BodyNet이란?
: 단일 이미지로부터 2D pose, segmentation 추출, 두 개의 정보를 활용해 3D pose를 학습, 이후, 3가지 정보에 RGB 정보까지 활용해 3D의 부피 기반 체형을 구성하는 Network를 말함
: end to end 형식

<학습 방식>
1. 입력 RGB 이미지는 먼저 2D 포즈 추정과 2D 신체 부위 세그멘테이션을 위한 하위 네트워크를 통과
2. 2D pose와 segmentation을 훈련
3. 학습된 2D pose와 Segmentation 가중치를 고정해서 3D pose를 훈련시킴
4. 이후, 이전의 모든 네트워크 가중치를 고정하고 3D 형태 network를 훈련
5. 추가 재프로젝션 손실로 형태 네트워크 훈련해서 부피 기반 형태 추정 작업에 대해 세밀 조정
6. 결합된 손실로 모든 네트워크 가중치를 end to end 미세 조정
7. 평가로 부피 예측에 SMPL 모델을 맞춤
0. ABSTRACT
: 인간의 형태 예측은 비디오나 애니메이션 혹은 패션 산업에 있어서 중요한 작업
: 하지만, 이미지에서 3D 신체 형태를 예측하는 것은 시점이나, 체형, 의복과 같은 요인들로 인해 매우 어려움
: 또한, 이러한 방법을 위해서는 인체 모델을 맞추려고 하고, 포즈 및 형태에 대한 특정 사전 지식을 지니고 있어야 함
➡️ 단일 이미지로부터 3D 형태를 직접 추론하는 BodyNet을 제안
: End to End 형식
(i) 3D 볼륨 손실
(ii) 다중 뷰 재투영 손실 및
(iii) 2D 포즈, 2D 신체 부위 세그멘테이션 및 3D 포즈의 중간 지도가 이루어짐
: 평가의 경우, SMPL 모델을 BodyNet 출력에 맞추고 최근의 SURREAL [33]과 Unite the People [34] 데이터셋에서 단일 뷰 3D 인간 형태 추정 성능을 측정함
1. Introduction
: 단일 뷰 환경에서는 3D 형태 추정 연구가 활성화 되어있지 않았음
: 대규모 데이터셋, 높은 차원 등이 필요
➡️ 볼륨 표현을 제안, 3D voxel grid를 활용함, 재투영 손실 제안, segmentation활용
<Contribution>
- 3D 인간 형태 추정을 위해 단일 뷰 접근 방식을 다루고 이 작업을 위한 볼륨 표현을 제안함
- 여러 가지 네트워크 아키텍처를 조사하고 멀티뷰 재투영 손실과 2D 포즈, 2D 신체 부위 세그멘테이션, 3D 포즈의 중간 네트워크 지도를 결합한 엔드 투 엔드 훈련 가능한 BodyNet을 제안
- 해당 network는 미분 가능하며 볼륨 기반의 신체 부위 세그멘테이션을 제공
3. BodyNet

: 하나의 이미지로부터 3D 인체 형태를 예측하며, 2D 포즈, 2D 인체 부위 세그멘테이션, 3D 포즈 및 3D 형태를 예측하기 위해 독립적으로 훈련된 네 개의 하위네트워크로 구성됨
3.1 Volumetric inference for 3D human shape
: 3D voxel grid를 정의함
※ voxel
: 3차원 공간에서 정규 격자 단위의 값을 나타냄.
: 부피 (volume)와 픽셀 (pixel)을 조합한 혼성어
➡️ 3차원에서의 pixel을 나타낸 것이라고 생각하면 될듯

: voxel grid를 고정된 해상도 그리드로 변환
: 직교 투영을 가정하고, xy 평면이 입력 이미지의 2D 세그멘테이션 마스크와 공간적으로 대응하도록 볼륨을 재조정 (2D segmenation한 것을 3D 위치에 둔다는 말)
: 재조정 후, 인체는 z축을 기준으로 중심에 위치 (3D화)
: 나머지 공간 0으로 패딩

: 위 손실함수를 활용해서 배경과, 신체를 분할함
: 또한, 다중 클래스 교차 엔트로피 손실을 사용하여 3D 인체 부위 세그멘테이션을 수행 : 머리, 상체, 좌/우 다리, 좌/우 팔을 포함한 6개 부위를 정의하고 배경을 포함하여 7개 클래스 분류를 학습
➡️ 이로써, 비용이 많이 드는 SMPL 모델 적합을 거치지 않고도 직접적으로 3D 인체 부위를 추론할 수 있음
3.2 Multi-view re-projection loss on the silhouette

: 3D 구성을 하다보면, 인체 중심으로부터 먼 팔과 다리의 신뢰도가 낮아지는 경향을 관찰할 수 있음
➡️ 따라서, 경계 복셀의 중요성을 증가시키는 추가적인 2D 재프로젝션 손실을 사용 (다중 뷰 재프로젝션 항이 필요(다각도에서의 포즈를 재학습 시키는 의미)
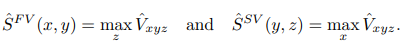
: 직교 투영을 가정함

1) 앞 뷰 투영인 SˆF V는 z축을 따라 max 연산자를 사용하여 볼륨 그리드를 이미지에 투영하여 얻음.
2) 측면 뷰 투영인 SˆSV는 x축을 따라 max 연산자를 사용하여 얻음

3.3 Multi-task learning with intermediate supervision
: 서브네트워크의 입력은 RGB, 2D 자세, 세그멘테이션, 그리고 3D 자세 예측을 결합하여 구성
: 각 서브네트워크의 아키텍처는 stacked hourglass 네트워크 [1]를 기반으로 함
※ stacked hourglass network
: Residual block + top-down 느낌

: 하나의 block은 residual unit을 의미
: 입력값이 최소 resolution을 갖도록 residual unit을 통한 down sample을 거침
: 최소 resolution에 도달한 뒤에 biliear upsample 방식으로 원래 입력값 크기로 복원
: 또한 동일한 크기의 resolution 끼리 element-wise addition 연산을 수행함

: 위와 같은 과정을 거치면, 최소 resolution이 지니고 있는 얼굴, 손과 같은 local 정보와 원래 입력 크기가 지니고 있는 몸 전체, 사람의 방향, 팔의 형태를 함께 이용할 수 있다고 있다고 함.
- 2D Pose

: 2D 자세의 heatmap 표현을 사용
: 각 인체 관절에 대해 고정된 분산을 가진 가우시안이 해당 관절의 이미지 위치에 중심으로 예측
: 최종 관절 위치는 각 출력 채널에서 최댓값을 가진 픽셀 인덱스로 확인
: hourglass 네트워크의 첫 두 스택을 사용
: 16개의 인체 관절을 예측
- 2D Part Segmentation

: 아키텍처는 2D 자세 네트워크와 유사하며 다시 처음 두 스택을 사용
네트워크는 입력 RGB 이미지에 대해 각 부위에 대한 하나의 히트맵을 예측
- 3D Pose

: 단일 이미지에서 3D 관절 위치를 추정하는 것은 본질적으로 모호한 문제
: 카메라 내부 매개변수가 알려져 있다고 가정하고 3D 자세를 카메라 좌표계에서 예측함
: 3D 히트맵으로 2D 히트맵을 확장하여 각 관절의 3D 위치를 3D 가우시안으로 나타냄 (2D 히트맵을 확장해서 3D화 하겠다)
: 각 관절에 대해 네트워크는 관절 위치에서 중심으로 하는 단일 3D 가우시안이 있는 고정 해상도 볼륨을 예측
➡️ 3D 그리드의 xy 차원은 결국 이미지 좌표와 일치하기 때문에, 2D 관절 위치를 나타내며, z 차원은 깊이를 나타냄
: 복셀 그리드가 3D 본체와 일치하도록 하고, 루트 관절이 3D 볼륨의 중심에 해당하도록 가정
<최종 학습 방식>

(i) 2D 자세와 세그멘테이션을 훈련합니다.
(ii) 고정된 2D 자세와 세그멘테이션 네트워크 가중치로 3D 자세를 훈련합니다.
(iii) 이전의 모든 네트워크 가중치를 고정하고 3D 형태 네트워크를 훈련합니다.
(iv) 그런 다음, 추가 재프로젝션 손실로 형태 네트워크를 계속 훈련합니다.
(v) 마지막으로 결합된 손실로 모든 네트워크 가중치를 엔드 투 엔드로 미세 조정합니다
3.4 Fitting a parametric body model
: 평가를 위해 SMPL 모델을 사용


EXPERIMENTS
4.1 Datasets and evaluation measures
: Dataset으로는 SURREAL 과 Unite the People을 사용함
: 평가지표 : IOU


4.2 Alternative methods

: BodyNet 입력에 대한 fitting(SMPLify++)은 평균적인 모양과 유사한 형태를 생성.
: BodyNet은 이미지에서 관찰된 실제 모양이 평균적인 변형 가능한 모양 모델에서 어떻게 벗어나는지를 학습함

: 중간표현( 2d pose, 2d Segmentation, 3d pose)를 의미함
: 2d prediction이 실패해도 다른 정보들을 상호보완해서 3D 몸체 형태를 추론하기에 3D 모양 복구가 가능하다.
4.3 Effect of additional inputs
: 추가적인 2D 포즈와 세분화 입력으로 이미 훈련된 3D 포즈 네트워크가 가장 우수한 결과를 보임
: 3D 포즈와 2D 세분화를 중간 표현으로 사용하는 것이 RGB보다 더 나은 결과를 보여줌
4.4 Effect of re-projection error and end-to-end multi-task training

: 앞면 재프로덕션과 측면 재프로덕션을 했을 때 성능이 가장 좋았다
4.5 Comparison to the state of the art on Unite the People
<생략>
4.6 3D body part segmentation

: 최신 GPU를 사용하여 이미지 당 0.28초와 0.58초의 속도로 BodyNet이 전경 및 개별 팔다리 복셀을 성공적으로 생성할 수 있음
: 단일 이미지에서 3D 몸체 부위 라벨링을 위한 최초의 종단 간 접근 방식으로 알려짐
: 변형 가능한 모델의 반복적 적합 없이도 네트워크로 직접 3D 몸체 부위를 추론하고 성공적인 결과를 얻음
<참고>
https://deep-learning-study.tistory.com/617
https://ko.wikipedia.org/wiki/복셀
'Deep Learning > [논문] Paper Review' 카테고리의 다른 글
| DINO: Emerging Properties in Self-Supervised Vision Transformers (2021) (0) | 2023.08.10 |
|---|---|
| Expressive Body Capture: 3D Hands, Face, and Body from a Single Image (0) | 2023.08.04 |
| mixup: Beyond Emprical Risk Minimization (0) | 2023.08.03 |
| SMPLify(Keep it SMPL): Automatic Estimation of 3D Human Pose and Shape from a Single Image (0) | 2023.07.31 |
| SMPL: A Skinned Multi-Person Linear Model (0) | 2023.07.28 |



