<Taskonomy>가 뭐냐?
Taskonomy는 컴퓨터 비전 분야에서 다양한 작업 간의 상호 의존성을 탐구하고, 이를 통해 범용 비전 시스템을 구축하는 연구.
Taskonomy는 다양한 작업들을 수행하기 위해 필요한 시각적 특징들이 서로 공유될 수 있는지를 조사하고, 이를 통해 모델의 학습 효율성과 성능을 향상시킬 수 있는 전이 학습 방법을 탐구.
Taskonomy의 목표는 다양한 작업들 간에 공유 가능한 시각적 특징을 탐색하여, 작업 간의 학습과 일반화를 개선하고 작업 전환에 따른 비용과 노력을 최소화하는 것.
※ Transferability란?
- 한 작업에서 학습한 지식이 다른 관련 작업에 적용 가능한 정도를 나타내는 개념
- 즉, 한 작업에서 얻은 학습 결과나 모델이 다른 작업에도 적용될 수 있는 능력을 의미함
0. Abstract
- 여러 Visual Task(detection, depth estimation, edge detection) 등은 서로 연관성, 의존성이 있다는 가정 하에 논문이 시작됨 ⇒ transfer learning의 기본 개념임.
- 논문에서는 의존성 찾는 것을 통해, transfer learning 에 대한 계산적인 분류도 ‘Taskonomy’를 설명함
1. Introduction
- 오늘날의 vision 분야에서 다뤄지는 task들은 classification, depth estimation(깊이 추정), edge detection(경계선 검출), pose estimation(포즈 추정) 등 다양함
- 이러한 task들은 서로 간에 가지고 있는 정보들이 유사해서 공유될 task도 분명히 있을텐데, 각각 학습시키면 낭비 아닌가에 대한 의문점이 생김➡️ 서로 다른 task들 간의 관계를 그래프 형태로 표현하고, 이를 이용해 새로운 task에 대한 모델의 학습을 보다 효율적으로 학습시킬 수 있는 방식을 제안함

- Target Task를 단독으로 학습했을 때 대비 성능이 향상된 수준을 ‘Transferability’ 척도로 측정했고, Task 간의 관계를 유사도행렬(affinity matrix)로 표현한 후, Target Task에 대한 최적의 Transfer policy를 찾아냄 ( 모든 과정은 각 task에 대한 prior knowledge가 개입 안하도록 구성됨 )➡️ 결론적으로 비용이 적게 들고, 일반적인 데이터셋에 유효하다는 것을 보여줌
2. Related Work
Taskonomy 방법과 관련된 매우 다양한 관련 연구 주제들이 존재.
Self-Supervised Learning
- 레이블이 없는 데이터로부터 모델을 학습시켜서 가짜 레이블 생성
- 레이블링 비용이 상대적으로 낮은 task로부터 학습한 정보를 활용하여, 그와 내재적으로 관련되어 있으면서 레이블링 비용이 더 높은 task에 대한 학습을 시도하는 방법
- source task를 사전에 사람이 수동으로 지정해줘야 한다는 측면에서, Taskonomy 방법과 차이가 존재
Unsupervised Learning
- 레이블이 없는 데이터로부터 학습하는 방법으로, 명시적인 지도나 레이블 없이 데이터의 패턴과 구조를 발견
- (레이블이 없는 상황에서) 데이터셋 자체에 공통적으로 내재되어 있는 속성을 표현하는 feature representation을 찾아냄
- Taskonomy 방법의 경우 각 task 별 레이블을 명시적으로 필요로 함.
Meta-Learning
- 모델이 학습 방법을 학습하는 학습 접근 방식으로, 다양한 과제 분포에서 지식이나 사전 정보를 습득하여 새로운 과제에 대한 일반화와 적응 능력을 향상시키는 것
- 모델 학습을 상위 레벨(meta-level)에서의 좀 더 ‘추상화된’ 관점으로 조명하고 모델을 더 효과적으로 학습하기 위한 일반적인 방법을 찾음
- 복수 개의 task들 간의 transferability를 좀 더 meta-level에서 조망하면서 이들의 structure를 찾기 위한 일반적인 방법을 제안한다는 점에서, Taskonomy 방법과 일종의 공통점이 존재
Multi-Task Learning
- 입력 데이터가 하나로 정해져 있을 때 이를 기반으로 여러 task들에 대한 예측 결과들을 동시에 출력할 수 있도록 하는 방법을 연구하는 주제
- Taskonomy 방법은 두 task들 간의 관계를 명시적으로 모델링함
Domain Adaptation
- transfer learning의 형태로, task는 동일하지만, 입력 데이터의 domain이 크게 달라지는 경우(source domain -> target domain) 최적의 transfer policy를 찾기 위한 연구 주제
- Taskonomy의 경우, domain이 아닌 task가 달라지는 경우를 가정
Learning Theoretic
- 모델의 일반화 성능을 보장하기 위한 방법
- 위의 주제들과 조금씩 겹침
- 위의 방식들은 대부분 계산이 불가능한 계산을 포함함
- 혹은 불가능한 계산을 피하기 위해 task에 많은 제한을 두었음
- Taskonomy는 위의 방식으로부터 영감을 얻었으나, 이론적 증명을 피하고 실용적인 접근으로 시도함
3. Method
Source Task가 개와 고양이의 이미지 분류 작업이라고 가정해보자. 이 작업에서 모델은 주어진 이미지가 개인지 고양이인지를 판별하는 방법을 학습할 것임. 그리고 Target Task로는 개의 얼굴 검출 작업을 한다고 가정. 이 작업에서는 이미지 내에서 개의 얼굴 영역을 찾아내는 것을 목표로 할 것임.
Source Task인 개와 고양이의 이미지 분류 작업에서 학습된 모델은 이미지의 특징과 패턴을 파악하는 데 능숙해져있음. 이러한 지식은 Target Task인 개의 얼굴 검출 작업에도 유용할 수 있음. 예를 들어, 개의 얼굴은 개 이미지에서 특정한 모양과 구조를 가지고, Source Task에서 학습된 모델은 이미지에서 이러한 특징을 잘 이해하고 있을 것임.
따라서, Source Task에서 학습된 모델을 가져와서 Target Task에 적용하면, 개의 얼굴을 검출하는 능력을 향상시킬 수 있다. Source Task에서 학습한 이미지 분류 작업을 통해 얻은 지식을 활용하여 Target Task인 개의 얼굴 검출 작업에서 성능을 향상시킬 수 있는 것을 말함. 즉, Source Task와 Target Task는 서로 다른 작업이지만, Source Task에서 얻은 지식을 Target Task에 적용하여 전이(transfer)하는 것이 바로 Taskonomy의 핵심 개념.
※ Taskonomy란
: 주어진 Task Dictionary에서 Task 간의 Transferability를 나타낸, 계산적으로 도출이 가능한 Hypergraph
※ Hypergraph란
: 하나의 edge가 여러 Node를 연결할 수 있는 그래프 (단순화)
➡️ 하나의 target task에 여러 source task가 연결돼서, 성능 극대화를 위해 사용할 수 있다고 함.

Taskonomy 방법 ( 총 4단계)
2. 지정된 Transfer Order k 하에서, 서로 간의 조합 연산을 통해 만들어지는 source task(s) -> target task 의 각 조합 별 transferability가 수치화된 형태로 계산
3. 2번에서 계산된 transferability에 대한 정규화를 통해 affinity matrix를(유사도 행렬) 얻음
4. 각 transfer policy를 탐색해서 최적의 성능을 보이는 transfer policy를 찾음
※ Transfer Policy란
: 모델이 한 작업에서 학습한 지식을 다른 작업에 전달하고 활용하는 방법을 결정하는 정책이나 전략을 의미
- 본 논문에서는 Computer vision에서 일반적으로 다루는 26가지의 task를 제시.
- Datasets: 실험에 쓰인 데이터셋은 본인들이 직접 제작. 600개 건물의 실내 장면에 대한 400만 개의 이미지 데이터셋을 생성, 이 데이터를 가지고 26가지 task에 대한 레이블링을 모두 수행함.


3.1. Step I: Task-Specific Modeling (작업별 모델링)
- 각 Task-specific network는 공통적으로 encoder-decoder 구조를 지님
※ 인코더는 강력한 표현을 추출하기에 충분히 크고, 디코더는 좋은 성능을 달성하기에 충분히 크지만 인코더보다 훨씬 작다고 함

3.2. Step II: Transfer Modeling


어느 입력 이미지 I에 대한 transfer network의 예측 레이블은 왼쪽처럼 표현됨

- ft(I): 입력 이미지 I에 대한 target task t의 Ground Truth
- L(t): 해당 task의 loss function
- D(s→t)의 성능이 좋을수록 두 task s,t 간의 transferability가 높음
- 모든 (s,t) 조합에 대한 readout Function을 모두 구함
- 이때, 여러 source task가 target task를 해결하기 위한 보완적인 정보를 포함할 수 있음 (하나의 정보보다는 여러 정보들을 통해 다양한 정보를 제공하면 성능 올릴 수 있다는 말)
- k가 커질수록 전체 조합 경우 수도 늘어나겠죠?
- TT x sCk_sC_k : 모든 target task에 대한 전체 조합 경우의 수➡️ 하지만, 계산량이 방대해짐
※ beam search란
: 가능한 다양한 후보들 중에서 최적의 해를 찾는 방법
: 제한된 집합에서 가장 유망한 노드를 확장하여 그래프를 탐색하는 발견적 탐색 알고리즘


- 예를 들어, s=7, t=1, k=2로 설정한 경우,
개의 조합이 나올 것이고, 5개만을 가져간다고 하면, 5C2이므로 10개의 조합을 걸치게 됨
(s1,s2~s5), (s2,s3~s5), (s3,s4~s5), (s4,s5) → 총 10가지
3.3. Step III: Ordinal Normalization using Analytic Hierarchy Process (AHP)
- Target task에 따라 Loss의 범위가 다르기 때문에 Ordinal 접근법을 사용하여 정규화 수행
※ [0,1] 범위로 조정하는 방법을 사용하지 않는 이유
- Loss 값의 감소에 따른 실제 체감되는 예측 결과 품질의 증가 속도도 task 별로 차이가 존재한다고 함➡️ 단순히 normalize하는 것만으로는 모든 target task들을 동일 선상에서 커버하기에 충분하지 않음
※ 왜 Target task마다 Loss 범위가 다른가?
- 해의 공간의 복잡성: target task에 따라 가능한 해의 공간이 다양하고 복잡성이 달라짐. 일부 태스크에서는 해의 공간이 상대적으로 작고 단순할 수 있지만, 다른 태스크에서는 매우 크고 복잡한 공간일 수 있음.
- target task의 요구 사항: 각 target task는 다른 요구 사항을 가지고 있음. 어떤 task에서는 많은 후보를 고려하는 것이 유리할 수 있으며, 이는 더 큰 빔 크기(K 값)를 필요로 함. 다른 태스크에서는 작은 K 값이 충분할 수도 있음.
- 성능과 효율성의 균형: 빔 크기(K 값)는 성능과 효율성 사이의 균형을 나타냄. 더 큰 K 값은 더 많은 후보를 고려하고, 이로 인해 더 좋은 성능을 얻을 수 있음. 그러나 동시에 연산 비용도 더 많이 소모하게 됨. 따라서, 실제로 선택되는 K 값은 성능 목표와 연산 비용을 고려하여 조정되어야 함.
- 각tt에 대해, 모든 source task간의 transability를 비교하는 행렬WtW_t을 만듬.
- 행렬의(i,j) (i, j)의 요소wi,jw_{i, j}는 test 데이터에서 si가 sj보다 t에 대해 더 성능이 우수했던 (식으로 표현한 것:Dsi→t(I)>Dsj→t(I){D_{s_i→t}}(I) > Ds_{j→t}(I)) 테스트 이미지(I)의 수를 카운팅하고, test set 내에서의 비율을 계산함.

- Wt를 [0.001, 0.999] 범위로 clipping 함.
- Wt의 합이 1이 되도록 새로운 matrixWt‘W_t^`==Wt/WtTW_t / W_t^T(element-wise)를 계산함.※si s_i가sjs_j에 비해 성능이 얼마나 더 우수했는지 나타낸다고 함.

- Wt‘W_t^`의 eigenvector(고유값이 가장 큰 고유벡터)를 계산함
- principal eigenvector의 i번째 성분은, 이에 대응되는 i번째 source task들로 구성한 centrality(중심성)를 나타내게 됨 (아 모르겠음 뭔말이야. 어려워!!!~!~!~)
➡️ 즉, 쉽게 말해서 해당 source task의 target task에 대한 일종의 ‘영향력’을 나타냄. ⇒ Analytic Hierarchy Process(AHP) → 경영과학에서 많이 쓰이는 방식이라고.
※ AHP란
상호 배타적인 대안들을 체계적으로 평가하여 우선 순위를 도출하는 의사결정방법
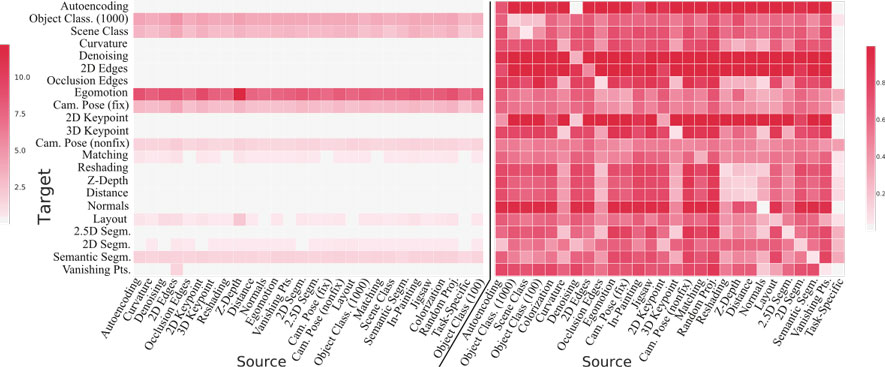
- 모든 t ∈ T에 대한 W0t의 주요 고유벡터를 쌓아서 행렬 P('p'는 성능을 나타냄)을 얻음.
3.4. Step IV: Computing the Global Taxonomy
- task가 노드(머리)이고 transfer가 엣지(간선)인 하위 그래프(subgraph) 선택으로서 정의될 수 있음
※ subgraph 그림 참고
- 원래 그래프 안에서 새로 만들어낸 그래프


➡️ 최적의 하위 그래프는 이상적인 tast 노드와 대상으로부터의 최상의 edge를 선택하면서tast 노드의 수가 supervision budget 을 초과하지 않도록 함
※ supervision budget
- 모델이 특정 작업에 대해 얼마나 많은 레이블 혹은 감독 신호를 받을 수 있는가에 대한 범위라고 생각하면 될 듯.
- Supervision Budget이 높을수록 모델은 해당 작업에 대해 더 많은 감독 신호를 활용하여 더 정확하게 학습할 수 있음

4. Experiments
- Step 1에서 학습시킨 Task-specific network들의 각 task 별 성능 결과

4.1. Evaluation of Computed Taxonomies
- Supervision budget γ 및 Transfer Order를 변경해 가면서 학습한 결과 얻어진 몇 가지 예시
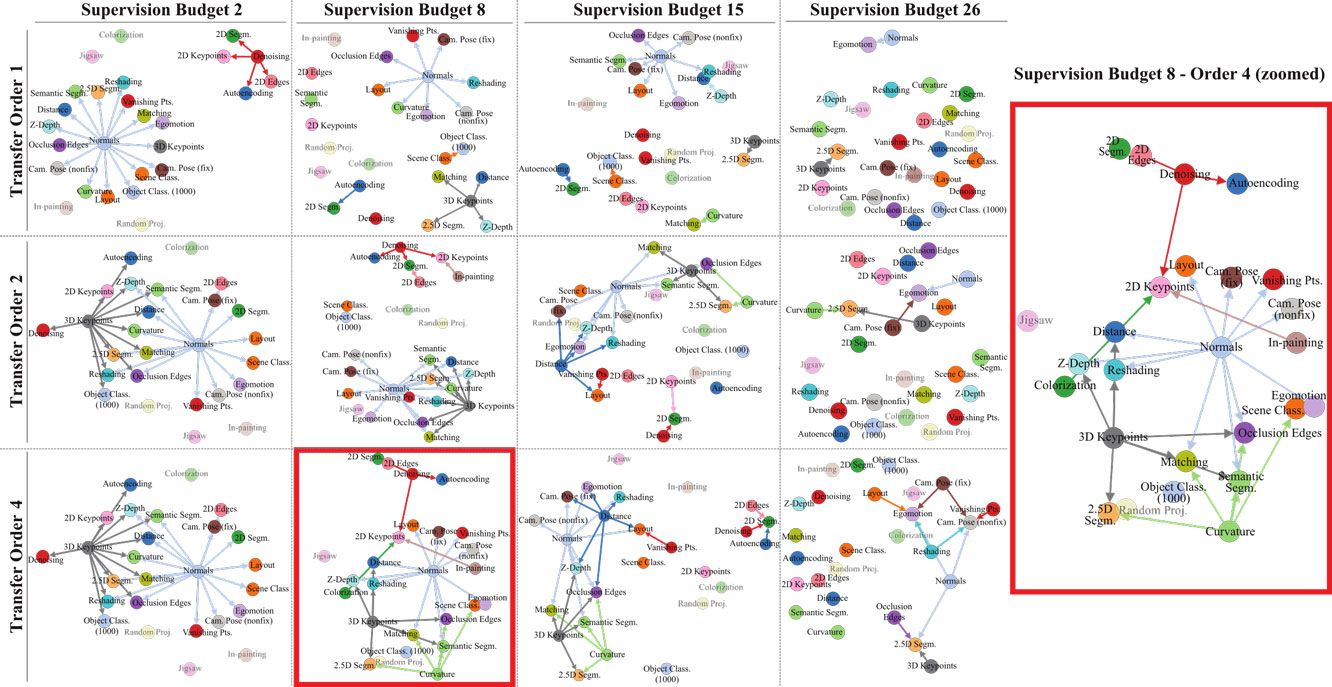
- Taskonomy에 기반해서 얻어진 transfer 규칙들을 각 target task에 적용해서 transfer learning을 수행했을 때의 성능을 보여줌 (2가지 지표를 사용)

Gain
: Transfer network의 학습에 사용한 validation set(1.6만)으로, target task의 task-specific network를 처음부터 학습하는 방법을 baseline으로 설정했을 시의, taskonomy 방법의 win rate(%)
Quality
Task-specific network의 학습에 사용한 training set(12만)으로, target task의 task-specific network를 처음부터 학습하는 방법을 baseline으로 설정했을 시의, taskonomy 방법의 win rate(%)
- Maximum transfer order를 증가시킬수록, 그리고 supervision budget γ를 증가시킬수록, Gain과 Quality가 점차적으로 증가하는 경향을 보임
➡️ 더 많은 source task로부터 얻은 지식을 transfer할 수록 성능이 높아질 것이다라는 가설이 성립됨.
4.2. Generalization to Novel Tasks
- 새로운 task에 대한 일반화 성능 검증 결과

- 이전까지의 실험에서는 사전에 가정한 source-target 조합들을 고려하여 taskonomy를 계산하는 과정을 거쳤지만, 현실적인 상황에서는 새로운 target task에 대해서 기존에 있던 source task만을 가지고 최적의 transfer policy를 찾아야 함.
➡️ 기존 Task들을 모두 Source로 옮기고, 새로운 Task를 단일 Target으로한 일반화 성증 검증 실험을 수행
➡️ ImageNet 데이터셋으로 학습한 AlexNet의 FC7을 features로 사용한 경우 등에 비해, 완성된 taskonomy에 기반하여 찾은 transfer policy에 따라 학습한 경우의 성능이 전체적으로 더 우수한 것으로 나타남 (질문- 잘 모르겠음)
5. Significance Test of the Structure
- Taskonomy로 찾은 최적의 Transfer policy 적용 성능 비교 결과 (초록색: 최적의 transfer policy, 회색: 랜덤 transfer Policy)

6. Limitations and Discussion
- Model Dependence: 학습은 DNN, 데이터는 이미지 데이터만 사용 → 실험 결과가 특정 모델과 데이터셋에 너무 특화되어있다고 표현할 수 있을 듯
- Compositionality: 본 논문에서 다룬 task들은 모두 사람이 정의한 task에 해당. → 새로운 부분 작업(Subtask)을 발견할 가능성에 대한 의문을 제기함 (다양한 task를 다루지 못했다..)
- Space Regularity: 26개의 task에서 샘플링을 통해 얻은 task만을 사용했기에, 과연 일반적인 task인가에 대해 의문 제기
- Transferring to Non-visual and Robotic Tasks: 이미지와 관련된 visual task들에 대해서만 검증을 수행함 → 시각적이지 않은 분야에서도 Taskonomy 방법을 통해 transferability를 극대화할 수 있을지에 대한 의문 제기
- Lifelong Learning: 본 논문에서는 Taskonomy를 완성하는 작업을 단 한 번에 수행함 → 시스템이 지속적으로 학습을 진행하고, 이를 기반으로 어떤 task를 점진적으로 확장시킬 수 있을지에 대한 검증 필요
7. Reference
https://rahites.tistory.com/179
감사합니다.
생각보다 이해하는데 어려웠던 논문.'Deep Learning > [논문] Paper Review' 카테고리의 다른 글
| DETR: End-to-End Object Detection with Transformers (0) | 2023.07.23 |
|---|---|
| SRNet: Editing Text in the Wild Review (0) | 2023.07.17 |
| Noisy Student: Self-training with Noisy Student improves ImageNet classification(2019) (0) | 2023.07.14 |
| NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (1) | 2023.07.13 |
| XLM: Cross-lingual Language Model Pretraining (0) | 2023.07.09 |



