0. Abstract
최근 연구들은 영어 자연어 이해에 대한 생성 사전 훈련의 효율성을 입증하였습니다. 본 연구에서는 이 접근법을 다국어로 확장하여 교차 언어 사전 훈련의 효과를 보여줍니다. 우리는 교차 언어 언어 모델 (XLM)을 학습하기 위해 두 가지 방법을 제안합니다. 하나는 단일 언어 데이터에만 의존하는 비지도 학습 방법이고, 다른 하나는 병렬 데이터를 활용하는 감독 학습 방법입니다. 우리는 교차 언어 분류, 비지도 및 감독 기계 번역에서 최고 수준의 결과를 얻었습니다. XNLI에서 우리의 접근법은 4.9%의 절대적인 정확도 향상을 이끌어냈습니다. 비지도 기계 번역에서는 WMT'16 독일어-영어에서 34.3 BLEU를 달성하여 이전 최고 수준보다 9 BLEU 이상 향상되었습니다. 감독 기계 번역에서는 WMT'16 루마니아어-영어에서 38.5 BLEU의 새로운 최고 수준을 달성하여 이전 최상의 접근법보다 4 BLEU 이상 우수한 성과를 보였습니다. 우리의 코드와 사전 훈련된 모델은 공개적으로 제공될 예정입니다.
1. Introduction
문장 인코더의 생성적 사전 훈련(Radford et al., 2018; Howard and Ruder, 2018; Devlin et al., 2018)은 많은 자연어 이해 벤치마크(Wang et al., 2018)에서 강력한 성능 향상을 이끌어냈습니다. 이 문맥에서, 대규모 비지도 텍스트 코퍼스에서 Transformer(Vaswani et al., 2017) 언어 모델을 학습한 후, 분류(Socher et al., 2013)나 자연어 추론(Bowman et al., 2015; Williams et al., 2017)과 같은 자연어 이해(NLU) 작업에 대해 미세 조정(fine-tuning)을 수행합니다. 일반적인 문장 표현 학습에 대한 관심이 급증하였지만, 이 분야의 연구는 본질적으로 단일 언어에 초점을 맞추고, 주로 영어 벤치마크를 중심으로 이루어졌습니다(Conneau and Kiela, 2018; Wang et al., 2018).
많은 언어에서 교차-언어 문장 표현을 학습하고 평가하는 최근 연구 개발(Conneau et al., 2018b)은 영어 중심적 편향을 완화하고 어떤 문장이든 공유된 임베딩 공간으로 인코딩할 수 있는 범용 교차-언어 인코더를 구축할 수 있는 가능성을 제시합니다.
본 논문에서 우리는 교차-언어 언어 모델 사전 훈련의 효과를 다국어 교차-언어 이해(XLU) 벤치마크에서 입증합니다. 구체적으로 다음과 같은 기여를 합니다:
- 교차-언어 언어 모델링을 사용한 교차-언어 표현 학습을 위한 새로운 비지도 학습 방법을 제안하고, 두 가지 단일 언어 사전 훈련 목적을 조사합니다.
- 병렬 데이터가 있는 경우 교차-언어 사전 훈련을 개선하는 새로운 감독 학습 목적을 제안합니다.
- 교차-언어 분류, 비지도 기계 번역 및 감독 기계 번역에서 이전 최고 성능을 크게 능가합니다.
- 교차-언어 언어 모델이 저자원 언어의 난해함(perplexity)에 상당한 개선을 제공하는 것을 보여줍니다.
- 우리는 코드와 사전 훈련된 모델을 공개적으로 제공할 예정입니다.
2. Related Work
우리의 연구는 Radford et al. (2018), Howard and Ruder (2018), Devlin et al. (2018)의 연구를 기반으로 합니다. 이들 연구는 Transformer 인코더 사전 훈련을 위한 언어 모델링을 조사하였습니다. 이들의 접근 방식은 GLUE 벤치마크(Wang et al., 2018)의 여러 분류 작업에서 급격한 성능 향상을 이끌어냈습니다. Ramachandran et al. (2016)은 언어 모델 사전 훈련이 기계 번역 작업에서도 상당한 성능 향상을 제공할 수 있다는 것을 보여주었습니다. 심지어 영어-독일어와 같은 고자원 언어 쌍에서도 상당한 양의 병렬 데이터가 존재하는 경우에도 성능 향상을 이룰 수 있었습니다. 우리의 연구와 동시에, 교차-언어 언어 모델링 접근법을 사용한 교차-언어 분류 결과가 BERT 저장소에서 소개되었습니다. 우리는 이러한 결과를 섹션 5에서 우리의 접근법과 비교합니다.
텍스트 표현의 분포를 맞추는 작업은 단어 임베딩의 분포 맞춤과 함께 오랜 전통이 있습니다. Mikolov et al. (2013a)의 작업부터 작은 사전을 활용하여 서로 다른 언어의 단어 표현을 맞추는 작업을 시작으로 많은 후속 연구들이 교차-언어 표현을 활용하여 단일 언어 표현의 품질을 향상시킬 수 있음을 보였습니다(Faruqui and Dyer, 2014; Xing et al., 2015; Ammar et al., 2016). 이러한 연구들을 따라 교차-언어 감독 필요성은 점점 감소되었고(Conneau et al., 2018a), 최종적으로 완전히 제거되었습니다(Smith et al., 2017; Conneau et al., 2018a). 본 연구에서는 이러한 아이디어를 한 단계 더 나아가 문장의 분포를 맞추는 작업을 통해 교차-언어 언어 모델을 구축하고 또한 병렬 데이터의 필요성을 줄이는 방향으로 연구를 진행합니다.
다국어에서 문장 표현을 맞추는 작업에 관한 다양한 연구가 있습니다. Hermann and Blunsom (2014), Conneau et al. (2018b), Eriguchi et al. (2018)는 병렬 데이터를 사용하여 교차-언어 문장 분류 작업을 조사하였습니다. 그러나 가장 성공적인 최근 교차-언어 인코더 접근법은 아마도 Johnson et al. (2017)의 다국어 기계 번역 연구입니다. 그들은 하나의 공유 LSTM 인코더와 디코더를 사용하여 많은 언어 쌍에 대한 기계 번역을 수행할 수 있는 단일 시퀀스-투-시퀀스 모델을 제시하였습니다. 그들의 다국어 모델은 저차원 언어 쌍에서 최첨단 성능을 발휘하고 제로샷 번역을 가능하게 하였습니다. 이 접근법을 따라서 Artetxe and Schwenk (2018)는 이러한 인코더를 활용하여 교차-언어 문장 임베딩을 생성할 수 있음을 보였습니다. 그들의 접근법은 2억개 이상의 병렬 문장을 활용하였으며, 고정된 문장 표현 위에 분류기를 학습하여 XNLI 교차-언어 분류 벤치마크에서 최신 성능을 달성하였습니다. 이러한 방법들은 상당량의 병렬 데이터가 필요하지만, 최근 우리의 연구와 가장 유사한 연구는 아마도 Wada와 Iwata (2018)의 연구입니다. 그들은 서로 다른 언어의 문장으로 LSTM (Hochreiter와 Schmidhuber, 1997) 언어 모델을 훈련시켰습니다. 그들은 LSTM 매개변수를 공유하지만 각 언어의 단어를 나타내는 데에는 다른 룩업 테이블을 사용합니다. 그들은 단어 번역 작업에서 그들의 접근법이 잘 작동하는 것을 보였습니다.
3. Cross-lingual language models
이 섹션에서는 우리가 이 연구를 통해 고려한 세 가지 언어 모델링 목적을 설명합니다. 그 중 두 가지는 단일 언어 데이터만을 사용하는 비지도 학습 방식이며, 나머지 한 가지는 병렬 문장을 필요로 하는 감독 학습 방식입니다. 우리는 N개의 언어를 고려합니다. 다른 언급이 없는 한, 우리는 N개의 단일 언어 말뭉치 {Ci}i=1...N를 가지고 있다고 가정하며, ni를 Ci의 문장 수로 나타냅니다.
3.1 Shared sub-word vocabulary
우리의 모든 실험에서 우리는 Byte Pair Encoding (BPE) (Sennrich et al., 2015)을 통해 생성된 동일한 공유 어휘로 모든 언어를 처리합니다. Lample et al. (2018a)에서 보여진 대로, 이는 동일한 알파벳이나 숫자 (Smith et al., 2017) 또는 고유명사와 같은 앵커 토큰을 공유하는 언어 간 임베딩 공간의 정렬을 크게 개선시킵니다. 우리는 단일 언어 말뭉치에서 임의로 샘플링한 문장의 연결에서 BPE 분할을 학습합니다. 문장은 다음과 같은 다항 분포에 따라 샘플링됩니다. {qi}i=1...N에서 확률은 다음과 같습니다.

우리는 α = 0.5로 설정합니다. 이 분포로 샘플링하는 것은 저자원 언어와 관련된 토큰의 수를 늘리고, 고자원 언어에 대한 편향을 완화하기 위한 것입니다. 특히, 이는 저자원 언어의 단어가 문자 수준에서 분할되는 것을 방지합니다.
3.2 Causal Language Modeling (CLM)
우리의 인과 언어 모델링 (CLM) 작업은 문장 내 이전 단어들을 기반으로 현재 단어의 확률을 모델링하는 Transformer 언어 모델을 훈련시키는 것입니다. 이전의 순환 신경망은 언어 모델링 벤치마크에서 최첨단 성능을 달성했습니다(Mikolov et al., 2010; Jozefowicz et al., 2016), 그러나 Transformer 모델도 매우 경쟁력이 있습니다(Dai et al., 2019).
LSTM 언어 모델의 경우, 시간에 걸친 역전파 (Werbos, 1990) (BPTT)는 LSTM에 이전 반복의 마지막 숨겨진 상태를 제공함으로써 수행됩니다. Transformer의 경우, 이전 숨겨진 상태를 현재 배치로 전달함으로써 현재 배치의 첫 단어에 문맥을 제공할 수 있습니다(Al-Rfou et al., 2018). 그러나 이 기술은 교차-언어 설정에 확장되지 않으므로 간단함을 위해 각 배치의 첫 단어에는 문맥을 제공하지 않습니다.
3.3 Masked Language Modeling (MLM)
우리는 또한 Devlin et al. (2018)의 가려진 언어 모델링 (MLM) 목적, 즉 클로즈 태스크 (Taylor, 1953)를 고려합니다. Devlin et al. (2018)을 따라, 우리는 텍스트 스트림에서 BPE 토큰의 15%를 임의로 샘플링하고, 80%의 경우 [MASK] 토큰으로 대체하고, 10%의 경우 임의의 토큰으로 대체하며, 10%의 경우 변경하지 않습니다. 우리의 접근 방식과 Devlin et al. (2018)의 MLM과의 차이점은 문장 쌍 대신 임의의 수의 문장 (256 토큰으로 제한)의 텍스트 스트림을 사용한다는 것입니다. 드물고 빈번한 토큰 사이의 불균형을 해결하기 위해, 우리는 Mikolov et al. (2013b)와 유사한 접근 방식을 사용하여 빈도의 제곱근에 반비례하는 가중치를 가진 다항 분포에 따라 텍스트 스트림의 토큰을 샘플링합니다. 우리의 MLM 목적은 그림 1에서 설명되어 있습니다.
3.4 Translation Language Modeling (TLM)
CLM과 MLM 목표는 비지도 학습이며, 단일 언어 데이터만 사용할 수 있습니다. 그러나 이러한 목표는 병렬 데이터를 활용할 수 없습니다. 우리는 번역 언어 모델링(TLM) 목표를 도입하여 크로스-언어 사전 훈련을 개선합니다. TLM 목표는 MLM의 확장으로, 단일 언어 텍스트 스트림 대신에 병렬 문장을 연결하여 사용합니다. 소스 문장과 대상 문장 모두에서 무작위로 단어를 마스킹합니다. 영어 문장에서 마스킹된 단어를 예측하기 위해 모델은 주변 영어 단어 또는 프랑스어 번역에 주의를 기울여 영어와 프랑스어의 표현을 정렬하도록 유도합니다. 특히, 영어 문맥만으로 마스킹된 영어 단어를 추론하기에 충분하지 않은 경우에는 프랑스어 문맥을 활용할 수 있습니다. 정렬을 용이하게 하기 위해 대상 문장의 위치도 재설정합니다.
3.5 Cross-lingual Language Models
이 연구에서는 CLM, MLM 또는 TLM과 결합하여 크로스-언어 언어 모델 사전 훈련을 고려합니다. CLM과 MLM 목표의 경우, 256개의 토큰으로 구성된 연속 문장 스트림의 64개 스트림으로 모델을 훈련합니다. 각 반복에서 배치는 동일한 언어에서 나온 문장으로 구성되며, 언어는 위에서 언급한 {qi}i=1...N 분포에서 샘플링되며, α = 0.7로 설정됩니다. TLM이 MLM과 결합되는 경우, 이 두 목표를 번갈아가며 수행하고, 언어 쌍은 유사한 방식으로 샘플링됩니다.
4. Cross-lingual language model pretraining
이 섹션에서는 크로스-언어 언어 모델을 사용하여 다음을 얻는 방법에 대해 설명합니다: • 제로샷 크로스-언어 분류를 위한 문장 인코더의 초기화 개선 • 지도 및 비지도 형태의 신경 기계 번역 시스템의 초기화 개선 • 저자원 언어를 위한 언어 모델 • 비지도 크로스-언어 단어 임베딩

그림 1: 크로스-언어 언어 모델 사전훈련. MLM 목적은 Devlin et al. (2018)의 목적과 유사하지만 문장 쌍 대신 연속된 텍스트 스트림을 사용합니다. TLM 목적은 MLM을 병렬 문장 쌍에 확장한 것입니다. 마스크 처리된 영어 단어를 예측하기 위해 모델은 영어 문장과 해당 프랑스어 번역에 모두 참고할 수 있으며, 영어와 프랑스어 표현을 조정하는 데 도움이 되도록 유도됩니다. 대상 문장의 위치 임베딩은 정렬을 용이하게 하기 위해 초기화됩니다.
4.1 Cross-lingual classification
우리가 사전훈련한 XLM 모델은 일반적인 목적의 크로스-언어 텍스트 표현을 제공합니다. 영어 분류 작업에 대한 단일 언어 모델의 세부 훈련(Radford et al., 2018; Devlin et al., 2018)과 유사하게, 우리는 XLM을 크로스-언어 자연어 추론(XNLI) 데이터셋에서 세부 훈련하여 우리의 접근 방식을 평가합니다. 정확하게는, 사전훈련된 Transformer의 첫 번째 은닉 상태 위에 선형 분류기를 추가하고, 영어 NLI 훈련 데이터셋에서 모든 매개변수를 세부 훈련합니다. 그런 다음 우리의 모델이 15개의 XNLI 언어에서 올바른 NLI 예측을 할 수 있는 능력을 평가합니다. Conneau et al. (2018b)를 따라, 훈련 및 테스트 세트의 기계 번역 기준선도 포함합니다. 결과는 표 1에 보고됩니다.
4.2 Unsupervised Machine Translation
사전훈련은 비지도 신경 기계 번역(UNMT)의 핵심 구성 요소입니다 (Lample et al., 2018a; Artetxe et al., 2018). Lample et al. (2018b)은 사전훈련된 크로스-언어 단어 임베딩의 품질이 미지도 기계 번역 모델의 성능에 상당한 영향을 미친다고 보여줍니다. 우리는 이 아이디어를 한 단계 더 나아가, 사전훈련된 크로스-언어 언어 모델로 전체 인코더와 디코더를 사전훈련하여 UNMT의 반복적인 과정을 시작하는 기반으로 활용합니다. 우리는 다양한 초기화 방법을 탐구하고, WMT'14 영어-프랑스어, WMT'16 영어-독일어 및 WMT'16 영어-루마니아어를 포함한 여러 표준 기계 번역 벤치마크에서 이들의 영향을 평가합니다. 결과는 표 2에 제시됩니다.
4.3 Supervised Machine Translation
우리는 감독 학습 기계 번역에 대한 크로스-언어 언어 모델 사전훈련의 영향도를 조사하고, Ramachandran et al. (2016)의 접근 방식을 다국어 NMT(Johnson et al., 2017)로 확장합니다. CLM 및 MLM 사전훈련의 WMT'16 루마니아어-영어에 대한 영향을 평가하고 결과를 표 3에 제시합니다.
4.4 Low-resource language modeling
저자원 언어에서는 고자원 언어에서의 데이터 활용이 종종 유리합니다. 특히 어휘의 상당 부분을 공유하는 경우에 그렇습니다. 예를 들어, 위키피디아에는 네팔어로 작성된 약 10만 문장이 있으며, 힌디어로 작성된 문장은 그보다 6배 이상 많습니다. 이 두 언어는 10만 개의 서브워드 유닛으로 구성된 공유 BPE 어휘를 공유하기 때문에 토큰의 80% 이상이 공통으로 사용됩니다. 표 4에서는 네팔어 언어 모델과 힌디어와 영어 데이터의 다양한 조합으로 풀플렉시티를 비교합니다.
4.5 Unsupervised cross-lingual word embeddings
Conneau et al. (2018a)은 적대적 훈련을 사용하여 단일 언어 단어 임베딩 공간을 정렬함으로써 비지도 단어 번역을 수행하는 방법을 보여주었습니다 (MUSE). Lample et al. (2018a)은 두 개의 언어 사이에서 공유 어휘를 사용하고 그들의 단일 언어 말뭉치를 연결한 다음 fastText (Bojanowski et al., 2017)를 적용함으로써 고품질의 크로스-언어 단어 임베딩 (Concat)을 직접 얻을 수 있다고 보여주었습니다. 이 작업에서는 공유 어휘를 사용하지만 단어 임베딩은 크로스-언어 언어 모델 (XLM)의 룩업 테이블을 통해 얻습니다. 섹션 5에서는 코사인 유사도, L2 거리 및 크로스-언어 단어 유사성이라는 세 가지 다른 지표를 사용하여 이 세 가지 접근 방식을 비교합니다.
1. Abstract
- 최근 연구들은 NLU (Natural Lanuage Understanding-자연어 이해) 을 위한 pre-train의 효율성을 입증했음
⇒ 본 연구에서는 다국어로 확장해서, cross-lingual pre-train의 효과를 보여줌
- XLM(cross-lingual language models)의 학습 방법은 두 가지가 존재
- 단일 언어 데이터에만 의존하는 unsuperviese learning
- 병렬 데이터를 활용하는 supervised learning
➡️ cross-lingual classification unsupervised, supervised machine translation에 대해 SOTA 달성함
2. Introduction
- 기존: general-purpose sentence representation에 대한 관심은 많아졌으나, 본질적으로는 단일 언어에만 초점을 맞추고 있고, 영어에 대해서만 연구가 진행되었음
- 최근: 많은 언어에서 cross-lingual sentence representation을 학습하고, 영어 중심적 편향을 완화하고, 어떤 문장이든 shared embedding 공간으로 인코딩할 수 있는 universal cross-lingual encoder을 구축할 수 있음을 제시함
<contribution>
- cross-lingual language modeling을 사용한 cross-lingual language representation 학습을 위한 새로운 비지도 학습 방법을 제안함. 두 가지 monolingual pretraining objective를 제시
- 병렬 데이터가 있는 경우 cross-lingual pretraining을 개선하는 새로운 지도 학습 제안
- cross-lingual classification, unsupervised machine translation, supervised translation에서 이전 최고 성능을 크게 능가
- cross-lingual language model이 low-resource 언어의 복잡도 개선함
3. Cross-lingual language models
- 총 3가지 언어 모델링을 설명함
- 2가지는 단일 언어 data만 사용하는 unsupervised learning
- 1가지는 병문장을 사용하는 supervised learning
3.1 Shared sub-word vocabulary
- 기본적으로 BPE사용
- 언어 간 같은 단어(숫자나 고유명사 등)은 공유
- ex) “.”의 경우, 문장의 끝을 의미하고, 영어에서는(finish), 한국어로는(-다)로 표시.→ 즉 결국에 언어간 같은 단어를 의미하기 때문에 embedding 공간을 공유한다의 의미로 파악하면 될 듯
- 문장들은 monolingual corpora에서 일정 확률 분포를 이용해서 추출(a = 0.5)
- low-resource 언어와 관련된 토큰의 수를 늘리고, high-resource 언어에 대해서는 편향을 완화하기 위한 것임
- low-resource language가 문자 수준에서 분할되는 것을 방지하기 위해 사용
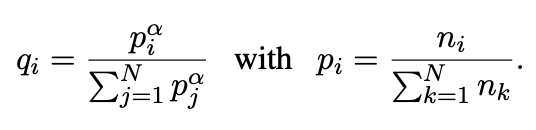
3.2 Causal Language Modeling (CLM)
- 인과 언어 모델(CLM): 문장 내 이전 단어들을 기반으로 현재 단어의 확률을 모델링하는 모델 (그냥 우리가 아는거 - 문장 넣고 맨 마지막 단어 추론하는 그런거)ex) 갈색 줄무늬를 가진 작고 털이 보송한 아기 [ ] 일 경우, 정답 후보가 고양이, 호랑이, 강아지였을 때 고양이라고 택할 것임.
- ➡️ 그 이유는 앞에 갈색 줄무늬나 작고 털이 보송한 과 같은 문맥을 기준으로 답이 추론되는데 이를 인과관계, 즉 인과 언어 모델의 대표적인 예라고 할 수 있다.
3.3 Masked Language Modeling (MLM)
- BERT와 같은 형태
- BPE 토큰의 15%를 임의로 샘플링하고, 80%의 경우 [MASK] 토큰으로 대체하고, 10%의 경우 임의의 토큰으로 대체하며, 10%의 경우 변경하지 않음


- 결론적으로 CLM과 MLM의 공통점은 비지도 학습임
3.4 Translation Language Modeling (TLM)

- 번역 말뭉치에서 원본 문장과 번역 문장을 이용
- 두 병렬 문장 쌍을 옆에 붙여서 처리함 (같은 의미를 가지는 언어가 다른 두 개의 문장 활용)
ex) the와 blue만 보고 mask 부분을 예측하기에 사실상 불가. 따라서 옆에 붙은 번역된 문장을 참고해서 mask 부분을 예측할 수 있도록 함
- position embedding도 재설정→ 각 문장의 시작점을 0으로 설정
3.5 Cross-lingual Language Models
- 3가지의 방법으로 pretraining 진행 : CLM, MLM, CLM used in combination with TML
- CLM, MLM
- Batch size : 64
- Token length : 256
- 같은 배치 내에서는 같은 언어만
- CLM used in combination with TML
- 같은 배치내에서는 같은 언어쌍이 나오도록 함
4. Cross-lingual language model pretraining
- Cross-lingual LM 를 통해 얻고자 하는 것(초기화를 어떻게 해야 좋을까?)
- a better initialization of sentence encoders for zero-shot cross-lingual classification
- a better initialization of supervised and unsupervised neural machine translation systems
- language models for low-resource languages
- unsupervised cross-lingual word embeddings
4.1 Cross-lingual classification
- NLI: 전제가 주어졌을 때, 두 문장의 유사도를 통해 가설이 참(포함, 수반), 거짓(모순) 혹은 중립(결정되지 않음) 중 어떤 것인지 결정하는 작업
- XNLI 데이터 셋을 훈련시켜서 평가
 💡※ Zero shot : 모델이 학습 과정에서 배우지 않은 작업을 수행하는 것을 의미함 (GAN과 같은 방식) unseen data를 넣어 함께 학습시켜서 unseen에 대한 예측도 수행하도록 하는 것 ⇒ labeling 된 데이터가 없다는 것을 의미💡※ 제로샷 학습은 이전에 학습된 모델을 사용하여 학습 데이터에 없는 새로운 클래스를 인식하고 분류할 수 있음. 이를 위해서는 새로운 클래스에 대한 설명 정보를 입력으로 주어야 함
💡※ Zero shot : 모델이 학습 과정에서 배우지 않은 작업을 수행하는 것을 의미함 (GAN과 같은 방식) unseen data를 넣어 함께 학습시켜서 unseen에 대한 예측도 수행하도록 하는 것 ⇒ labeling 된 데이터가 없다는 것을 의미💡※ 제로샷 학습은 이전에 학습된 모델을 사용하여 학습 데이터에 없는 새로운 클래스를 인식하고 분류할 수 있음. 이를 위해서는 새로운 클래스에 대한 설명 정보를 입력으로 주어야 함ex) '강아지', '고양이', '토끼' 등의 동물 분류 모델이 있다고 가정. 이 모델이 '사자'라는 클래스에 대해서는 학습되지 않았지만, '사자'라는 동물의 특징을 설명하는 텍스트 정보를 입력하면, 모델은 이를 이용하여 '사자'를 분류함.
ex)
⇒ 15개 다국어 병렬 데이터를 TLM으로 학습한 후, 영어 NLI로 Fine Tuning 진행
⇒ 15개 국어로 공부하고 영어로 추론하는 법을 학습.
⇒ 15개 국어로 inference 진행
⇒ 실제 테스트할 때, 처음 보는 unseen data를 넣으면 그것을 영어로 잘 번역하도록 하게 됨
4.2 Unsupervised Machine Translation
- 비지도 학습으로 번역을 해야 하기에 TML은 사용 x
- 기존에는 transformer의 embedding 부분만 가져와서 사용했었으나, Encoder와 Decoder를 각각 CLM, MLM의 조합으로 다양하게 실험 진행
- CLM과 MLM을 번갈아가면서 실험했음 (TLM은 사용 안함)

4.3 Supervised Machine Translation

- 지도학습의 경우 MLM과 Back-translation 조합한 방법이 제일 좋았음
4.4 Low-resource language modeling


둘이 비슷하게 생김 - Wikipedia에는 네팔어가 100k 문장이 존재.
- 반면, 힌디어는 네팔어보다 66배 정도 많음.
- 두 언어는 매우 유사해서 80%정도의 BPE vocabulary를 공유한다고 함⇒ 복잡도가 낮을수록 언어 모델의 학습이 잘 됐다고 할 수 있음.
- ⇒ 네팔어로만 학습했을 때의 PPL은 157인 반면 다른 언어지만 비슷하고 양이 많은 힌디어를 합쳐서 XLM을 학습하면 109 PPL로 언어 모델 학습이 잘됨
💡결론: 희소 언어인 경우 유사한 다른 언어와 합쳐서 학습하면 더 좋은 성능의 언어 모델을 얻을 수 있음4.5 Unsupervised cross-lingual word embeddings
- 병렬 데이터를 사용하여 같은 의미의 문장이나 단어라면 서로 다른 언어일 지라도 같은 공간에 맵핑하고자 하는 연구 방식

- pretraining을 하면 어느 정도 훈련이 된 상태
- x: 영어, y: 타겟 임베딩
- x를 선형 변환시켜서 학습시키다보면 유사하게 되는 그런 방식..

5. Inference
'Deep Learning > [논문] Paper Review' 카테고리의 다른 글
| Noisy Student: Self-training with Noisy Student improves ImageNet classification(2019) (0) | 2023.07.14 |
|---|---|
| NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (1) | 2023.07.13 |
| YOLOv4: Optimal Speed and Accuracy of Object Detection (0) | 2023.07.09 |
| EfficientNet (0) | 2023.07.07 |
| cGAN/Pix2Pix (0) | 2023.07.07 |



