728x90
반응형

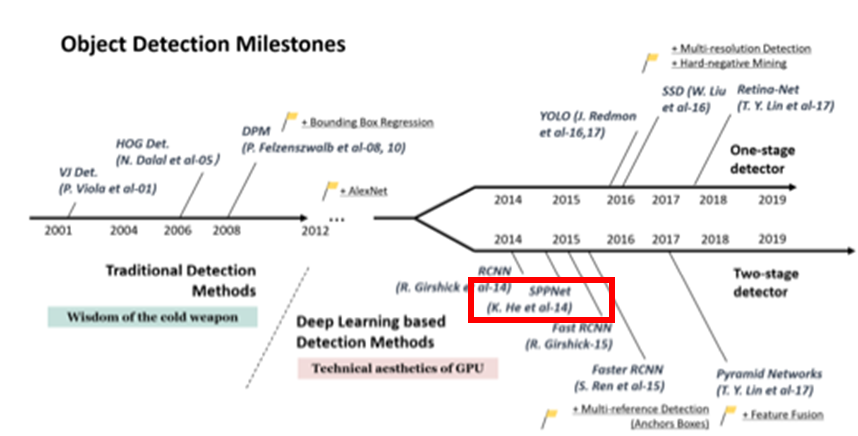
1. Intro
- 기존에서는 고정된 크기의 이미지를 input으로 받았음
- 왜? : FC layer에서 고정길이 벡터만 받을 수 있기 때문
- 문제점? : 크기가 다 다른 이미지를 한 사이즈로 통일해버리기 때문에 이미지의 왜곡이나, 아래 사진과 같이 잘리거나 이미지가 고장남.
- 하지만? : 사실 FC layer에 들어가기 전까지는 사이즈가 제각각 이어도 괜찮음
- 그래서? : 이번 논문에서는 이러한 문제점을 보완한 “Saptial Pyramid Pooling layer”를 설명.

- CNN은 Convolutional layer + fc layer로 이루어져 있음
- 이때 conv의 경우, sliding window 방식으로 이동하기 때문에 이미지 크기를 신경쓰지 않아도 모든 크기의 feature map을 생성함 (옆으로 이동하면서). 따라서 고정이 필요없음
- 반면 fc의 경우, 정의된 법칙에 따라 고정 크기/길이가 input으로 들어와야 함.
- 따라서, CNN 제약은 FC에서만 발생함.
- (그래서 논문에서는 conv + spatial pyramid pooling + fc layer)의 순서로 진행함.
2. Overall architecture
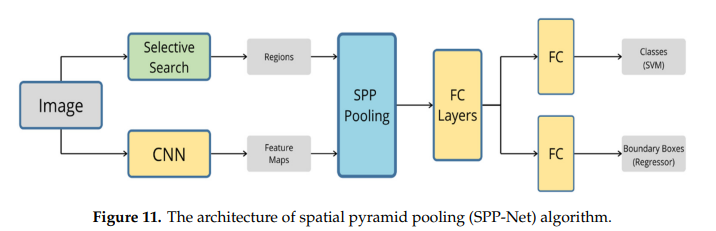
- Selective Search
- input image를 가지고 selective search 진행
- image 안에 객체가 있을법한 후보군들을 2000개 선정함
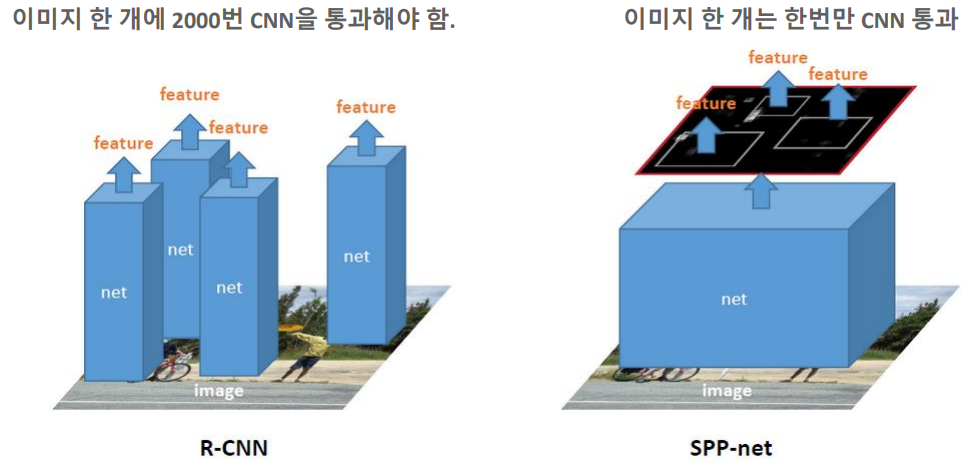
- CNN
- input image 한 장을 그냥 CNN 구조에 넣어버림 (conv+pooling의 반복 구간)
- CNN 계층 반복하다가 마지막 부분에서의 풀링을 SPP pooling으로 바꿔버림
- SPP Pooling
- 앞에서 추출한 2000개의 영역을 가져옴.
- 이후, 4*4 , 2*2, 1*1 크기의 max pooling을 진행함.
- 진행해서 1차원 벡터 크기로 이어 붙여줌
- 그렇게 되면 총 21개의 bin이 나옴. (고정크기의 벡터가 될 것임
- 이후 얘네를 FC layer에 집어넣음. (가중치 o)
- FC layer에 한 번씩 더 넣고 SVM을 통해 해당 벡터에 객체의 유무(classification) 진행
- 추가적으로, Boundary Boxes Regressor 진행해서 bounding box의 크기를 알맞게 조정(객체 위치에 있는 곳으로)한 후, non maximum suppression을 통해 최종 bounding box를 선별!
3. Spatial Pyramid Pooling Layer

- 앞에서 selective search를 통해서 추출한 영역인 ROI (window) (max 2000개)를 활용함

- 이후, 한 영역에 대해서 사진을 4*4, 2*2, 1*1로 분할함.
- 그다음 1차원 벡터 (1줄로 붙여버림)로 만들어서 고정크기의 벡터로 만듬.
- 총 최대 2000개의 1차원 벡터가 나오는 것을 확인할 수 있음
- 얘네들을 FC layer에 넣어서 가중치 곱해서 값 추출
4. SVM
- 객체가 있는지 없는 지를 분류해주는 classification
- FC안에 관련 정보가 들어있을 것임 ( 해당 위치 정보 같은 )
- SVM을 활용해서 해당 fc를 통해 뽑은 정보에 객체가 있나 없나를 분류
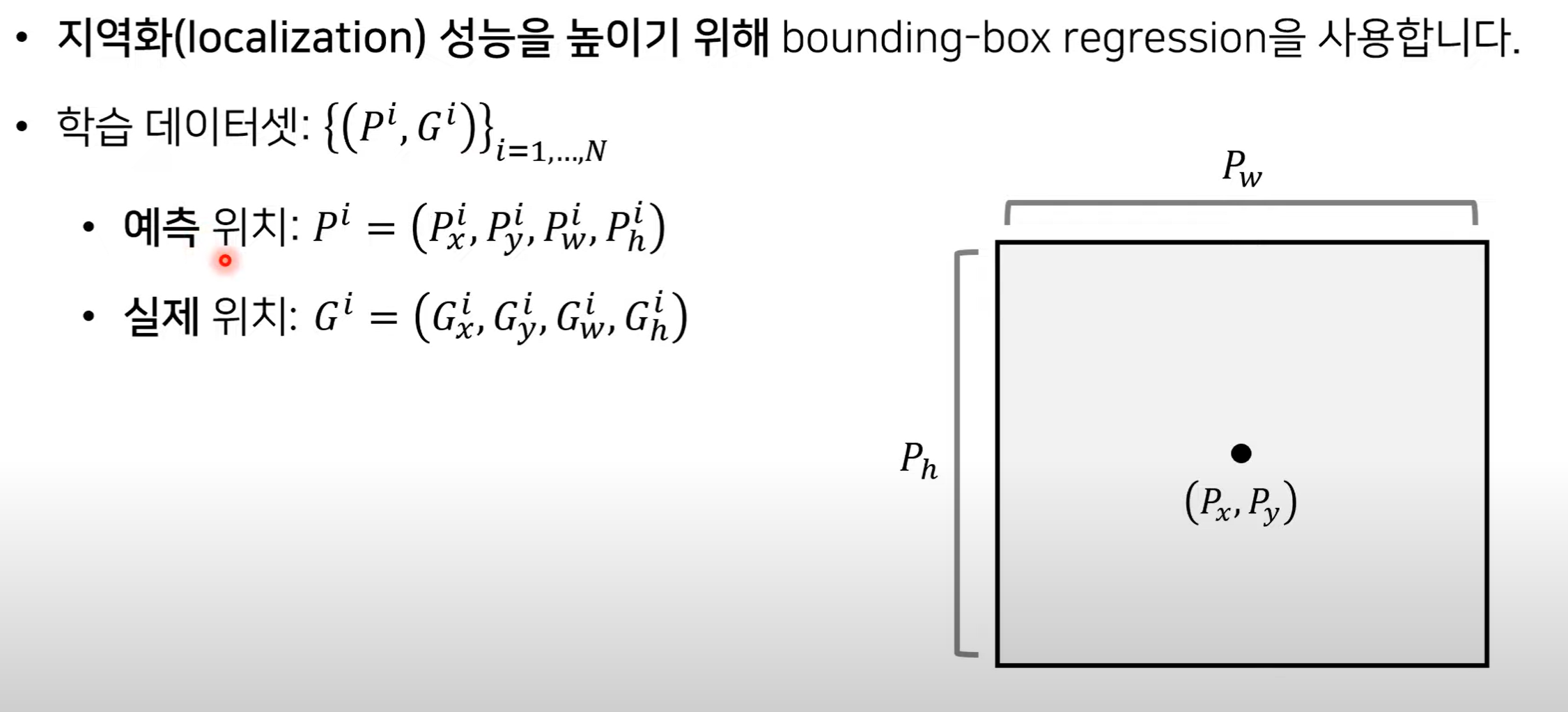
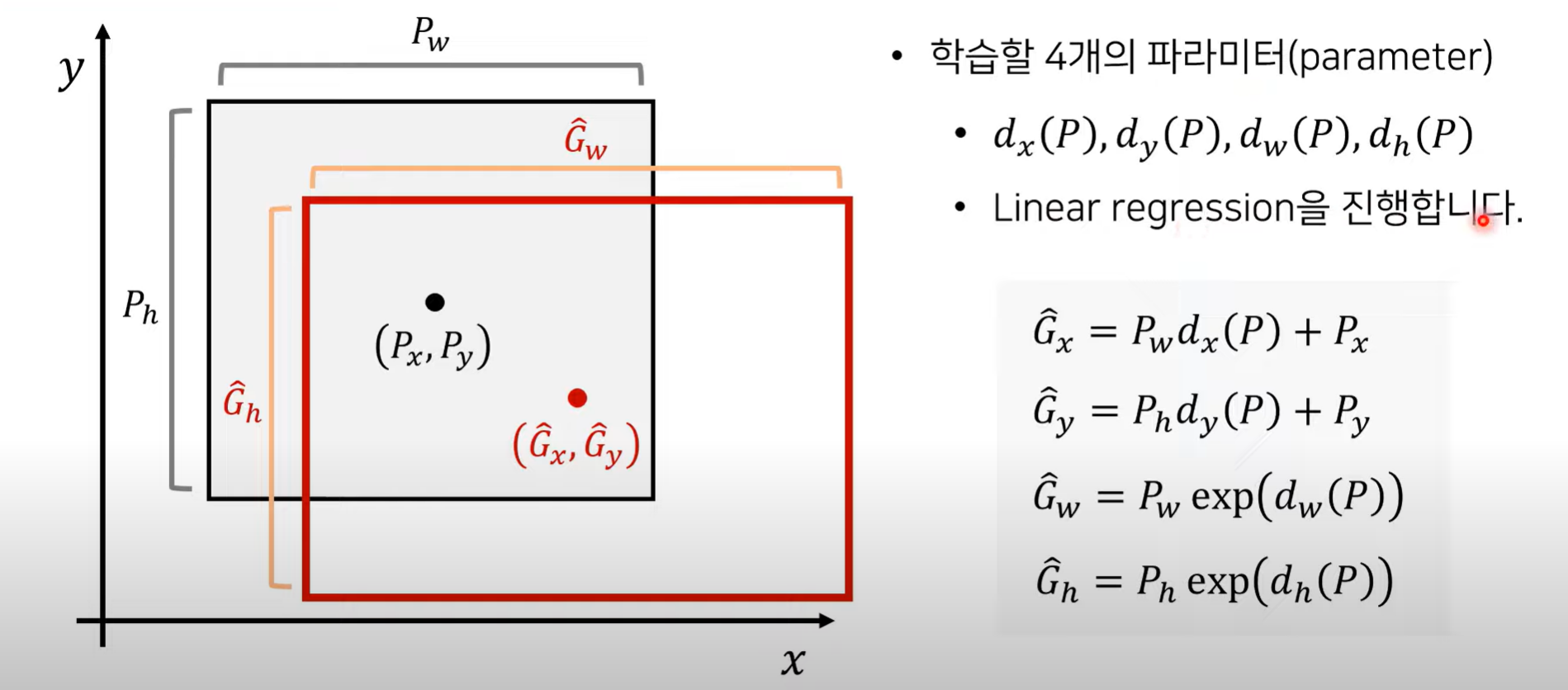
5. Boundary Boxes Regressor
- 실제 위치와 예측한 box 위치 간의 차이를 좁혀주는 역할
- 즉, predicted box가 ground truth box와 유사하도록 학습 시킴
- G: 학습 데이터에서 가져온 이미지
6. Outro

- R-CNN의 경우, 2000개를 뽑고 적정 크기 (227x227)로 warping 해줬음(projection) → 이게 바로 문제점!
- 그래서 SPPNet의 경우, 크기 조정을 하지 않는다
- R-CNN과 달리 하나의 이미지가 통째로 들어감 ⇒ 속도 빠름
- back propagation이 안됨 (가중치는 FC)에만 존재함
- fine tuning 시에 spp를 거치기 이전의 conv 레이어들을 학습시키지 못함. fc layer만 학습시킬 수 o
- e
nd-to-end 가 아님 ( 입력에서 출력으로 한번에 연결이 안된다는 뜻) 사실 잘 모르겟음
7. Reference
https://bkshin.tistory.com/entry/논문-리뷰-SPP-net-톺아보기
https://rahites.tistory.com/78
https://inhovation97.tistory.com/68
https://inhovation97.tistory.com/68?category=997272
https://n1094.tistory.com/30
https://blackchopin.github.io/imagerecognition/Pyramid_pooling/
https://velog.io/@whiteamericano/R-CNN-을-알아보자
https://velog.io/@syj1031/SPPNet-paper-review
https://mainpower4309.tistory.com/27
https://better-tomorrow.tistory.com/entry/Bounding-box-regression
728x90
반응형
'Deep Learning > [논문] Paper Review' 카테고리의 다른 글
| GAN: Generative Adversarial Nets (0) | 2023.07.06 |
|---|---|
| AE (0) | 2023.07.06 |
| Faster R-CNN (0) | 2023.07.06 |
| YOLO: You Only Look Once: Unified, Real-Time Object Detection (1) | 2023.07.06 |
| Fast R-CNN (0) | 2023.07.06 |



