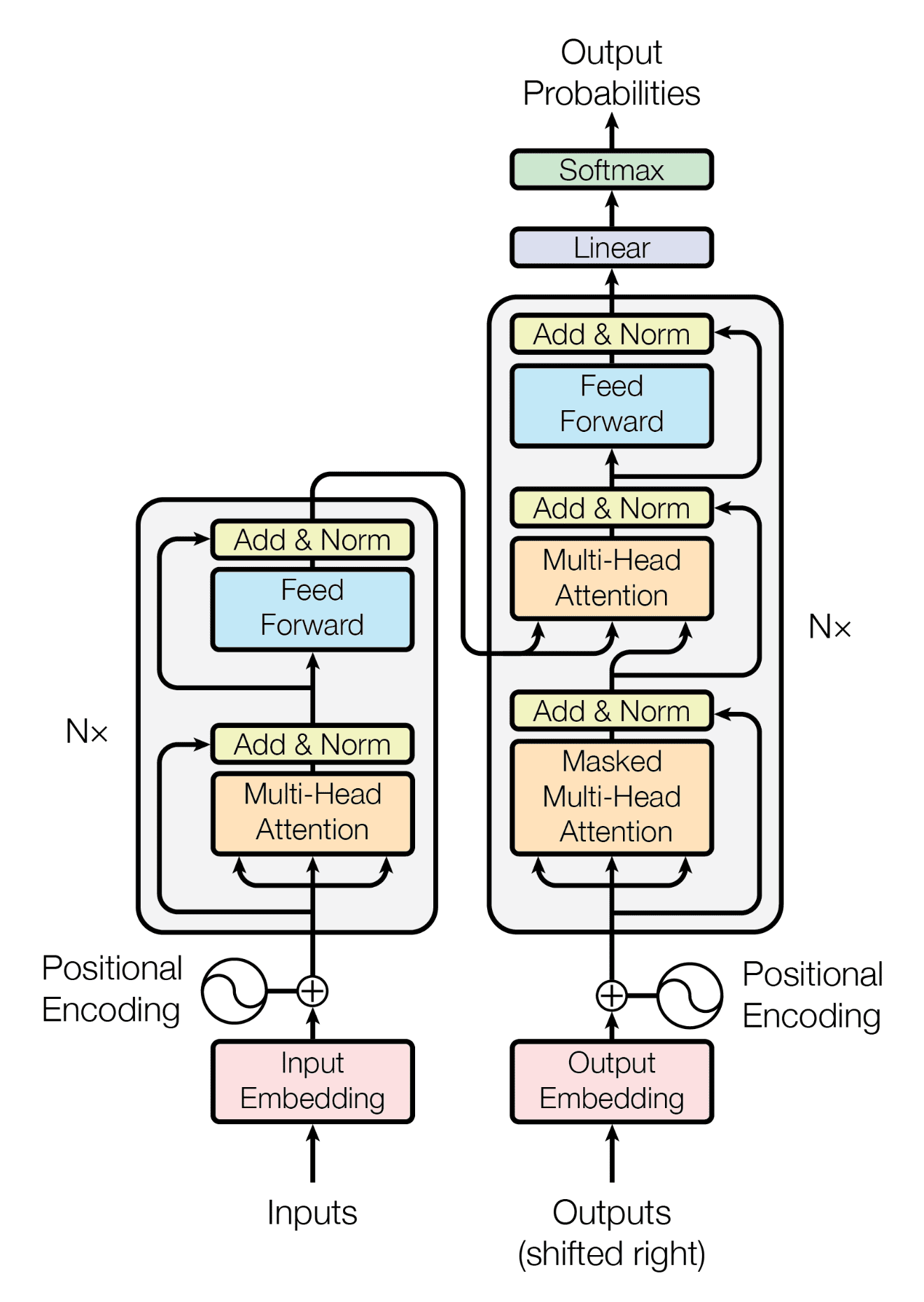
1. Dataset.py 구현
1-1. Bilingual Dataset
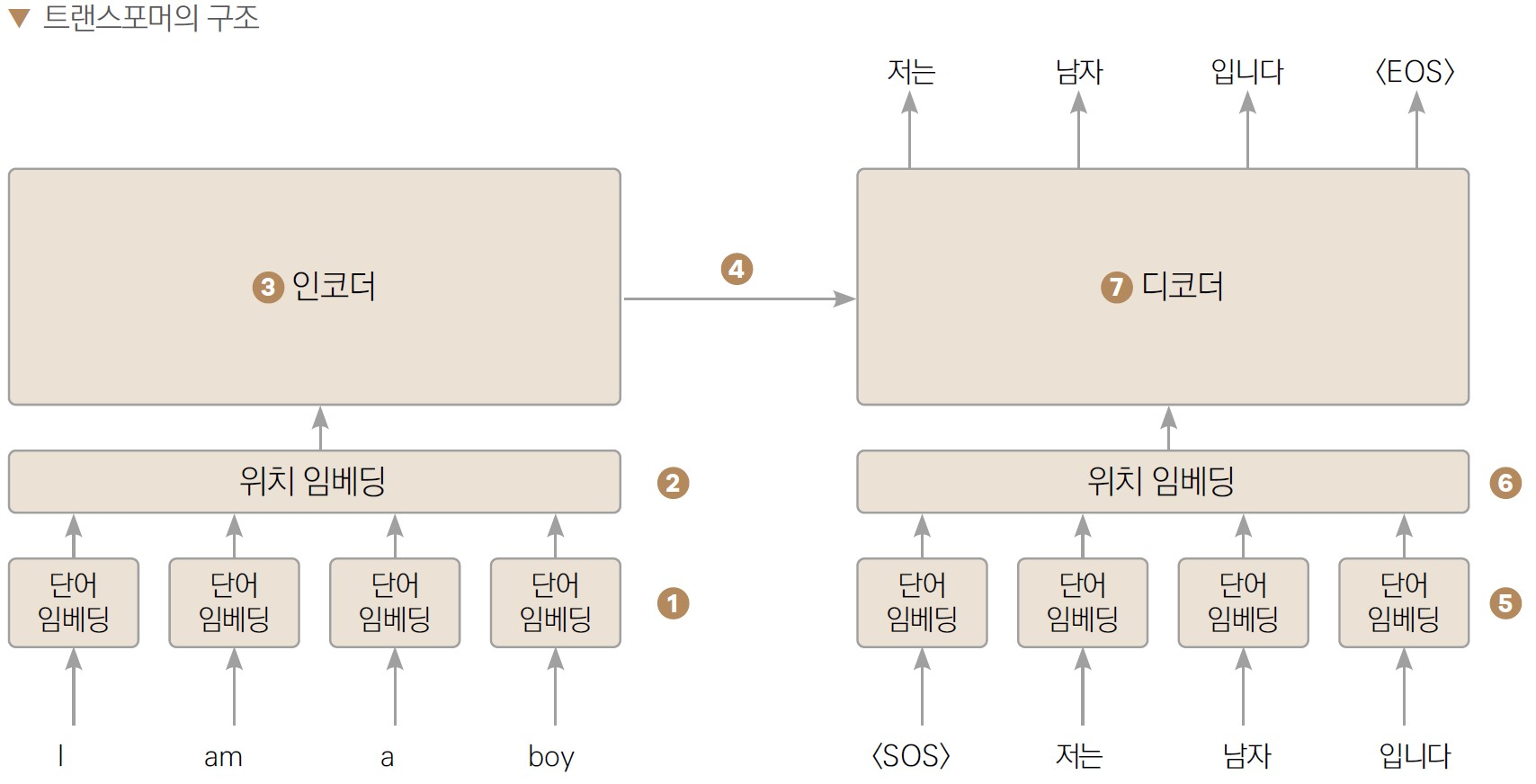
사용한 데이터셋은 Hugging Face에서 제공하는 opus_books Dataset을 활용하였다.
https://huggingface.co/datasets/opus_books/viewer/en-it
opus_books · Datasets at Hugging Face
{ "en": "Nor could I pass unnoticed the suggestion of the bleak shores of Lapland, Siberia, Spitzbergen, Nova Zembla, Iceland, Greenland, with \"the vast sweep of the Arctic Zone, and those forlorn regions of dreary space,--that reservoir of frost and snow
huggingface.co
import torch
import torch.nn as nn
from torch.utils.data import Dataset
class BilingualDataset(Dataset):
#클래스를 생성할 때 실행되는 생성자
def __init__(self, ds, tokenizer_src, tokenizer_tgt, src_lang, tgt_lang, seq_len) -> None:
super().__init__()
self.ds = ds
self.tokenizer_src = tokenizer_src
self.tokenizer_tgt = tokenizer_tgt
self.src_lang = src_lang
self.tgt_lang = tgt_lang
self.sos_token = torch.Tensor([tokenizer_src.token_to_id('[SOS]')], dtype=torch.int64)
self.eos_token = torch.Tensor([tokenizer_src.token_to_id('[EOS]')], dtype=torch.int64)
self.pad_token = torch.Tensor([tokenizer_src.token_to_id('[PAD]')], dtype=torch.int64)
#원소의 개수를 셀 때 접근되는 메서드
def __len__(self):
return len(self.ds)
#인덱스에 접근할 때 호출되는 메서드
def __getitem__(self, index : Any) -> Any:
src_target_pair = self.ds[index]
src_text = src_target_pair['translation'][self.src_lang]
tgt_text = src_target_pair['translation'][self.tgt_lang]
# 토크나이저를 사용하여 텍스트를 토큰화하고, 그 결과에서 토큰 IDs를 추출
enc_input_tokens = self.tokenizer_src.encode(src_text).ids
dec_input_tokens = self.tokenizer_tgt.encode(tgt_text).ids
#seq_len(시퀀스 길이)에 맞추기 위해 패딩을 추가해줌
#원본 언어의 입력 시퀀스에 추가해야 하는 패딩 토큰의 수
# SOS, EOS token (-2)
enc_num_padding_tokens = self.seq_len - len(enc_input_tokens) - 2
#대상 언어의 출력 시퀀스에 추가해야 하는 패딩 토큰의 수
# EOS token (-1)
dec_num_padding_tokens = self.seq_len - len(dec_input_tokens) - 1
#self.seq_len : 10
#enc_input_tokens : ["안녕", "하세요", "반갑습니다"]
#dec_input_tokens : ["Hello", "World"]
#enc_num_padding_tokens: 10 - len(["안녕", "하세요", "반갑습니다"]) - 2 = 10 - 3 - 2 = 5
#dec_num_padding_tokens: 10 - len(["Hello", "World"]) - 1 = 10 - 2 - 1 = 7
#['sos',"안녕", "하세요", "반갑습니다", 'eos',패딩, 패딩, 패딩, 패딩, 패딩]
#['Hello', 'World', 'EOS', 패딩, 패딩, 패딩, 패딩, 패딩, 패딩, 패딩]
#0보다 작을 경우, 에러 발생 ex. 10 - 9 - 2 = -1
#전체 문장 길이보다 input 문장 길이가 더 긴 경우,
if enc_num_padding_tokens < 0 or dec_num_padding_tokens < 0:
raise ValueError("Sentence is too long")
1-2. 토큰 Concat
# 토큰 Concat
# Add <s> and </s> token
encoder_input = torch.cat(
[
self.sos_token,
torch.tensor(enc_input_tokens, dtype=torch.int64),
self.eos_token,
torch.tensor([self.pad_token] * enc_num_padding_tokens, dtype=torch.int64),
],
dim=0,
)
# Add only <sos> token
decoder_input = torch.cat(
[
self.sos_token,
torch.tensor(dec_input_tokens, dtype=torch.int64),
torch.tensor([self.pad_token] * dec_num_padding_tokens, dtype=torch.int64),
],
dim=0,
)
# Add only <eos> token
label = torch.cat(
[
torch.tensor(dec_input_tokens, dtype=torch.int64),
self.eos_token,
torch.tensor([self.pad_token] * dec_num_padding_tokens, dtype=torch.int64),
],
dim=0,
)
# Double check the size of the tensors to make sure they are all seq_len long
# Asser : if 개념
# 최대 시퀀스와 input+패딩 한 결과가 동일한 길이인지를 물어봄
assert encoder_input.size(0) == self.seq_len
assert decoder_input.size(0) == self.seq_len
assert label.size(0) == self.seq_len
return {
"encoder_input": encoder_input, # (seq_len)
"decoder_input": decoder_input, # (seq_len)
#차원을 맞춰주기 위해 실행
"encoder_mask": (encoder_input != self.pad_token).unsqueeze(0).unsqueeze(0).int(), # (1, 1, seq_len)
# 현재 위치 이후의 토큰 마스크 처리 (패딩 토큰이 아닌 위치에 대해 True, 패딩 토큰인 위치에 대해 False 반환)
# -> 특정 위치에 토큰에 대한 attention을 수행할지 말지를 결정
"decoder_mask": (decoder_input != self.pad_token).unsqueeze(0).int() & causal_mask(decoder_input.size(0)), # (1, seq_len) & (1, seq_len, seq_len),
"label": label, # (seq_len) 디코더의 실제 출력에 해당하는 값
"src_text": src_text, #input text
"tgt_text": tgt_text, #target text
1-3. Mask 구현
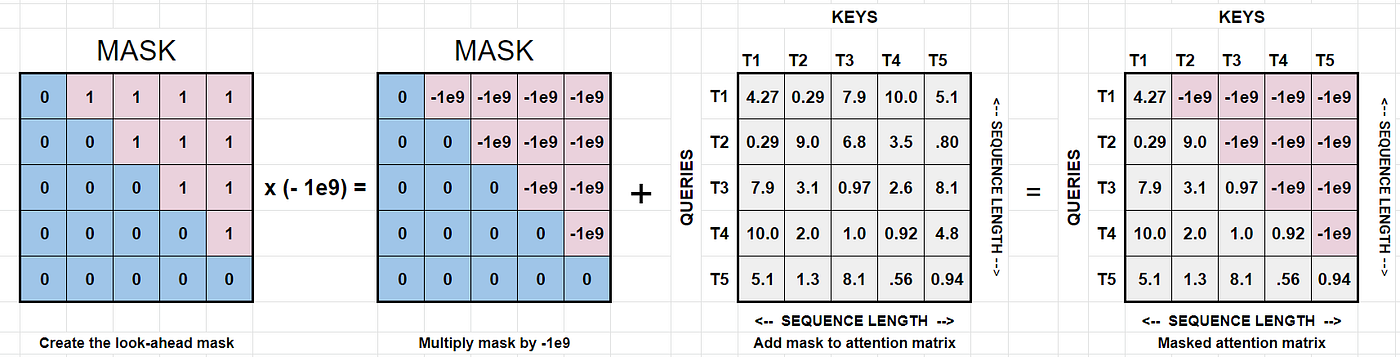

def causal_mask(size):
#https://incredible.ai/nlp/2020/02/29/Transformer/#241-padding-mask-%ED%95%B5%EC%8B%AC-%EB%82%B4%EC%9A%A9
#triu : 정사각형의 n x n 이 있을 때, 아래쪽 삼각 부분은 0으로, 위쪽 삼각 부분만 1로 리턴
mask = torch.triu(torch.ones((1, size, size)), diagonal=1).type(torch.int)
return mask == 0
2. Config.py 구현
from pathlib import Path
def get_config():
return {
"batch_size": 8,
"num_epochs": 20,
"lr": 10**-4,
"seq_len": 350,
"d_model": 512,
"datasource": 'opus_books',
"lang_src": "en",
"lang_tgt": "it",
"model_folder": "weights",
"model_basename": "tmodel_",
"preload": "latest",
"tokenizer_file": "tokenizer_{0}.json",
"experiment_name": "runs/tmodel"
}
#weight 폴더 및 이름 불러오기
def get_weights_file_path(config, epoch: str):
model_folder = f"{config['datasource']}_{config['model_folder']}"
model_filename = f"{config['model_basename']}{epoch}.pt"
return str(Path('.') / model_folder / model_filename)
# Find the latest weights file in the weights folder
def latest_weights_file_path(config):
model_folder = f"{config['datasource']}_{config['model_folder']}"
model_filename = f"{config['model_basename']}*"
weights_files = list(Path(model_folder).glob(model_filename))
if len(weights_files) == 0:
return None
#가져온 파일들을 파일의 수정 시간을 기준으로 정렬
#맨 마지막 파일이 가장 최근에 생성된 모델 가중치 파일이 됨!
weights_files.sort()
return str(weights_files[-1])
3. Train.py (+Validation)
import torch
import torch.nn. as nn
from torch.utils.data import Dataset, DataLoader, random_split
from dataset import BilingualDataset, causal_mask
from model import build_transformer
from config import get_config, get_weights_file_path, latest_weights_file_path
from datasets import load_dataset
from tokenizers import Tokenizer
from tokenizers.models import WordLevel
from tokenizers.trainers import WordLevelTrainer
from tokenizers_pre_tokenizers import Whitespace
from torch.utils.tensorboard import SummaryWriter
import warnings
from tqdm import tqdm
from pathlib import Path
#디코더에서 각 시점마다 가장 확률이 높은 단어를 선택해
#다음 시점의 입력으로 사용하는 간단한 디코딩 전략 중 하나
def greedy_decode(model, source, source_mask, tokenizer_src, tokenizer_tgt, max_len, device):
sos_idx = tokenizer_tgt.token_to_id('[SOS]')
eos_idx = tokenizer_tgt.token_to_id('[EOS]')
# Precompute the encoder output and reuse it for every step
encoder_output = model.encode(source, source_mask)
# Initialize the decoder input with the sos token
decoder_input = torch.empty(1, 1).fill_(sos_idx).type_as(source).to(device)
while True:
#디코더 입력의 길이가 max_len에 도달하면 루프를 종료
if decoder_input.size(1) == max_len:
break
# build mask for target
#현재까지 생성된 디코더 입력에 대한 어텐션 마스크를 생성
#현재 위치 이후의 토큰에 대한 어텐션을 방지
decoder_mask = causal_mask(decoder_input.size(1)).type_as(source_mask).to(device)
# calculate output
# 디코더를 사용하여 현재까지의 디코더 입력에 대한 출력을 계산
out = model.decode(encoder_output, source_mask, decoder_input, decoder_mask)
# get next token
# 디코더 출력의 마지막 토큰에 대한 확률 분포를 계산
prob = model.project(out[:, -1])
#가장 높은 확률을 다음 단어로 선정
#_, : 변수 값을 굳이 사용할 필요가 없을 때 사용
_, next_word = torch.max(prob, dim=1)
#선택된 다음 단어를 현재까지의 디코더 입력
decoder_input = torch.cat(
[decoder_input, torch.empty(1, 1).type_as(source).fill_(next_word.item()).to(device)], dim=1
)
#만약 다음 단어가 eos 토큰이면 중지
if next_word == eos_idx:
break
return decoder_input.squeeze(0)
def run_validation(model, validation_ds, tokenizer_src, tokenizer_tgt, max_len, device, print_msg, global_step, writer, num_examples=2):
model.eval()
count = 0
# source_texts = []
# expected = []
# predicted = []
#TMI
try:
# get the console window width
with os.popen('stty size', 'r') as console:
_, console_width = console.read().split()
console_width = int(console_width)
except:
# If we can't get the console width, use 80 as default
console_width = 80
#Val 진행
with torch.no_grad():
for batch in validation_ds:
count += 1
encoder_input = batch["encoder_input"].to(device) # (b, seq_len)
encoder_mask = batch["encoder_mask"].to(device) # (b, 1, 1, seq_len)
# check that the batch size is 1
assert encoder_input.size(0) == 1, "Batch size must be 1 for validation"
#Greedy Decode 적용
model_out = greedy_decode(model, encoder_input, encoder_mask, tokenizer_src, tokenizer_tgt, max_len, device)
#현재 배치에서 소스 문장과 타깃 문장을 가져옴
source_text = batch["src_text"][0]
target_text = batch["tgt_text"][0]
#모델의 출력을 디코딩하여 텍스트로 변환함
model_out_text = tokenizer_tgt.decode(model_out.detach().cpu().numpy())
# #각각 소스 문장, 타깃 문장, 모델의 예측 결과를 리스트에 추가
# source_texts.append(source_text)
# expected.append(target_text)
# predicted.append(model_out_text)
# Print the source, target and model output
print_msg('-'*console_width)
#우측 정렬
print_msg(f"{f'SOURCE: ':>12}{source_text}")
print_msg(f"{f'TARGET: ':>12}{target_text}")
print_msg(f"{f'PREDICTED: ':>12}{model_out_text}")
#지정된 예제 수만큼 출력하면 종료
if count == num_examples:
print_msg('-'*console_width)
break
# if writer:
# # Evaluate the character error rate
# # Compute the char error rate
# metric = torchmetrics.CharErrorRate()
# cer = metric(predicted, expected)
# writer.add_scalar('validation cer', cer, global_step)
# writer.flush()
# # Compute the word error rate
# metric = torchmetrics.WordErrorRate()
# wer = metric(predicted, expected)
# writer.add_scalar('validation wer', wer, global_step)
# writer.flush()
# # Compute the BLEU metric
# metric = torchmetrics.BLEUScore()
# bleu = metric(predicted, expected)
# writer.add_scalar('validation BLEU', bleu, global_step)
# writer.flush()
#모든 문장 가져오기
def get_all_sentences(ds,lang):
for item in ds:
#yield : 반복될 때마다 하나의 값을 생성 <-> 기존 def는 단일 결과물만 반환
yield item['translation'][lang]
#토크나이저 가져오거나 새로 생성
def get_or_build_tokenizer(config, ds, lang): #datasets, langauage
# config['tokenizer_file] = '../tokenizers/tokenizer_{0}.json
tokenizer_path = Path(config['tokenizer_file'].format(lang))
#HuggingFace 라이브러리
if not Path.exists(tokenizer_path):
tokenizer = Tokenizer(WordLevel(unk_token='[UNK]'))
tokenizer.pre_tokenizer = Whitespace() #공백을 기준으로 분리
#WordLevelTrainer : 학습 및 추론(단어 토큰을 학습하는데 사용되는 메서드)
trainer = WordLevelTrainer(special_tokens=['[UNK]', '[PAD]','[SOS]','[EOS]'])
tokenizer.train_from_iterator(get_all_sentences(ds,lang),trainer=trainer)
tokenizer.save(str(tokenizer_path))
else:
tokenizer = Tokenizer.from_file(str(tokenizer_path))
return tokenizer
#train, val data로 나누는 함수
def get_ds(config):
ds_raw = load_dataset('opus_books',f'{config['lang_src']}-{config['lang_tgt']}',split='train')
#Build Tokenizers
tokenizer_src = get_or_build_tokenizer(config, ds_raw, config=['lang_src'])
tokenizer_tgt = get_or_build_tokenizer(config, ds_raw, config=['lang_src'])
#Keep 90% for training and 10% for validation
train_ds_size = int(0.9+len(ds_raw))
val_ds_size = len(ds_raw) - train_ds_size
train_ds_raw, val_ds_raw = random_split(ds_raw,[train_ds_size, val_ds_size])
#Dataset class 적용
train_ds = BilingualDataset(train_ds_raw, tokenizer_src, tokenizer_tgt, config['lang_src'], config['lang_tgt'], config['seq_len'])
val_ds = BilingualDataset(val_ds_raw, tokenizer_src, tokenizer_tgt, config['lang_src'], config['lang_tgt'], config['seq_len'])
# Find the maximum length of each sentence in the source and target sentence
# max seq length 찾기
max_len_src = 0
max_len_tgt = 0
for item in ds_raw:
src_ids = tokenizer_src.encode(item['translation'][config['lang_src']]).ids
tgt_ids = tokenizer_tgt.encode(item['translation'][config['lang_tgt']]).ids
max_len_src = max(max_len_src, len(src_ids))
max_len_tgt = max(max_len_tgt, len(tgt_ids))
print(f'Max length of source sentence: {max_len_src}')
print(f'Max length of target sentence: {max_len_tgt}')
#Data 불러오기
train_dataloader = DataLoader(train_ds, batch_size=config['batch_size'], shuffle=True)
val_dataloader = DataLoader(val_ds, batch_size=1, shuffle=True)
return train_dataloader, val_dataloader, tokenizer_src, tokenizer_tgt
#모델 불러오기
def get_model(config, vocab_src_len, vocab_tgt_len):
model = build_transformer(vocab_src_len, vocab_tgt_len, config["seq_len"], config['seq_len'], d_model=config['d_model'])
return model
#Train 함수
def train_model(config):
# Define the device
device = "cuda" if torch.cuda.is_available() else "mps" if torch.has_mps or torch.backends.mps.is_available() else "cpu"
print("Using device:", device)
if (device == 'cuda'):
print(f"Device name: {torch.cuda.get_device_name(device.index)}")
print(f"Device memory: {torch.cuda.get_device_properties(device.index).total_memory / 1024 ** 3} GB")
elif (device == 'mps'):
print(f"Device name: <mps>")
else:
print("NOTE: If you have a GPU, consider using it for training.")
print(" On a Windows machine with NVidia GPU, check this video: https://www.youtube.com/watch?v=GMSjDTU8Zlc")
print(" On a Mac machine, run: pip3 install --pre torch torchvision torchaudio torchtext --index-url https://download.pytorch.org/whl/nightly/cpu")
device = torch.device(device)
# Make sure the weights folder exists
Path(f"{config['datasource']}_{config['model_folder']}").mkdir(parents=True, exist_ok=True)
train_dataloader, val_dataloader, tokenizer_src, tokenizer_tgt = get_ds(config)
#모델 적용
model = get_model(config, tokenizer_src.get_vocab_size(), tokenizer_tgt.get_vocab_size()).to(device)
# Tensorboard
writer = SummaryWriter(config['experiment_name'])
#Adam optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=config['lr'], eps=1e-9)
# If the user specified a model to preload before training, load it
initial_epoch = 0
global_step = 0
preload = config['preload']
model_filename = latest_weights_file_path(config) if preload == 'latest' else get_weights_file_path(config, preload) if preload else None
if model_filename:
print(f'Preloading model {model_filename}')
state = torch.load(model_filename)
model.load_state_dict(state['model_state_dict'])
initial_epoch = state['epoch'] + 1
optimizer.load_state_dict(state['optimizer_state_dict'])
global_step = state['global_step']
else:
print('No model to preload, starting from scratch')
#cross Entropy 사용
loss_fn = nn.CrossEntropyLoss(ignore_index=tokenizer_src.token_to_id('[PAD]'), label_smoothing=0.1).to(device)
for epoch in range(initial_epoch, config['num_epochs']):
torch.cuda.empty_cache()
model.train()
batch_iterator = tqdm(train_dataloader, desc=f"Processing Epoch {epoch:02d}")
for batch in batch_iterator:
#model.train()
encoder_input = batch['encoder_input'].to(device) # (B, seq_len)
decoder_input = batch['decoder_input'].to(device) # (B, seq_len)
encoder_mask = batch['encoder_mask'].to(device) # (B, 1, 1, seq_len)
decoder_mask = batch['decoder_mask'].to(device) # (B, 1, seq_len, seq_len)
# Run the tensors through the encoder, decoder and the projection layer
encoder_output = model.encode(encoder_input, encoder_mask) # (B, seq_len, d_model)
decoder_output = model.decode(encoder_output, encoder_mask, decoder_input, decoder_mask) # (B, seq_len, d_model)
proj_output = model.project(decoder_output) # (B, seq_len, vocab_size)
# Compare the output with the label
label = batch['label'].to(device) # (B, seq_len)
# Compute the loss using a simple cross entropy
loss = loss_fn(proj_output.view(-1, tokenizer_tgt.get_vocab_size()), label.view(-1))
batch_iterator.set_postfix({"loss": f"{loss.item():6.3f}"})
# Log the loss (Tensorboard 사용할 때)
writer.add_scalar('train loss', loss.item(), global_step)
writer.flush()
# Backpropagate the loss
loss.backward()
# Update the weights
optimizer.step()
optimizer.zero_grad(set_to_none=True)
#run_validation
global_step += 1
# Run validation at the end of every epoch
run_validation(model, val_dataloader, tokenizer_src, tokenizer_tgt, config['seq_len'], device, lambda msg: batch_iterator.write(msg), global_step, writer)
# Save the model at the end of every epoch
# 에폭마다 저장
model_filename = get_weights_file_path(config, f"{epoch:02d}")
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'global_step': global_step
}, model_filename)
if __name__ == '__main__':
warnings.filterwarnings("ignore")
config = get_config() #지정한 하이퍼파라미터값 적용
train_model(config)
실험 결과는 추후 올릴 예정.

728x90
반응형
'Deep Learning > [코드 구현] DL Architecture 구현' 카테고리의 다른 글
| [Transformer] 아키텍처 구현하기 - 1 (Pytorch) (1) | 2024.02.17 |
|---|---|
| [UNet] copy and crop 코드 구현 및 아키텍처 구현하기 (Pytorch) (1) | 2024.02.08 |

