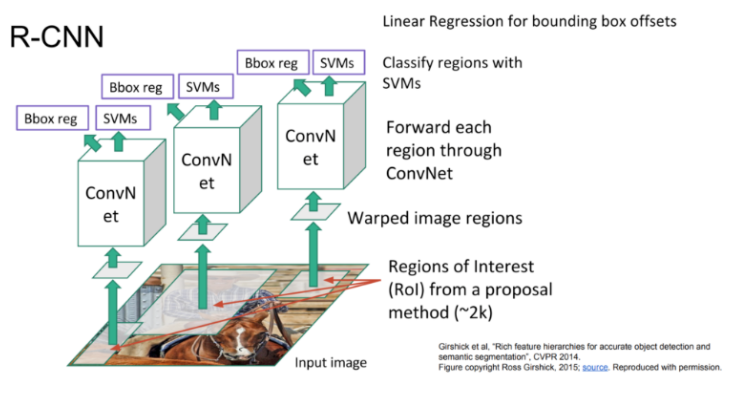
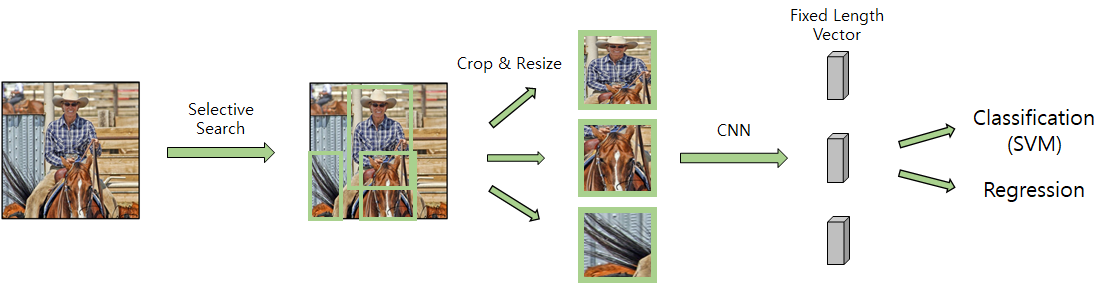
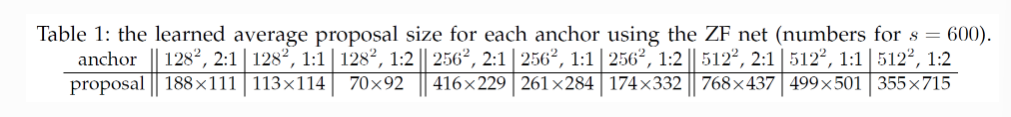입력 이미지에 Selective Search 알고리즘을 적용하여 bounding box(region proposal) 2000개를 추출.
추출된 bounding box를 warp(resize)하여 CNN에 입력.
fine tunning 되어 있는 pre-trained CNN을 사용하여 bounding box의 4096차원의 특징 벡터를 추출.
추출된 특징 벡터를 SVM을 이용하여 class를 분류.
bounding box regression을 적용하여 bounding box의 위치를 조정.
non maximum supression을 진행
⇒ 이 친구의 문제점:
1) 개느림
2) 들어갈 때 이미지 크기를 고정시키기 때문에 이미지 왜곡됨
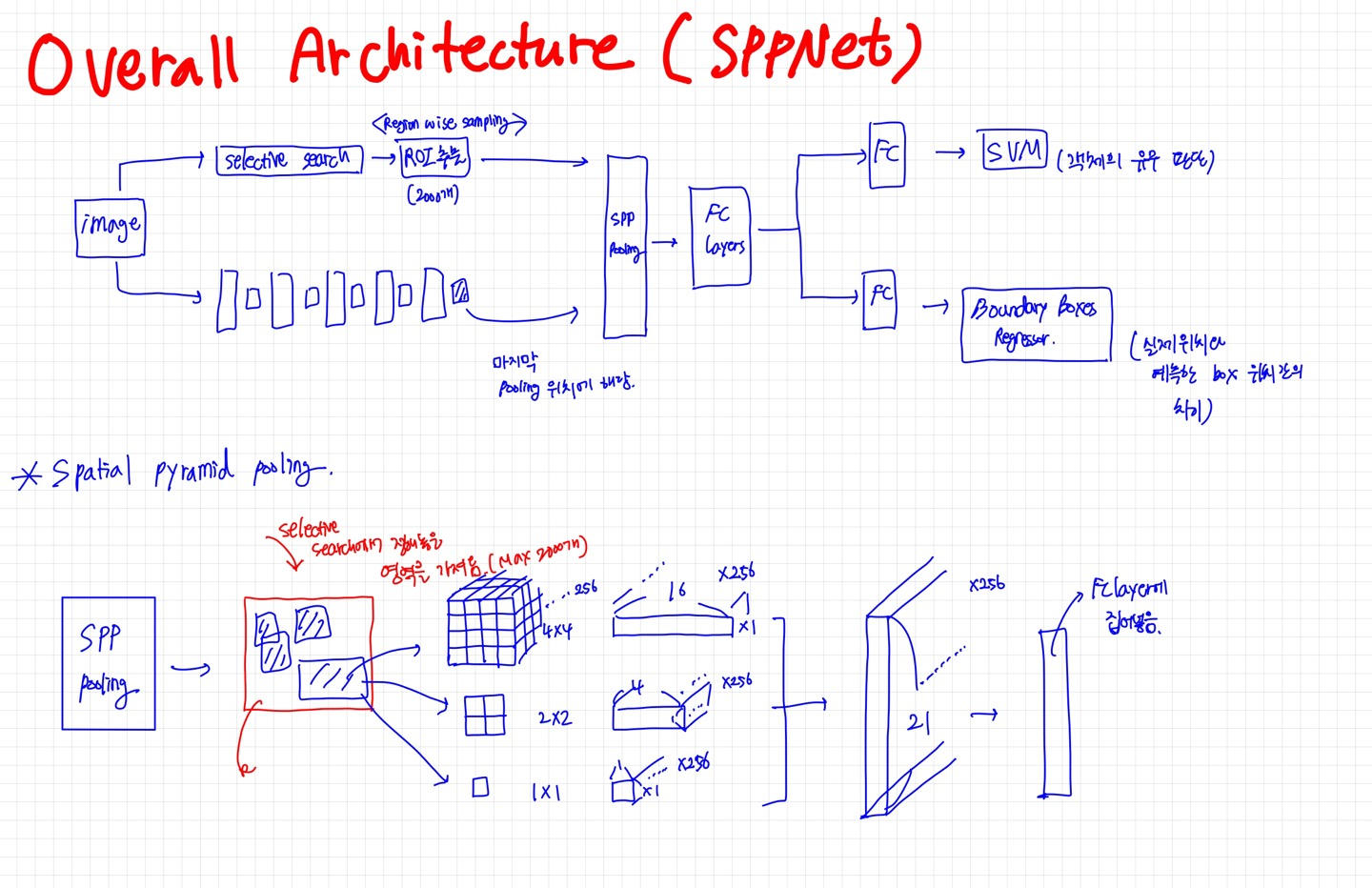
0. SPPNet
R-CNN의 단점을 해결하기 위해 나온 친구⇒ 최대 2000번 연산을 단 한번으로 줄임⇒ 시간단축
⇒ input 이미지 크기 조정 안함 ⇒ 왜곡현상 없앰
Selective Search
input image를 가지고 selective search 진행
image 안에 객체가 있을법한 후보군들을 2000개 선정함
CNN
input image 한 장을 그냥 CNN 구조에 넣어버림 (conv+pooling의 반복 구간)
CNN 계층 반복하다가 마지막 부분에서의 풀링을 SPP pooling으로 바꿔버림
SPP Pooling
앞에서 추출한 2000개의 영역을 가져옴.
이후, 4*4 , 2*2, 1*1 크기의 max pooling을 진행함.
진행해서 1차원 벡터 크기로 이어 붙여줌
그렇게 되면 총 21개의 bin이 나옴. (고정크기의 벡터가 될 것임
이후 얘네를 FC layer에 집어넣음. (가중치 o)
FC layer에 한 번씩 더 넣고 SVM을 통해 해당 벡터에 객체의 유무(classification) 진행
추가적으로, Boundary Boxes Regressor 진행해서 bounding box의 크기를 알맞게 조정(객체 위치에 있는 곳으로)한 후, non maximum suppression을 통해 최종 bounding box를 선별!
→ 이 친구의 문제점:
1) 3단계의 구조를 지님 (selective search, CNN, SVM)
2) 4x4 2x2 1x1 spatial bin으로 인해 오버피팅 발생 가능성 올라감
3) 용량 많이 필요
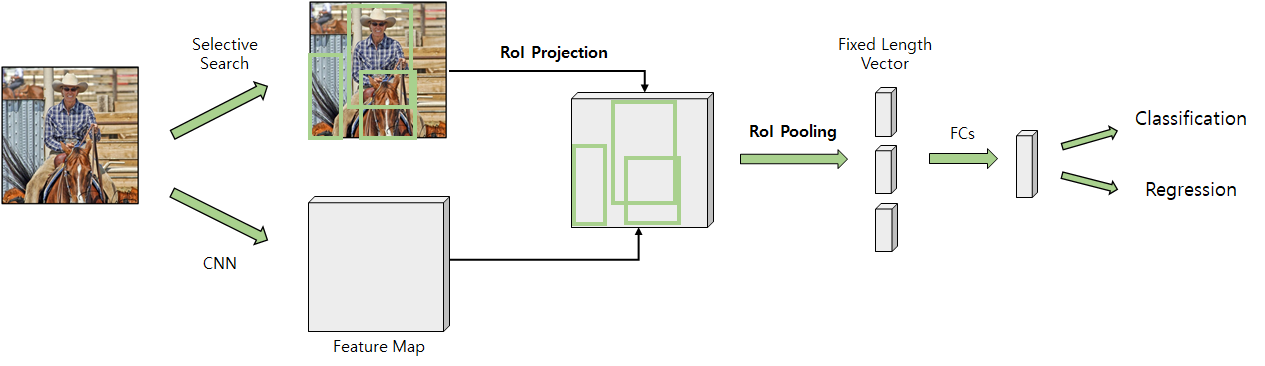
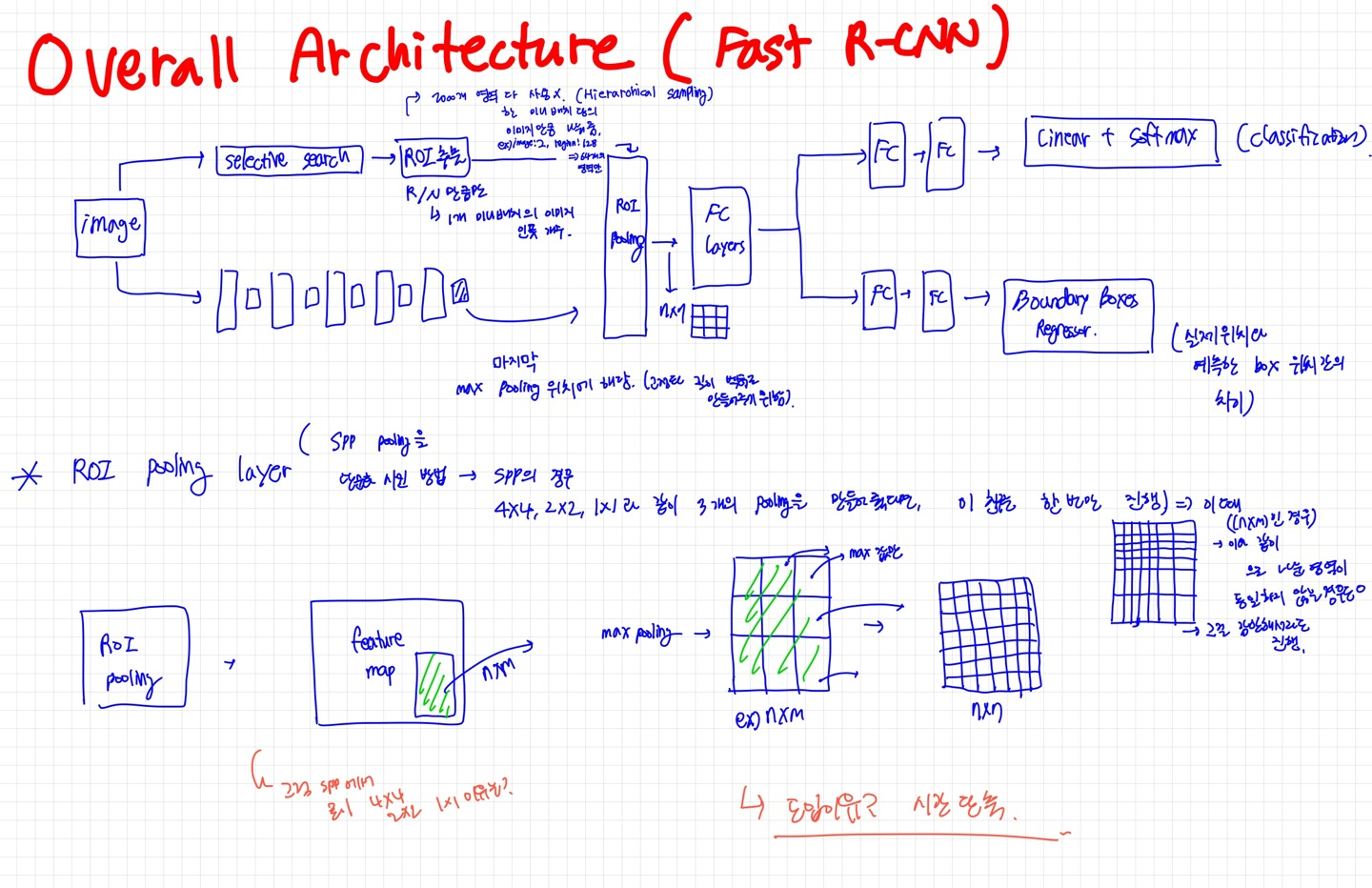
0. Fast R-CNN
그래서 나온 친구가 fast R-CNN
Selective Search
input image를 가지고 selective search 진행
image 안에 객체가 있을법한 후보군들을 최대 ex) 2000개 선정함
ROI 영역 추출⇒ 이 때 2000개의 영역을 다 사용하지 않음(Hierarohical sampling)이라고 함ex) input image가 2개고, region이 128로 잡았다면 64개의 영역만 후보 영역으로 가져감
⇒ 한 미니 배치 당의 이미지만큼 나눠준 애들만 사용한다
CNN
input image 한 장을 그냥 CNN 구조에 넣어버림 (conv+pooling의 반복 구간)
CNN 계층 반복하다가 마지막 부분에서의 풀링을 ROI pooling으로 진행함
ROI pooling⇒ SPP pooling을 단순화 시킨 방법⇒ max pooling을 사용해 7x7 feature map 추출해서 고정 크기 벡터로 만듬
그걸 감안해서라도 진행 (시간 단축)
** add) ROI의 후보 영역 크기들이 다 다양하기 때문에, 예를 들어 nxm 와 같이 정사각형이 아닌애들의 경우 7x7의 영역으로 쪼개는 과정에서 크기가 다를 수도 있음
⇒ SPP의 경우, 4x4 2x2 1x1과 같이 3개의 pooling 방법을 사용했다면, 이 친구는 한 번만 진행했음
FC Layers
이후, FC layer을 한 번 거치고, 두 개의 갈래로 나눔
각각 FC layer을 두 번 더 거치고 1) classification 2) Boundary boxes regression 진행
Loss Function
이 친구의 경우, classification loss와 bbox regressor loss를 섞어서 종합적인 loss를 구함
이 loss값을 이용해 역전파를 진행함** classification: softmax로 얻어낸 확률값과 정답값에 대한 loss
⇒ smooth L1은 빠른 속도로 loss를 0으로 수렴한다는 특징을 지님 (속도 빠르게)
** localization loss는 x,y,w,h에 대한 예측값과 groundtruth(실제 정답값)의 조절을 통해 계산해서 smooth L1 함수를 통과한 값이라고.
→ 이 친구의 문제점:
R-CNN과 SPPNet보다는 성능이 좋으나, test 결과를 봤을 때, region proposal 과 selective search를 진행할 때 시간 비중이 큼 (시간 오래 걸림)
1. Intro
그래서 나온게 Faster- RCNN
Region Proposal을 GPU를 통해 학습하자! 해서 RPN( Region Proposal Network)가 추가된 친구
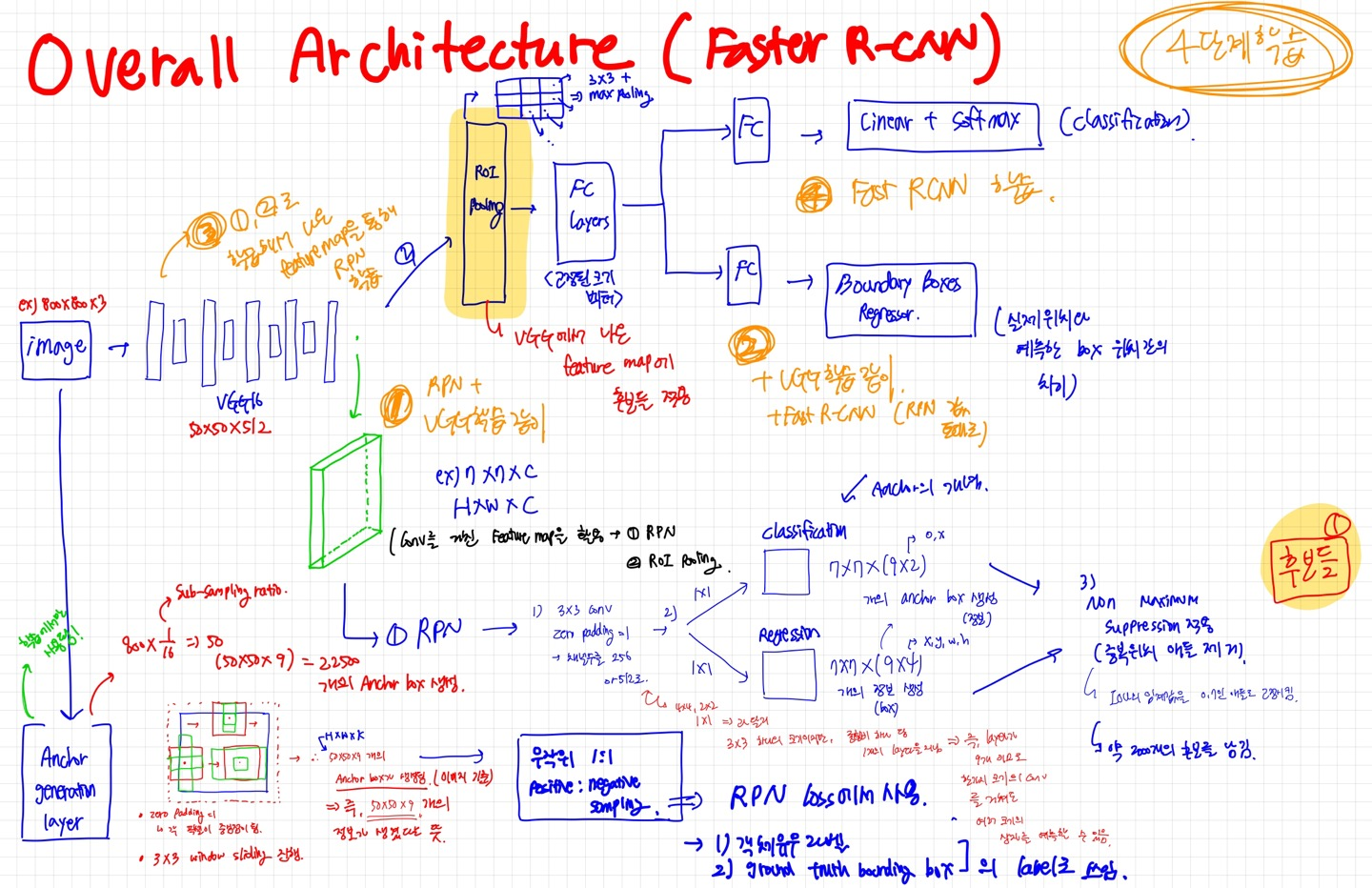
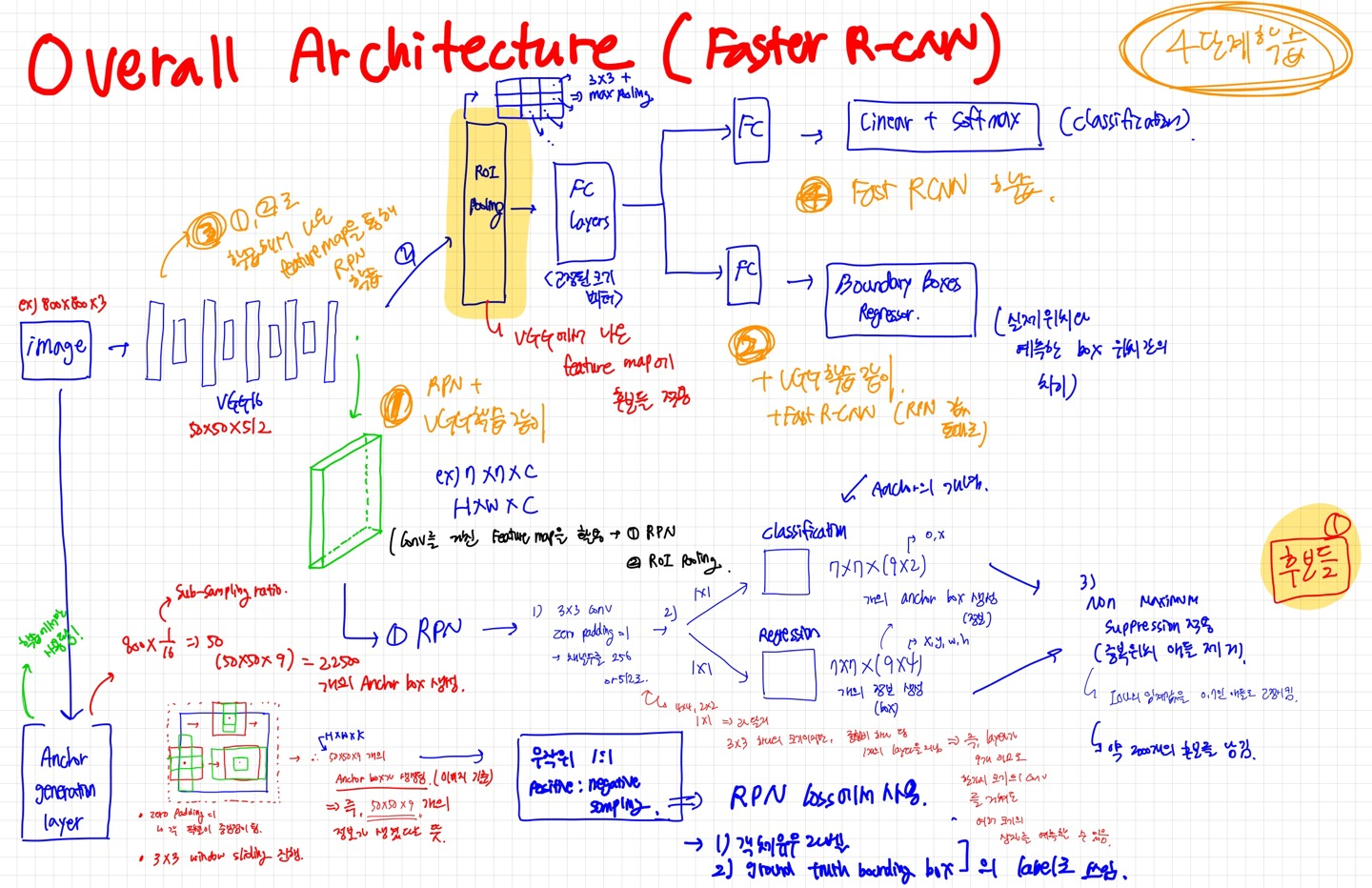
2. Overall Architecture
이미지를 pre-trained 된 VGG에 집어넣음
피처맵 추출
추출한 피처맵을 3x3, padding=1로 추출 (채널 수를 256 or 512)
두 갈래로 나눠서 1x1 conv 진행 (압축의 개념)
Classification 진행 ( Anchor 개념이 여기서 쓰임)
ex) Hxwx2k 개의 anchor box가 생성됨 (2: 객체의 유무에 대한 벡터)
Bounding box regression 진행 ( Anchor 개념 사용)
Hxwx4k 개의 anchor box가 생성됨 (4: x,y,w,h 좌표에 대한 벡터 정보들)
⇒ Non maximum suppression을 적용 ( 많은 후보들 중 중복된 영역들 제거 → 시간 단축)
⇒ 총 2000개의 ROI만 이용(학습시)
⇒ 2000개에서 더 줄인 상위 N개만 후보로 선출(평가시)
5번과 6번을 통해 후보들이 추려짐
이 추려진 영역들을 가지고 ROI Pooling을 진행함
VGG에서 나온 피처맵에 후보 영역들을 사용
후보 ROI에 해당하는 부분만 3x3 max-pooling을 통해 고정된 크기의 벡터 추출
FC layer에 각자 집어넣음
이후, sofmax를 활용해 classification 진행 및 boundary box regression 진행 후 예측
3. Training
3-1. pre-trained VGG-16
pre-trained된 VGG16 모델에 800x800x3 크기의 원본 이미지를 입력하여 50x50x512 크기의 feature map을 얻음.
3-2-1. Anchor generation layer
학습에 사용하기 위해 사용된 친구(미니배치 Loss에서 target 값으로 사용)
객체 유무 라벨 값
ground truth bounding box⇒ 의 라벨값으로 쓰임
※ 미니 배치에는 RPN에서 예측한 각 앵커가 실제로 객체를 포함하는지 여부를 나타내는 라벨과 해당 앵커를 예측하는 데 사용되는 ground truth bounding box가 포함됨
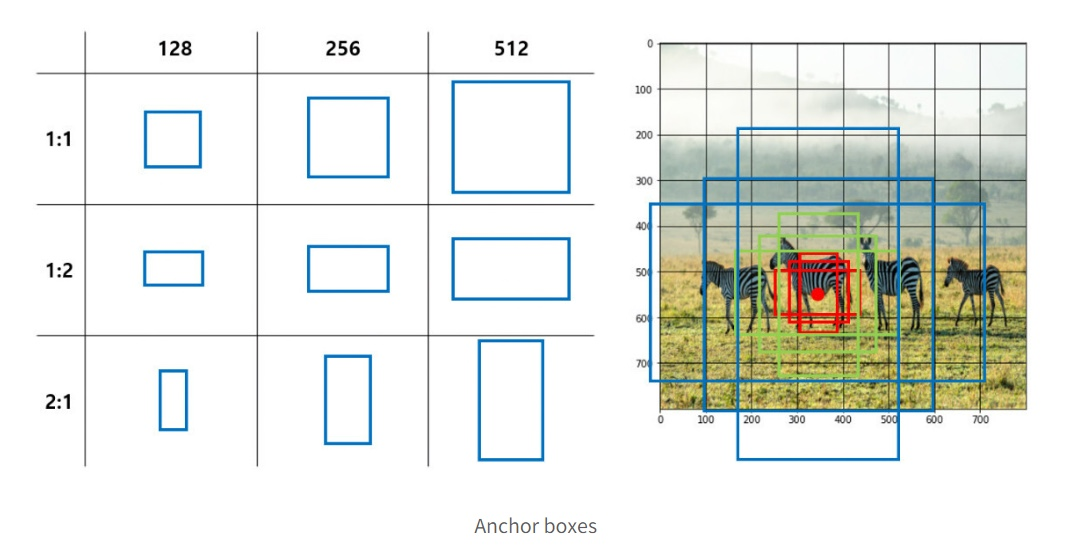
Anchor?
‘닻’을 의미
배가 움직이지 않게 하고, 배가 어느 위치에 있는지를 확인하는 기준
즉, anchor box는 object가 있음직한 기준의 역할을 함
sliding window 진행
⇒ 각 그리드에서 여러가지의 object를 검출할 수 있도록 도와줌
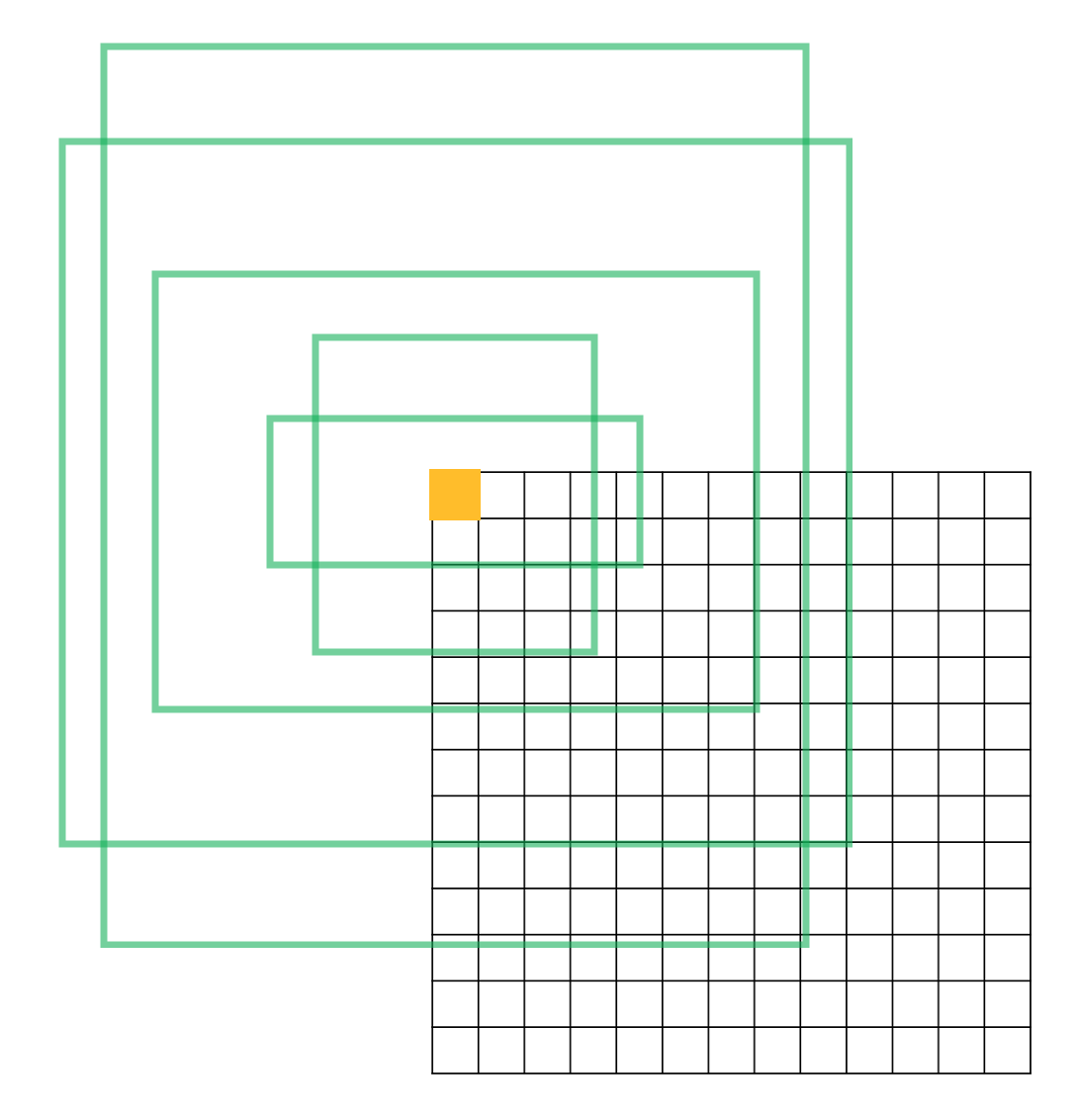
원본 이미지 크기에 sub-sampling ratio를 곱한 만큼의 grid cell이 생성됨(각 중심점)
각 grid cell 마다 9개의 anchor box를 생성
그러면 결국 생성되는 anchor box는 위의 예시는 50x50x9개가 생성됨
원본 이미지에서 sub-sampling ratio를 적용한 후, anchor box를 추출함
800 → 50으로 되었으므로, ratio는 1/16
즉, 800x(1/16) x 800x(1/16) x 9 ⇒ 50x50x9의 후보 anchor box들이 생성
샘플링된 애들 중, 양성과 음성 앵커 최대 1:1 비율로 맞춰서 미니배치 loss를 계산함
3-2-2. RPN
VGG를 통해 나온 feature map을 활용함
3x3 conv, zero padding(크기 유지)을 통해 채널 수를 256 or 512로 설정
이후, classification과 regression을 진행해서 후보 영역들을 고름
classification1) 1x1 conv를 통해 채널수 조정 (정보 압축의 개념)2) 아래의 예시 참고) 8x8x(2x9) 의 anchor box가 생성 ⇒ 채널수는 2x9 =183) 8x8x18의 후보 anchor box가 생성
boundary box regression1) 1x1 conv를 통해 채널수 조정 (정보 압축의 개념)
2) 8x8x(4x9)의 anchor box가 생성 ⇒ 채널수는 4x9 (4= x,y,w,h에 대한 정보)
⇒ non maximum suppression을 통해 중복 영역들 제거
⇒ 이때, IOU의 임계값을 0.7 이상인 애들은 postive anchor로 설정, 이하인 애들은 negative anchor로 고정한 채, NMS 적용 + 이미지의 경계를 넘어가는 애들도 지워버림 → 약 2000개의 영역들만 남김
※ 이렇게 하게 되면 학습된 RPN은 입력 이미지에서 객체를 포함할 가능성이 높은 anchor을 생성하게 됨
⇒ 후보 영역들을 ROI pooling의 학습에서 진행
3-3. ROI pooling
VGG에서 나온 feature map에 후보 anchor box를 적용시킴
이후 ROI pooling 진행 ( 3x3 구역으로 나눠서 max pooling)
고정된 크기의 벡터가 생성될 것임
3-4. Classification/Boundary Boxes Regression
고정된 크기 벡터를 두 갈래로 나눠 FC에 넣음
이후, softmax를 통해 classification 진행
bbox regression 진행
학습 진행
3-5. Loss function(RPN)
여기서 ground truth label 값 위에 원본 이미지에서 anchor box를 생성한 애들
i= 하나의 anchor을 의미
pi= classification을 통해 얻은 해당 anchor가 오브젝트일 확률
ti= bounding box regression을 통해 얻은 박스 조정 값 벡터
pi*, ti* = ground truth label값 (정답값)
classification의 경우, log loss 사용
regression loss의 경우, smooth L1 함수를 사용
※ smooth L1( huber loss)
⇒ L1 loss: 미분 불가능한 지점이 존재 (오차의 절댓값)
⇒ L2 loss: 이상치의 에러가 제곱됨 ⇒ 이상치에 취약함 (오차의 제곱)
이 둘의 단점을 보완한게 smooth L1
3-6. Sharing Features for RPN and Fast R-CNN
3-6-1. Alternating train
이 논문에서 학습시킨 방법
pre-trained된 VGG를 이용해 RPN을 학습시킴
위에서 학습시킨 애들을 Fast R-CNN 모델에 집어넣어서 처음 image- VGG - Fast RCNN 순서로 다시 학습시킴⇒ 이 경우, 그럼 VGG 모델(feature map)이 총 두 번이 학습되는 것임 ( 이때까지는 VGG conv값을 공유하지 않음)
1번과 2번을 토대로 해서 나온 VGG feature map을 공유.⇒ VGG(feature map)을 가지고 RPN을 한 번 더 진행한 후, ROI pooling에 후보 영역들을 집어넣음
ROI pooling에 넣은 후보 영역들을 학습시켜 Fast R-CNN을 한 번 더 진행
3-6-2. Approximate joint training
학습할 때, RPN과 Fast R-CNN을 합쳐서 바로 학습시킴
back propagation을 진행할 때, RPN과 Fast R-CNN의 loss를 합쳐서 역전파 진행⇒ 하지만 proposal box의 좌표값에 대한 미분값은 무시됨 ⇒ 그래서 approximate라고 표현한듯 (근데 rpn에서 box regression에 대한 정보를 받는데 왜 미분값이 무시되는건지 잘 모르겠음)
⇒ 학습시간 줄어들음
3-6-3. Non-approximate joint training
Fast R-CNN의 과정인 ROI pooling layer가 conv feature과 bounding boxes를 입력으로 받음⇒ box의 좌표도 gradient에 포함되도록 함⇒ 이 때는 미분이 가능한 ROI pooling Layer가 필요.
⇒ 즉, 위에 approximate joint training에서 무시되었던 것이 추가된 것
3-7. Step Alternating Training
pre-trained된 VGG를 이용해 RPN을 학습시킴 → 마지막 두개만 남김
위에서 학습시킨 애들을 Fast R-CNN 모델에 집어넣어서 처음 image- VGG - Fast RCNN 순서로 다시 학습시킴⇒ 이 경우, 그럼 VGG 모델(feature map)이 총 두 번이 학습되는 것임 ( 이때까지는 VGG conv값을 공유하지 않음) → 마지막 두 개를 다시학습시킴
1번과 2번을 토대로 해서 나온 VGG feature map을 공유.⇒ VGG(feature map)을 가지고 RPN을 한 번 더 진행한 후, ROI pooling에 후보 영역들을 집어넣음
ROI pooling에 넣은 후보 영역들을 학습시켜 Fast R-CNN을 한 번 더 진행
4. Test
4-1. pre-trained VGG-16
pre-trained된 VGG16 모델에 800x800x3 크기의 원본 이미지를 입력하여 50x50x512 크기의 feature map을 얻음.
4-2. RPN
VGG를 통해 나온 feature map을 활용함
3x3 conv, zero padding(크기 유지)을 통해 채널 수를 256 or 512로 설정
이후, classification과 regression을 진행해서 후보 영역들을 고름
classification1) 1x1 conv를 통해 채널수 조정 (정보 압축의 개념)2) 아래의 예시 참고) 8x8x(2x9) 의 anchor box가 생성 ⇒ 채널수는 2x9 =183) 8x8x18의 후보 anchor box 생성
boundary box regression1) 1x1 conv를 통해 채널수 조정 (정보 압축의 개념)
2) 8x8x(4x9)의 anchor box가 생성 ⇒ 채널수는 4x9 (4= x,y,w,h에 대한 정보)
⇒ non maximum suppression을 통해 중복 영역들 제거
⇒ 이때, IOU의 임계값을 0.7 이상인 애들은 positive anchor로 설정, 이하인 애들은 negative anchor로 고정한 채, NMS 적용 이미지의 경계를 넘어가는 애들은 클리핑(clipping)을 통해 box가 이미지 경계 내부에 위치하도록 만들어준다고 생각하면 됨(픽셀 값 조정 과 같은)
⇒
이후, 상위 N개의 영역으로 간추려서 ROI input으로 사용 (학습 시에는 이 과정이 없었음)
※ 이렇게 하게 되면 학습된 RPN은 입력 이미지에서 객체를 포함할 가능성이 높은 anchor을 생성하게 됨
⇒ 후보 영역들을 ROI pooling의 학습에서 진행
4-3. ROI Pooling
VGG에서 나온 feature map에 후보 anchor box를 적용시킴
이후 ROI pooling 진행 ( 3x3 구역으로 나눠서 max pooling)
고정된 크기의 벡터가 생성될 것임
4-4. Classification/Boundary Boxes Regression
고정된 크기 벡터를 두 갈래로 나눠 FC에 넣음
이후, softmax를 통해 classification 진행
bbox regression 진행
학습 진행
5. Experiments
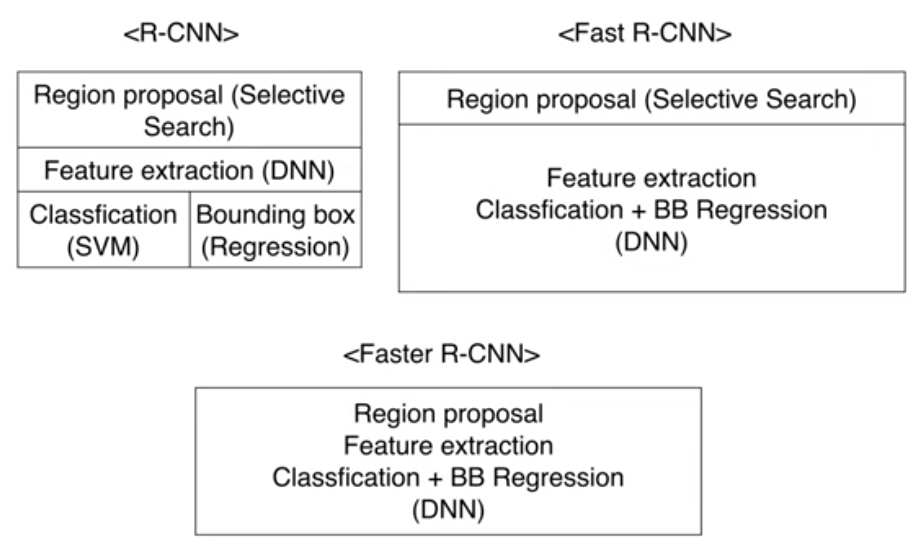
R-CNN vs Fast R-CNN vs Faster R-CNN
Faster R-CNN에서는 완전한 one stage를 만듬
즉, end to end 방식이라고 말할 수 있음 (r-cnn의 경우, selective search에서는 CPU를 사용을 하고, 뒷부분 부터는 GPU를 사용)⇒ 즉, 처음부터 GPU를 사용하냐 안하냐의 차이라고 말할 수 있음.
성능 훨씬 좋아짐
Selective Search → RPN
selective search를 RPN으로 대체 했을 때의 속도 차
SS의 경우, total 1.8s 중, proposal에서 1.5s가 소요됨 → 느리다!
Other experiments
초기 설정한 Anchor Box가 Scale과 Aspect ratio에 따라 학습된 후, 어떻게 변경 됐는가에 대한 평균
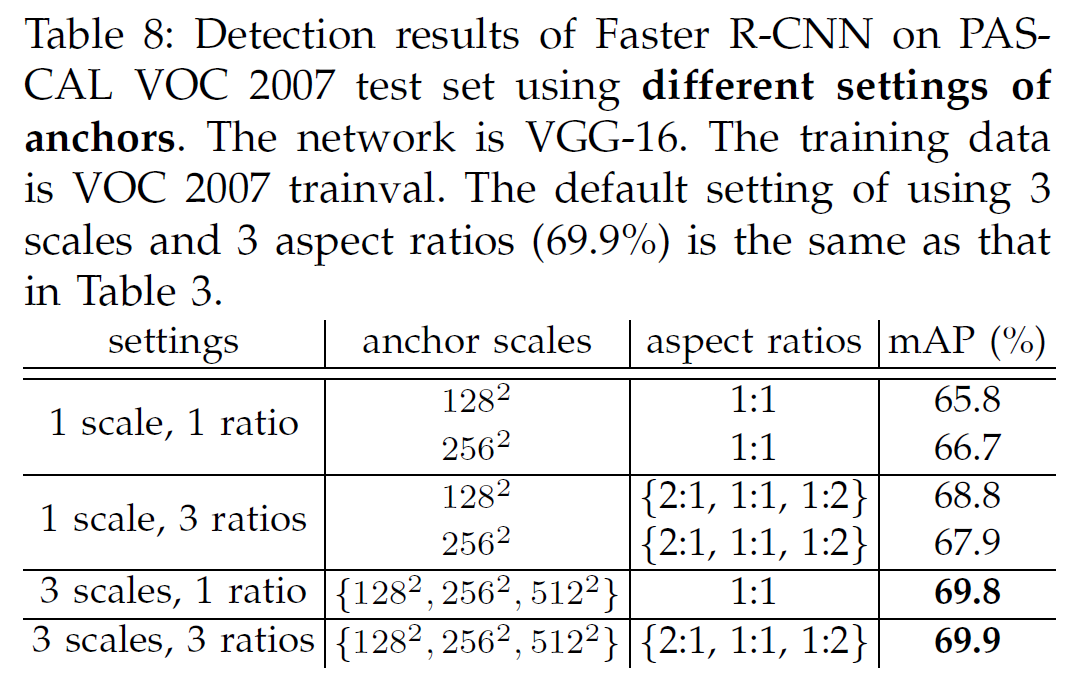
anchor box의 3가지 scale과 3가지 aspect ratio를 다른 경우의 수로 사용했을 때의 성능 비교
총 결과로써는 사실 별로 큰 차이가 없었음 (3가지 scale 과 1가지 aspect ratio, 3가지 aspect ratio를 사용해본 결과)
확장성을 고려해서 3가지 scale과 3가지 aspect ratio를 사용
loss function의 람다에 따른 성능 비교
사실 별 차이 없었음 ⇒ 람다의 영향력은 크지 않다!
+추가) 람다가 뭘 의미하는가?
※ 람다의 역할: 두 loss의 상대적인 가중치를 조절하는 하이퍼파라미터
ex) 람다= 10 ⇒ Lcls와 Lreg의 가중치는 1:10으로 조정
※ Faster R-CNN에서는 앵커박스가 대부분 배경에 해당하기 때문에, 객체 유무 판단이 bounding box regression보다 더 중요하다는 것에 기반을 둠. 따라서, 람다를 10으로 설정했을 때가 두 손실의 기여도가 균등하게 되는 것임!
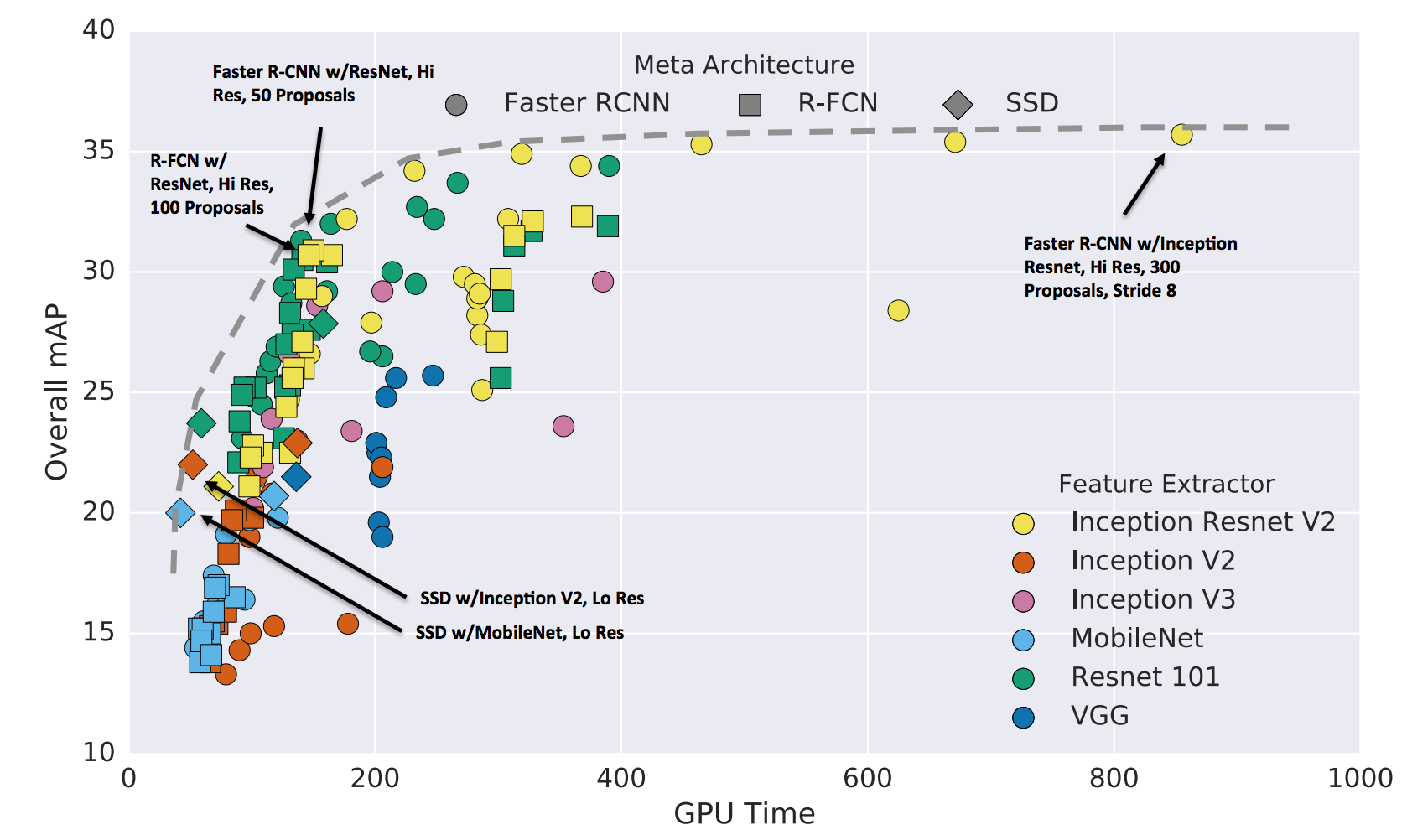
Faster R-CNN vs Others
Faster R-CNN이 MAP이 더 높고, GPU Time이 더 짧았음
6. Outro
CPU를 사용하던 selective search가 아닌 GPU에서 RPN을 사용한 Region proposal 진행. ⇒ 속도와 정확도 향상