1. Intro
- Class Imbalance란→ 분류 문제에서 각 클래스의 샘플 수가 불균형한 상황을 의미함.→ 이진 분류 문제에서 한 클래스에 대한 샘플 수가 다른 클래스에 비해 매우 적은 경우(class imbalance), 이러한 문제가 발생.
- → 예를 들어, 질병 유무를 판단하는 분류 문제에서, 건강한 사람이 대부분이고, 질병을 가진 사람의 수가 매우 적다면(class imbalance), 이러한 문제가 발생함.
- → 즉, 한 클래스에 속한 샘플 수가 다른 클래스에 속한 샘플 수보다 월등히 많거나 적은 상황을 말함.
- 논문에서는 배경영역(easy negative)이 대부분이라 학습에 끼치는 영향력이 커져서 모델 성능이 하락한다고 말함
※ 추가 내용
: 객체 검출 모델에서는 이미지 내에서 객체가 있는 부분(=foreground)과 객체가 없는 부분(=background)을 분류해야 함.
이때, foreground와 background의 비율이 매우 불균형하다면(class imbalance), 모델이 background로 분류하는 경향이 강해지며, foreground를 정확히 검출하지 못하는 문제가 발생할 수 있음.
- Two-statge-Detector 두 가지 측면에서 해결책 사용.첫 번째, region proposals을 통해 background sample을 걸러줌.ex) positive/negative sample의 수를 적절하게 유지하는 sampling heuristic 방법 적용- hard negative mining, OHEM 등
- ex) selective search, edgeboxes, deepmask, RPN 등
- One-statge-Detector region proposal 과정을 없애고 이미지 전체를 sampling 하는 deance sampling 사용
- 따라서 더 많은 후보 영역이 발생하고, class imbalance 문제가 더 심각함
- 따라서 One-stage-Detector에서도 class imbalance 문제를 해결하자! 해서 나온 방법이 Focal loss. 이를 통해 해결 (RetinaNet)
2. Idea
- class imbalance를 해결하기 위해 기존의 cross entropy loss를 reshaping하는 방법을 제안.
- 즉, 잘 분류되는 애들(well-classified examples, easy sample)에게 더 작은 가중치(dwon-weights)를 주는 방법이 있음.→ 예를 들면 배경이 더 잘 분류되기에 더 작은 가중치를 부여.
⇒ 이게 바로 Focal Loss
- 많은 easy negative에 영향 가는 것을 막음 ( 배경들에게는 가중치 부여 적게 )
- 작게 분포되어 있는 hard example에 집중 ( 실제 객체 있는 친구들에게 더 )

- 최고당!
3. Focal Loss

- cross entropy (CE)를 바탕으로 시작함
- ground truth class에 대해 0,1로 분류함, label과 동일한 경우 1

- y=1일 때, p이고, 그 외의 경우엔 1−p.
- 따라서 CE(p,y)의 식을 다시 써서, CE(pt) = −log(pt)라고 표기함.
3.1 Balanced Cross Entropy
- 여기서 y에 상관없이 pt > 0.5 이면 Confidence가 높으므로 Loss가 크게 줄어드는데, 문제는 쉽게 분류가 잘 돼서 0.5를 넘기기 쉬운 Background나 class들이 너무 많이 Loss를 줄여버리게 됨.
⇒ 이렇게 되면 적게 있는 클래스가 Loss에 미치는 영향을 압도하게 함

- 여기서 α는 각 클래스별로 가중치를 조절하는 역할을 함.
- 이때 손실 함수에서 모든 클래스를 동등하게 취급하면 모델이 학습을 제대로 하지 못하는 문제가 발생함.
- 따라서, Focal Loss에서는 이러한 클래스 불균형 문제를 해결하기 위해 손실 함수의 가중치를 조절.
- α는 각 클래스별로 가중치를 지정하는데, 손실 함수에서 적게 등장한 클래스(정답 클래스 - positive) 에 대해서는 가중치를 높게 주어 모델이 이를 더욱 잘 학습할 수 있도록 함.
- 즉, negative(객체 무) class 의 샘플 수가 1000개, positive(객체 유) class의 샘플 수가 100개라면 이는 클래스 불균형임.
- 그렇기에 100개에 대해서 가중치를 더 줘서 불균형을 해결하고자 하는 방법을 정의.
⇒ 즉, loss에 미치는 영향 정도만 조정할 뿐, easy/hard sample 들에 대한 loss 반영은 하지 못했음
⇒ Scaling Factor 등장
3.2 Focal Loss Definition

- 쉽게 분류되는 neagative(배경)은 loss의 대부분을 차지. gradient를 지배함
- α balance는 easy example과 hard example 사이를 구별할 수 없음.
- 이때 easy example과 hard example은 positive class라고 말할 수 있음
- 객체가 있는 class 중에서 쉽게 검출할 수 있거나 아님 검출하기가 어려운 예시를 말함.
- 쉬운 예제와 어려운 예제 사이에는 손실 값의 차이가 크게 나지 않아서, Focal Loss에서 사용하는 가중치 조절 방법으로는 해결할 수 없음⇒ 즉, easy sample 에 대해 가중치를 낮춰서 hard example에 더 집중하는 손실함수를 재설정하는 것을 제안함
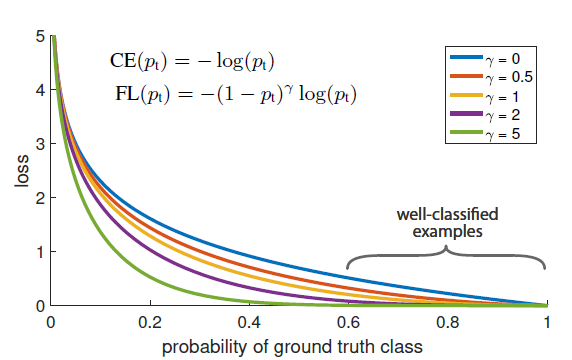
- ⇒ CE에 (1−pt)^γ를 곱해줌
(1) pt 와 modulating factor와의 관계

- pt(모델이 예측한 확률값) 이 작을 경우, FL은 1에 가까워지며, loss에 영향을 받지 않음
- pt(모델이 예측한 확률)이 1에 가까워질 경우, FL은 0으로 수렴함 ( 이미 얘는 좋은 모델 )⇒ Focal Loss에서 값이 0으로 수렴할수록 easy example에 대한 가중치는 낮게, hard example에 대한 가중치는 높게 설정됨⇒ 이에 반해 Focal Loss는 값이 0으로 수렴할수록 easy example에 대한 가중치를 감소시켜서 모델이 hard example에 더욱 집중적으로 학습하도록 유도함.
- ⇒ Focal Loss는 기존의 교차 엔트로피 손실(Cross Entropy Loss)에 대한 보완적인 역할을 하는데, 기존의 손실 함수는 easy example에 대한 가중치와 hard example에 대한 가중치를 모두 동일하게 적용.
(2) focusing parameter γ의 역할
- 파라미터 γ은 easy example의 가중치가 작아지는 비율을 더 부드럽게 조정해줌.
- γ가 0일 때, FL은 CE와 동일하면서 γ이 증가함에 따라 Scaling factor의 영향이 커짐.
- FL는 easy example의 가중치(기여도)를 줄이고, example이 작은 loss를 받는 범위를 확장시키는 기능을 함. ( 즉, pt가 커질수록 더 작아지는 loss를 갖는다고 생각하면 됨 ex) 100배 ⇒ 1000배 와 같이 loss는 작아지되 범위는 확장 시킴의 의미로 파악)
- 예를 들어 γ=2, pt=0.9일 때, CE에 비해 100배 적은 loss를 가지며 pt=0.968일 때는 1000배 적은 loss를 가짐
- 이는 잘못 분류된 example을 수정하는 작업의 중요도를 상승시킴을 의미. (hard example에 가중치를 더 주겠다)
- γ=2일 때, 가장 효과적.

- loss layer의 구현은 p 를 계산하기 위한 sigmoid 연산과 loss 계산을 결합하여 더 좋은 성능을 가져온다는 점에 주목
3.3. Class Imbalance and Model Initialization
- 기존 binary classification model은 label이 0 또는 1일 확률이 같도록 초기화됨
- 즉, 이렇게 초기화를 하고, 불균형 현상이 나타나면 더 많은 class가 total loss에서 더 많은 비중을 차지하게 되므로 초기부터 학습이 불안정해짐 (애초에 배경과 관련된 box가 더 많이 생성되어있으므로 클래스 불균형임)
- 이를 해결하기 위해 prior 이라는 개념의 p항을 사용하게 됨
- 즉, FPN의 레이어는 총 5개이고, Prior 항은 이러한 각 레이어에서 사용되어, 이전 레이어에서 계산된 출력값들을 이용하여 현재 레이어의 파라미터 값을 초기화함.
- p항이라는 것은 penalty의 개념과 같은 것을 말함 다시 말해, 물체가 없는 배경 anchor box에 더 많은 패널티를 부과한다고 생각하면 됨. → 매칭되지 않는 anchor box의 비율을 낮춤
- p항을 낮게 설정될수록 객체와 매칭되지 않는 anchor box들의 비율을 낮추는 역할을 함.
- 이를 통해, 모델이 배경과 같은 클래스에 대해서는 덜 민감하게 예측하고, 객체가 있는 클래스에 대해서는 더 민감하게 예측하도록 유도
3.4. Class Imbalance and Two-stage Detectors
- Two-stage Detectors 는 보통 cross entropy loss 를 사용하고 알파-밸런싱은 사용하지 않음.
- 대신 클래스 불균형 문제를 해결하기 위해 2가지 메카니즘을 사용함.
(1) two-stage cascade
1번째 cascade stage 는 object proposal mechanism 으로 거의 무한대의 가능한 오브젝트의 위치를 1~2천개 정도로 줄임
선택할 proposals 은 물론 랜덤한 것이 아니라 true object location 에 가까운 것
그렇게 함으로써 대부분을 차지하는 easy negatives 를 제외할 수 있음.
(2) biased minibatch sampling
2 단계 학습에서는, biased sampling 으로 minibatch 를 구성.
positive/negative 비율을 알파-밸런싱 factor 와 비슷하게 샘플링.
ex)
클래스 A와 클래스 B가 있는 데이터셋이 있을 때, 클래스 A에 대한 샘플링 비율을 0.5, 클래스 B에 대한 샘플링 비율을 0.1로 설정한다면, 클래스 A의 샘플은 클래스 B의 샘플보다 더 많이 선택될 것임.
이러한 방식으로 구성된 minibatch로 학습을 수행하면, 불균형한 데이터셋에서도 모델이 적은 클래스를 잘 학습할 수 있음.
4. RetinaNet Detector

- 하나의 backbone network + 두가지(class,box)subnetwork 존재※ 여기서 backbone이란?
- → 전체 input image에 대한 convolutional feature map의 연산을 하는 기능을 함. 그냥 convolutional network를 말하는거로 보면됨.
- first subnet은 backbone의 output(anchor box)에 대한 object를 classification하는 역할
- second subnet은 anchor box와 GT(Ground Truth) Box를 비교하는 regression의 연산을 수행
4.1 FPN(Feature Pyramid Network Backbone):


- FPN에 대한 설명 참조
- ResNet구조에 FPN을 backbone으로 사용
- FPN은 top-down pathway와 lateral connection을 사용하여 multi-scale feature pyramid를 생성함
- pyramid의 channels의 수는 256으로 설정
4.2 Anchors:
- three aspect ratios 1:2;1:1,2:1
- IoU threshold of 0.5
- [0, 0.4)의 IoU는 background라고 판단
- [0.4, 0.5]의 IoU를 가지는 Anchors Box는 학습 도중에 무시됨
4.3 Classification Subnet:
- Anchor box 내에 object가 존재할 확률을 predict
- subnet은 FPN level 옆에 붙어있는 작은 FCN(Fully Convolution Network).
- subnet의 파라미터는 pyramid level에서 공유됨
- 3x3 컨볼루션을 256 개의 필터로 컨볼루션하고 ReLU 활성함수를 적용. 이것을 4회반복 (x 4)
- 마지막으로 KA(K*A) 개의 필터로 conv 실행
- 이진 분류이므로 마지막에는 sigmoid activations 적용됨
- C=256, A=9를 사용함
- box regression subnet 파라미터와 매개변수 공유 안함
4.4 Box Regression Subnet:
- Classification Subnet과 같이 각 FPN level에 작은 FCN을 붙임
- Anchor box 의 offset 4개 (center x, center y, width, height)를 GT박스와 유사하게 regression 진행
- class-agnostic bounding box regressor 사용
- 즉, 입력 이미지에서 발견된 모든 객체에 대해 동일한 경계 상자로 예측함
- 여러 객체가 있을 경우, 하나의 상자로 묶어서 예측함
- ex) 자동차와 사람이라는 두 개의 객체가 있을 경우, 일반적으로는 자동차와 사람에 대한 경계 상자를 예측한다면, 이 친구는 두 개에 대해서 한꺼번에 경계 상자 1개만을 만듬⇒ 이렇게 되면 매개변수가 적어지는데, 적어짐에도 기존에 쓰던 regressor과 동일한 효과를 냄!
- 마찬가지로 class subnet 파라미터와 매개변수 공유 안함
5. Inference and Training
• FPN level에서 box prediction 점수가 높은 1000개의 box만 result에 사용하고 최종 detection에 NMS를 적용해 속도 향상을 시킴
5.1 Focal Loss:
- class sub의 output으로 Focal loss를 사용
- gamma = 2, alpha = 0.25일 때 가장 좋은 결과가 나옴
5.2 Initialization:
- FPN의 initialization은 FPN 논문과 같은 값으로 진행
- RetinaNet subnet에서 마지막 layer를 제외한 모든 conv layer는 bias=0, gaussian weight fill = 0.01로 초기화
- classification subnet의 마지막 conv layer는 bias=-log((1-pi)/pi)로 초기화
5.3 Optimization:
- SGD 사용
- LR = 0.01, 90000번 학습을 진행.
- 60000번 일때 LR 10 나누고, 80000번 일때 LR 10 나
- weight decay = 0.0001, momentum = 0.9
- class predict은 focal loss, box regression은 smooth L1 loss 사용
6. Experiments



7. Conclusion
- one-stage의 가장 주요한 obstacle이었던 class imbalance문제를 해결하기 위해 Focal Loss를 제안하였고, 성능을 입증.
- SOTA를 달성
8. Reference
'Deep Learning > [논문] Paper Review' 카테고리의 다른 글
| U-Net (0) | 2023.07.05 |
|---|---|
| Bert (0) | 2023.07.05 |
| VIT [AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE] (0) | 2023.07.05 |
| GPT-1 (0) | 2023.07.05 |
| DeepLab V2: Semantic Image Segmentation with Convolutional Nets, Atrous Convolution and Fully Connected CRFs (0) | 2023.07.05 |



