728x90
반응형
1. Convolutional Neural networks
1. Convolutional Layer Stride
- 스트라이드(stride)
- 이미지를 슬라이딩 할 때 움직이는 step의 크기.


- 얘는 스트라이드 2
2. Convolutional Layer Pad
- 필터 크기에 따라서 출력 가로 세로 길이가 줄어듬
- padding을 쓰면 원본 크기 유지, 이미지 가장자리 계산 덜 되는 것을 막을 수 있음

3. Convolutional Layer Output Size
W: input image width
F: Filter width
S: Stride
P: Pad
Output W:(W - F + 2*P)/S + 1

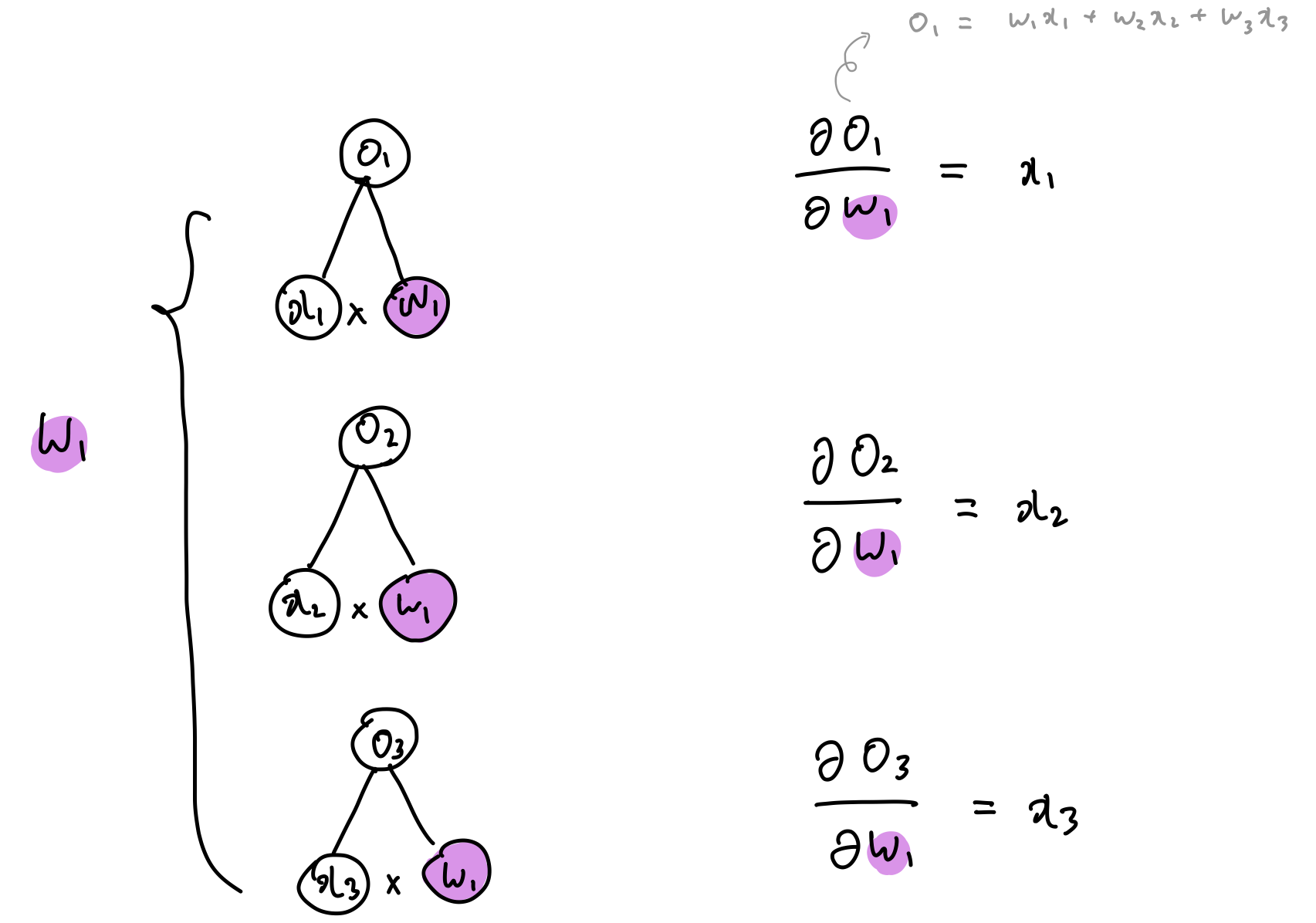
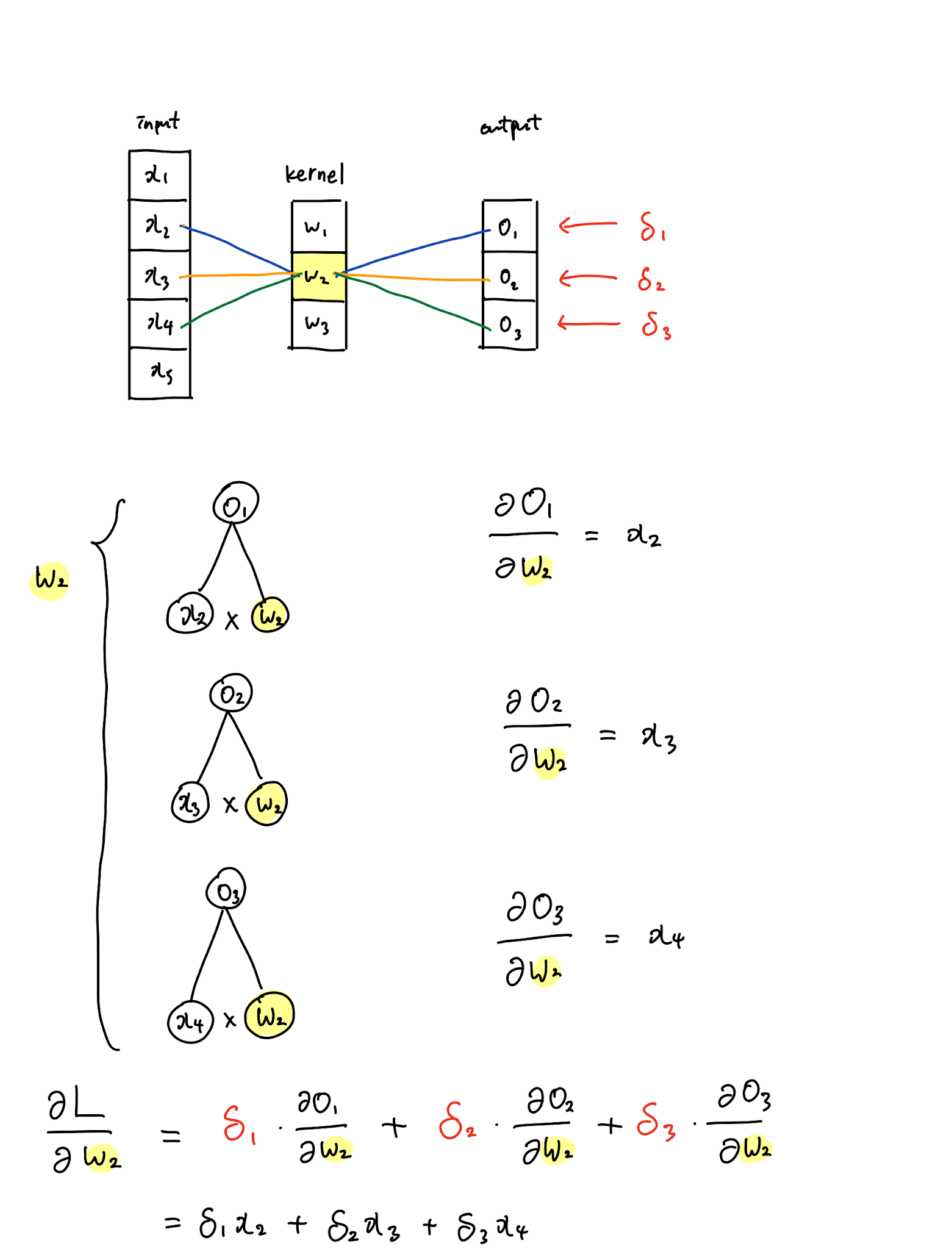
4. Convolution Layer의 Backpropagation
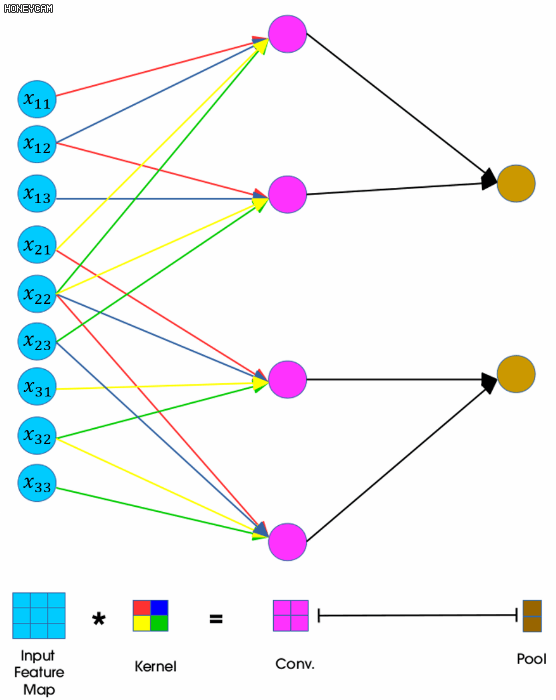
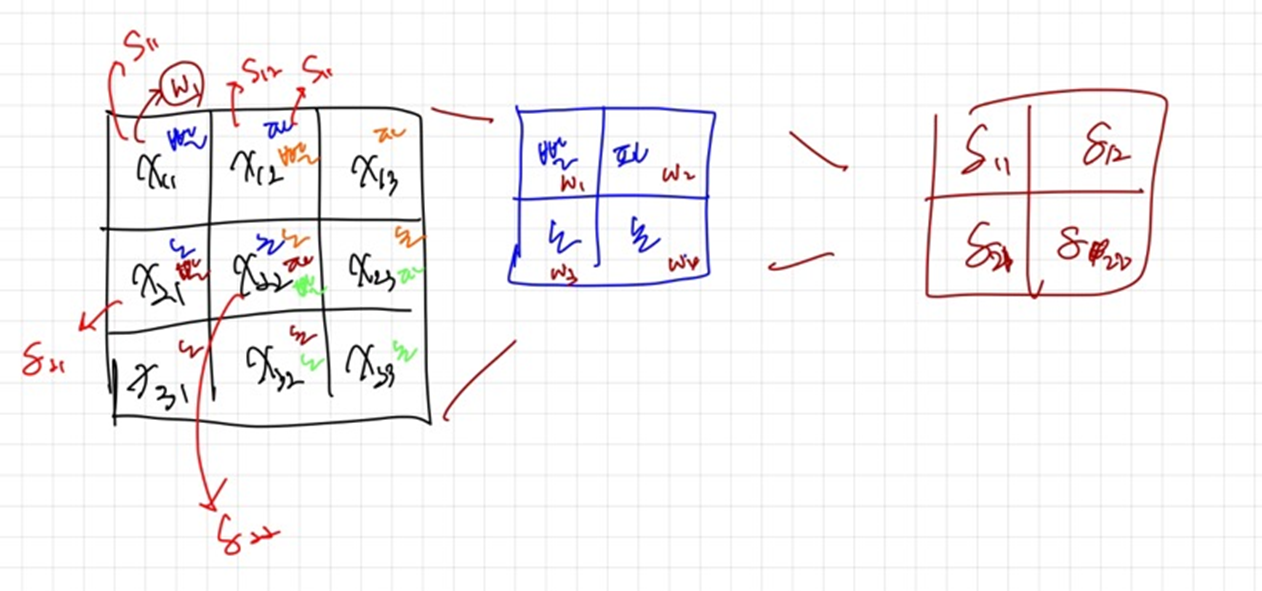
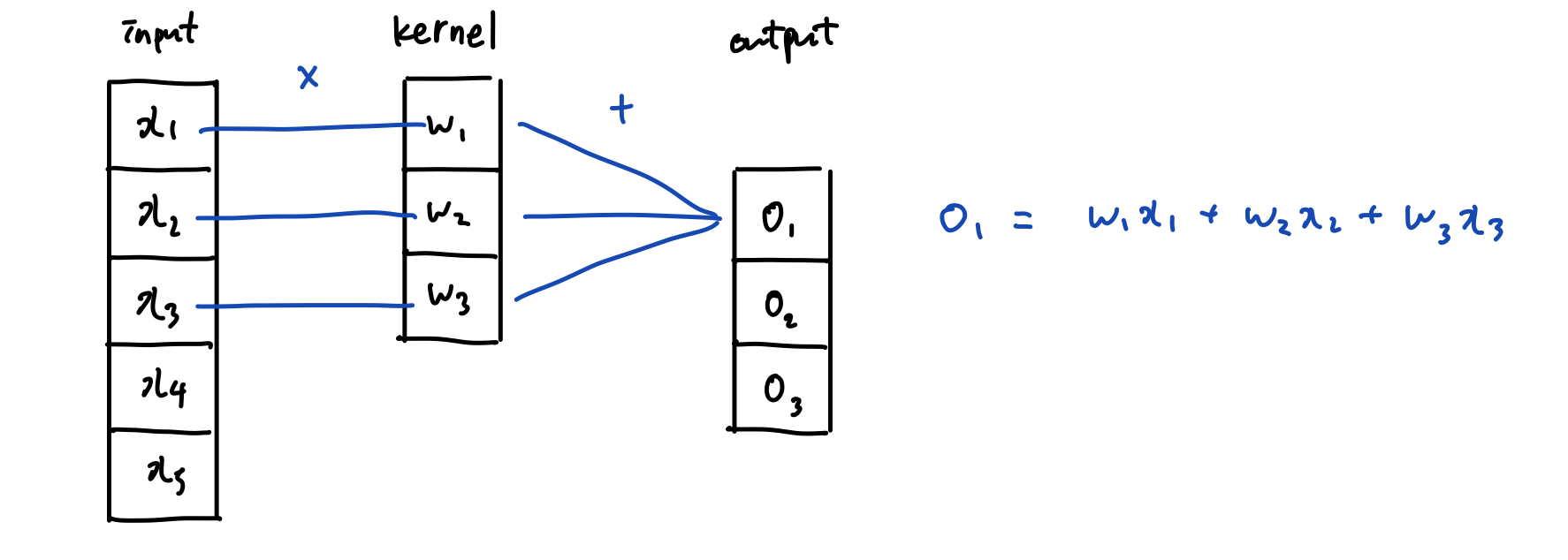
- 처음에 필터가 빨파노초 필터 이런식으로 가면
- x11의 경우 빨간색 필터만
- x12의 경우 파란색과 빨간색 필터
- x13의 경우 파란색만
- x22의 경우 빨파노초의 필터가 다 들어감
- 그럼 결국에 S11,s12,s21,s22의 값이 결정적으로 나오게 됨.
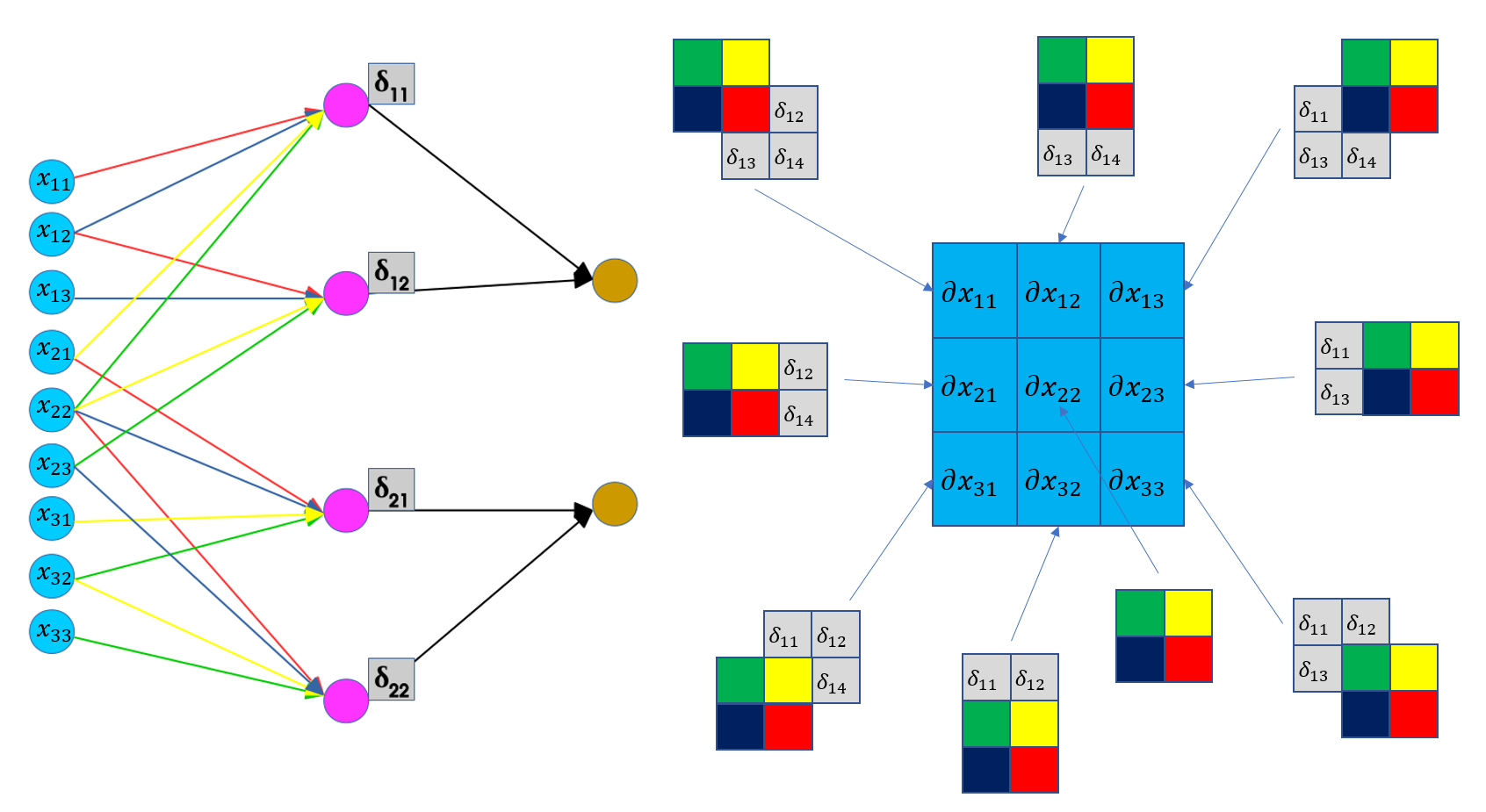
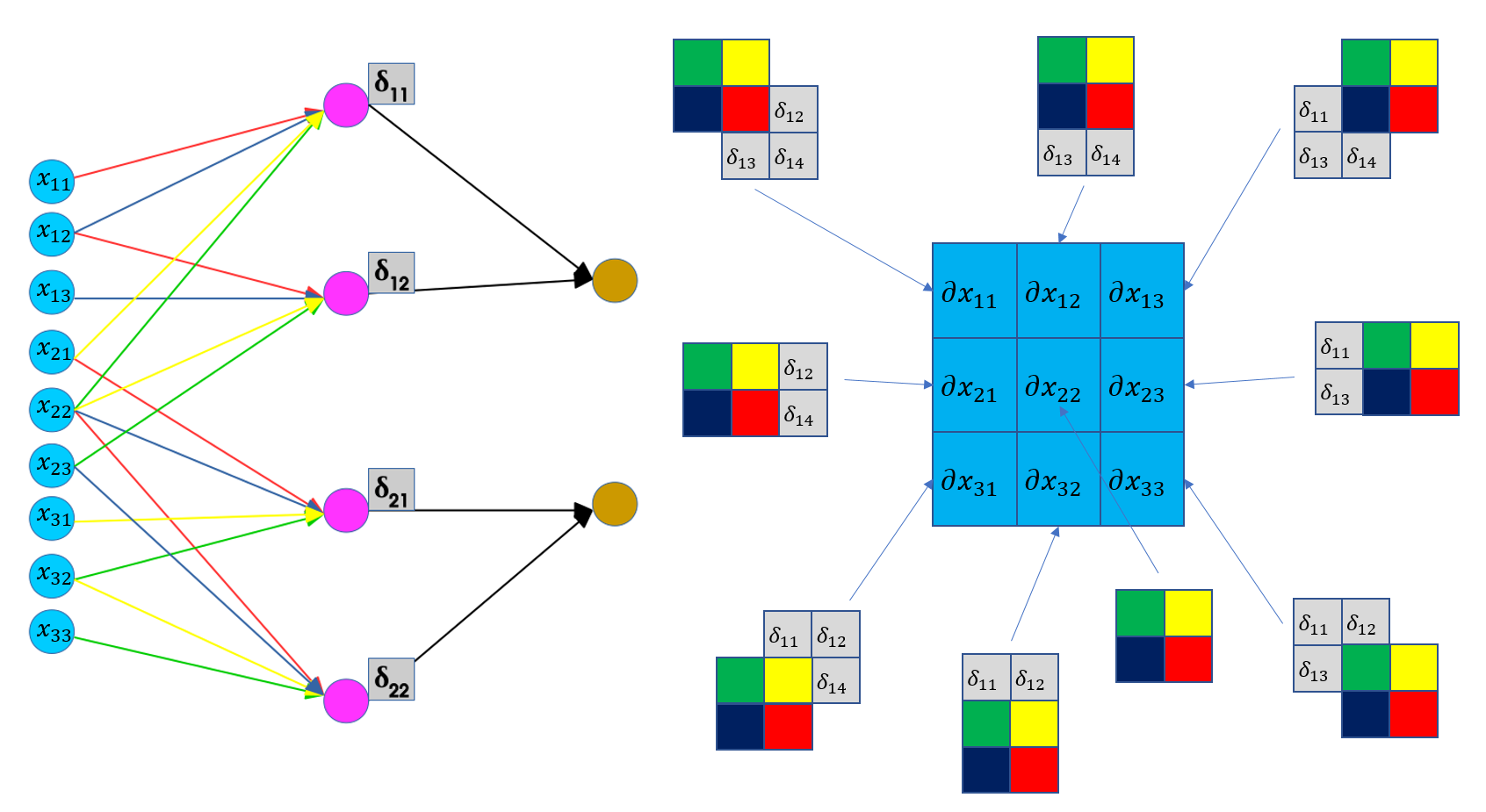
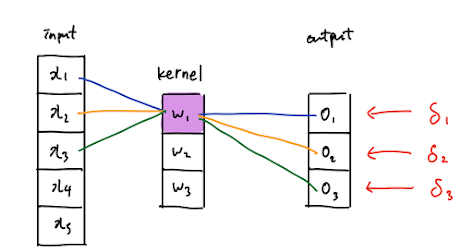
- 이를 역전파할 경우,
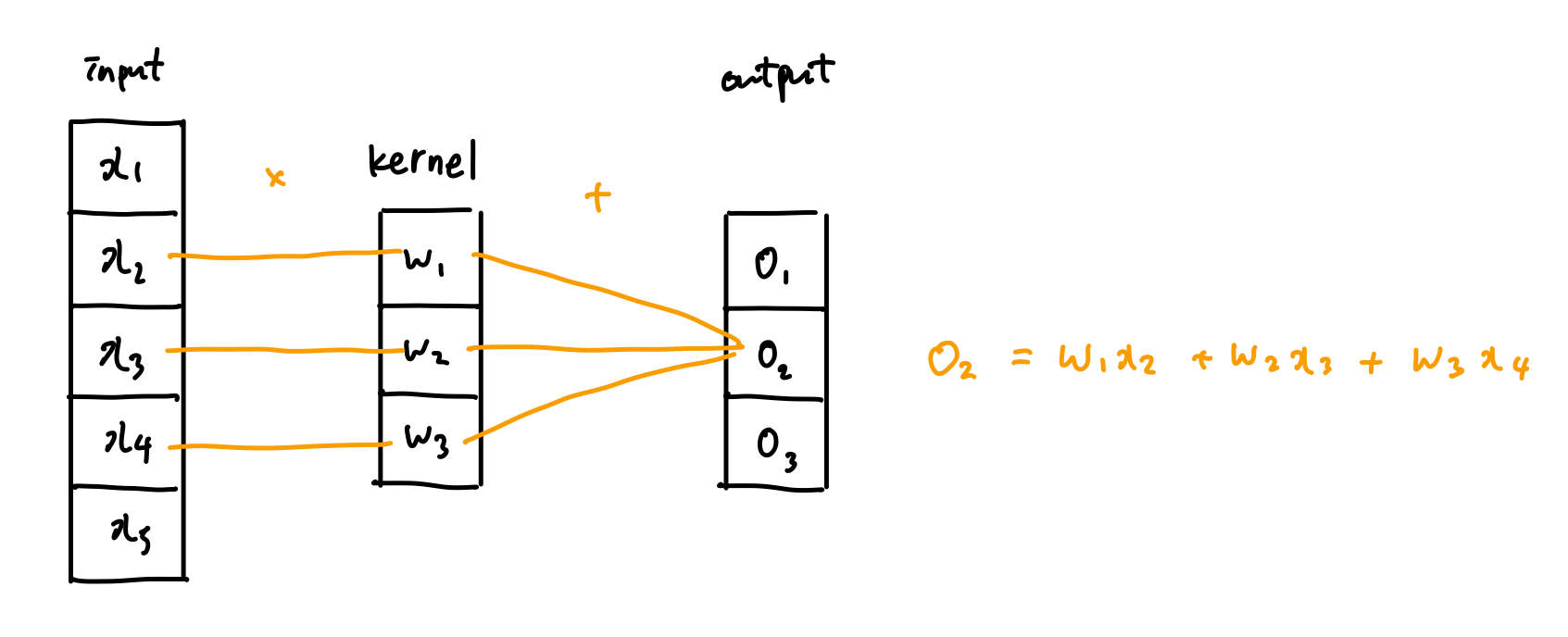
- x22의 경우 빨파노초의 4가지 가중치하고 합성곱을 했기 때문에 4번의 역전파가 진행되어야 함.
- x21의 경우, 노란색 가중치, 빨간색 두 개의 가중치하고 합성곱을 진행 ⇒ 2번의 역전파 진행
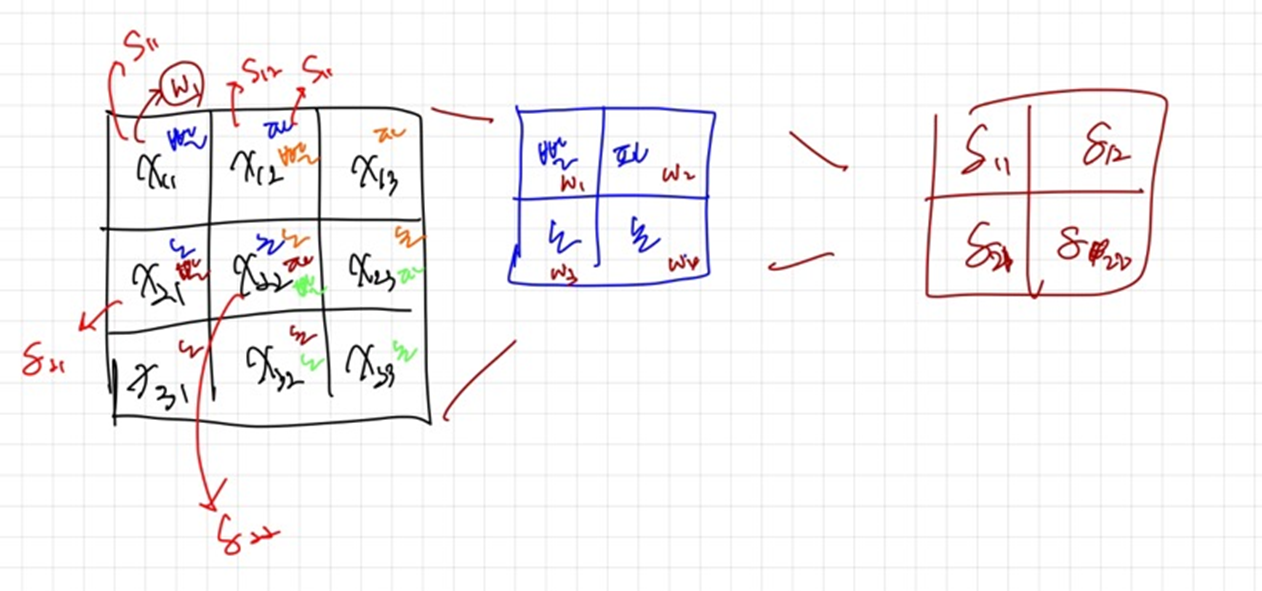
- 이것을 효과적으로 하기 위해서는 필터를 뒤집으면 수월하게 가능.

- x22에 대한 미분 값을 구하기 위해서는 저렇게 네 번의 역전파가 진행되어야 함.
- x22 * s11 + x22*s12 + x22*s21 + x22*s22 이 값이 바로 역전파한 미분의 값이라고 할 수 있음
- 이 원리는 결국 필터를 뒤집어서 곱한 값과 같음.
기존에 빨-파-노-초 였던 필터를 뒤집어서 초-노-파-빨로 하게 되면 원하는 값이 결국 다시 계산 됨 ⇒ 훨씬 수월하게 계산이 됨. ( 아래 그림 참고 )
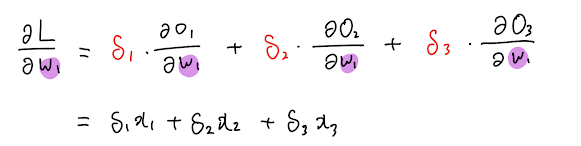
https://ratsgo.github.io/deep%20learning/2017/04/05/CNNbackprop/
https://www.philgineer.com/2021/02/cnn-5.html
2. Pooling Layer
1. Max Pooling Layer
- 이미지의 크기 줄이는 것
- 연산량 높일 수 있음

2. Max Pooling Layer Backpropagation
- forward에서 가장 큰 값을 가졌던 gradient를 보내는 것과 같음.
- max activation 위치 저장했다가 역전파 때 사용.
3. Pooling vs Conv Stride
- pooling⇒크기를 심하게 줄이기 때문에 오버피팅 방지효과 등으로 활용
- 점점 사용 x
728x90
반응형
'Deep Learning > 2023 DL 기초 이론 공부' 카테고리의 다른 글
| [Standford_cs231n] Lecture 3 ) Loss Functions and Optimization (0) | 2023.07.08 |
|---|---|
| [Standford_cs231n] Lecture 4 ) Introduction to Neural Networks (0) | 2023.07.08 |
| [Standford_cs231n] Lecture 6 ) Training Neural Networks I (0) | 2023.07.07 |
| [Standford_cs231n] Lecture 7 ) Training Neural Networks II (0) | 2023.07.07 |
| [Standford_cs231n] Lecture 8 ) Deep Learning Software (0) | 2023.07.07 |



