: Top-performing classification: 이미지나 데이터를 입력으로 받아 클래스 레이블을 예측하는 모델.
: captioning: 이미지나 비디오에 대한 설명을 생성하는 모델.
: VQA (Visual Question Answering): 이미지에 대한 질문에 대한 답변을 생성하는 모델.
Human study를 수행해서 Grad-CAM이 class-discriminative 있고, 신뢰를 돕는데 도움이 되도록 함.⇒ 훈련되지 않은 일반인(이 분야 모르는 사람)도 모델을 봤을 때, ‘강한’ 모델과 ‘약한’ 모델을 구분할 수 있음을 보여줌 (아, 이 모델은 구분을 잘 하는 모델이구나 혹은 학습이 잘된 모델이구나~ 아, 이 모델은 뭔진 모르겠지만 성능이 별로인 모델이구나)
2 RELATED WORK
<기존 연구들의 방법과 한계점들을 소개함 ⇒ 이를 바탕으로 발전시키고자 함>
1. Visualizing CNNs.
‘pixel’ 단위의 영향력(중요성)을 시각화 하려는 연구가 많았으나, class-discriminative 하지 않음
➡️ 각 cat과 dog 예측에도 불구하고, feature map 상 두 개의 클래스가 구분되지 않음
또 다른 연구로는 특정 유닛(뉴런)이 활성화될 때 어떤 입력 이미지가 생성될 수 있는지를 알아내고자 했음
➡️ high resolution + class-discriminative 지만, single image에 대해서가 아니라 모델 전반을 시각화 한다는 한계점을 지녔음
2. Assessing Model Trust.
: [Why Should I Trust You?] 라는 논문에서 모델에 대한 신뢰성을 연구하는 것을 보면서, 이 개념에 영감을 받아 본 논문은 Human study를 통해 Grad-CAM 시각화를 평가하였음
➡️ Grad-CAM이 자동화된 시스템을 평가하고 신뢰할 수 있는 도구로서 중요한 역할을 할 수 있음
3. Aligning Gradient-based Importances.
: [Choose your neuron] 라는 논문에서 gradient에 기반한 neuron importance를 인간의 class specific domain-knowledge에 연결하고 새로운 class에 대한 분류기 학습
➡️ gradient 기반의 중요성을 Grad-CAM에 적용하고자 함
4. Weakly-Supervised localization.
: class label만을 사용해서 이미지 내의 객체를 localize 하는 가장 관련있는 방식이 CAM(Class Activation Map)
: CNN의 마지막 feature map을 GAP한 뒤, 가중치(w)를 각각 곱해서 class score을 계산
: 각 w를 feature map과 선형 결합해서 class activation map을 얻을 수 있고, 이를 통해 class score에 대한 feature map의 중요성(영향력)을 시각화할 수 있음
CAM의 최대 단점: conv feature map → GAP → softmax 의 architecture로만 구성되어야 CAM을 사용할 수 있었음. 즉, 모델을 재구성 해야 한다는 단점이 존재했다.
➡️ 따라서, 이 논문은 architecture를 수정/재구성할 필요 없이 사용하는 “gradient 방식”을 도입함
3 Grad-CAM
3-1) Grad-CAM
: CNN에서 얕은 층은 low-level feature을 읽고, 깊은 층으로 갈수록 semantic class-specific 정보를 읽음
: Grad-CAM은 CNN의 마지막 layer로 흐르는 gradient를 이용해 모델의 예측에 각 뉴런이 미치는 영향(=중요성)을 파악함
: 왜? 마지막인가, 마지막 layer가 많은 정보를 지니고 있기 때문에.
: 물론 모든 layer에 대해서도 영향력 파악 가능(gradient를 활용하는 것이기 때문에 다 가능) (하지만, 앞에서는 의미가 별로 없겠죠? - 정보가 별로 없기 때문에)
3-1-0) Overall Architecture
3-1-1) Importance of each feature map
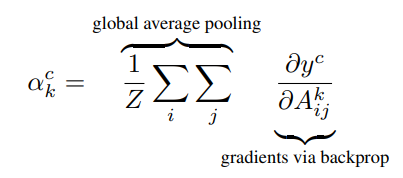
: y^c(class score-softmax 전단계)를 feature map으로 미분
: i,y는 각 해당 픽셀 위치값
: k는 몇 번 째 feature map인지
➡️ 즉, y^c를 해당 피처맵 A의 각 픽셀로 미분한 후에, GAP를 하면, 중요도 가중치를 얻게 됨
= k번째 피처맵이 y^c라는 score map에 미치는 영향력을 의미
= 모델의 예측(y)에 어느 feature map(k)가 평균적으로 어느 정도의 영향을 미쳤는가를 의미함
※ y^c는 꼭 class score일 필요 없이 미분 가능한 downstream task면 된다고 함
3-2-2) Weighted Combination
: 위에서 구한 가중치(영향력)에 k번째 feature map을 곱해준 후 합친 후, ReLU 사용
: 예를 들어, 곱한 값이 음수의 값을 지닌다면, 그 값은 제외하고 양수 부분만 가지고 시각화를 하겠다
: 즉, 우리는 개에 대한 label을 classification 해야 하는데, 음수 값이라면 사람 or 배경에 대한 피처맵을 말하는 것임.
3-2-3) Weighted Combination
①
: 왼쪽) 기존 CAM의 수식 , 가중치 x GAP한 feature map
: 가운데) k번째 피처맵에 대해 각 픽셀의 합을 가중 평균한 값
: 오른쪽) 대체한 결과 식
②
: 왼쪽) Y^c class score을 F^k 피처맵의 평균으로 미분한 값
: 가운데) F^k를 A^k에 대해 미분하면 1/Z만 남음. 이를 왼쪽에 대입하면 오른쪽과 같은 식이 됨
: 오른쪽) 이 때, Y^c를 대입해서 F^k에 대해 미분 최종 식을 구함
③
: 왼쪽) 각 픽셀에 대해 연산
… 미안합니다… 마지막 가서 이해를 못했어요 (왜 저 합이 Z인 것인가..)
➡️ 결과적으로 얘가 말하고 싶었던 건 CAM 방식과 같다는 것임
: CNN의 마지막에 GAP 방식을 사용하면 결과적으로 CAM과 같음 (= 논문에서는 CAM의 generalization이라고 말함)
: Grad-CAM은 gradient 기반으로 weight를 구하기 때문에, GAP이 없는 어떠한 구조에서도 visualization이 가능함
(CAM은 GAP 통해서 weight를 구하는 반면, Grad-CAM은 gradient(역전파)통해서 구함))
3-2) Guided Grad-CAM
: Grad-CAM은 class 구분(class-discriminative)이 가능하며 예측된 관련 이미지 지역을 찾아낼 수는 있으나, pixel-space gradient visualization은 어려움
: 즉, 왜 tiger cat으로 예측했는지를 알아낼 수 없음.
Guided Backpropagation
: backpropation 하기전에 feature map에서 0 이하인 부분을 제거 함으로써 positive value만을 이용하여 backpropagation value를 추출
: 음수에 해당하는 gradient를 사용하지 않음으로써 깨끗한 이미지를 추출하는 방법
: class-discriminative는 하지 않으나, 특징들은(고양이 줄무늬, 귀, 눈)에 대한 정보는 잘 나타냄
➡️ Grad-CAM + Guided Backprop = Guided Grad-CAM
왼쪽 부분이 Guided Grad-CAM을 나타낸 것
: Guided Backprop과 Grad-CAM 간 element-wise 곱을 통해 합성
: Guided Backprop은 픽셀 단위여서 input 크기와 동일한 반면, Grad-CAM은 feature map 단위이기 때문에, 크기를 맞춰주기 위해 bilinear interpolation으로 up-sampling 해줌
: 저 두 개를 곱셈해주면 Guided Grad-CAM이 됨
3-3) Counterfactual Explanations
: Grad-CAM을 약간 수정하여 네트워크의 예측을 변경시키는 영역을 강조하는 설명을 얻을 수 있음
: 위와 동일하게, 설명력을 중시하는 느낌이고 이러한 피처맵이 왜 부정적으로 영향을 끼치는지에 알고자 할 때 사용하는 식임
: 고양이를 예측할 때, 가장 부정적으로 영향을 주는 친구 찾는 것
: -1, -1, 1로 feature map wieght가 주어졌을 때, -1을 취하고 ReLU 통과시키면 1,1,0이 됨
: 결국, 고양이라고 예측하는 것에 도움을 주지 않는 부분만이 남게 되는 것임
4 Evaluating Localization Ability
Weakly-Supervised Segmentation
Diagnosing Image Classification CNNs with Grad-CAM
: VGG-16이 분류를 실패한 케이스들에 대해 실제 라벨과 예측된 라벨의 Guided Grad-CAM을 그려본 결과
: 잘못된 예측을 파악하는데 도움이 됨
Image Captioning
: 이미지에 대한 설명에 초점을 맞춰 시각화 한 모습
Visual Question Answering
: VQA pipeline은 이미지를 처리하기 위한 CNN과 question을 위한 RNN language model로 이뤄져 있음