728x90
반응형
1) 손글씨 숫자 인식 심층 CNN 특징

- 층이 깊어지면서 채널 수는 더 늘어나는 것이 특징임
- 중간에 풀링 계층을 추가→ 중간 데이터의 공간 크기를 점차 줄임
- 마지막 완전연결 계층 → 드롭아웃 사용
- Adam 활용해 최적화
- 가중치 초깃값: he 초깃값(relu에서는 he 초깃값 사용)
- 3x3 필터 사용한 합성곱 계층 활용
2) 데이터 확장
- 입력 이미지 알고리즘을 통해 인위적으로 확장함
- 데이터가 많이 없을 때 효과적임
- 회전
- 세로로 이동
- crop(이미지 일부 자르기)
- flip (이미지 좌우 뒤집기) - 대칭성 고려 x시
- 크기 수정
- 밝기 변화

3) 층 깊게 하는 이유
- 더 적은 매개변수로 표현력 달성이 가능
- 파라미터가 많으면 오버피팅 발생 높아


- 55의 합성곱 연산 1회는 33의 합성곱 연산을 2회 수행하여 대체할 수 있다.
- 전자의 매개변수가 25개(55)인 반면 후자는 총 18개(23*3)이며 매개변수의 수는 층을 반복할수록 적어진다.
- 많은 데이터를 분배해서 계층적으로 분해가 가능 ( 국소적 계산과 같음 - 단순한 계산 가능)
4) 대표적 신경망
1. VGG
- 합성곱 계층과 풀링 계층으로 구성되는 기본적 CNN
- 합성곱 계층 + 완전연결 계층 → 16층으로 심

- 3*3의 작은 필터 사용
- 합성곱 계층을 2~4회 연속으로 풀링 계층을 둠 → 크기를 절반으로 줄이는 처리를 반복 → 마지막에 완전연결 계층 통과 후 결과 출력
2. GoogLeNet
- Inception module
- → 공간의 지역적 특징을 가장 효과적으로 표현하기 위해 도입
- 신경망 안에 또 신경망
- 입력데이터를 가지고 크기가 다른 세가지 필터를 병렬로 사용함

- 1x1, 3x3, 5x5 크기 커널로 공간의 지역적 특징 세분화해서 분리 후 계산→ 마지막 계층에서 결합.
- 1x1 합성곱 연산의 경우, 채널 쪽으로 크기를 줄이는 역할을 함
- 1x1 합성곱 계층에서는 ReLU 활성화 함수가 사용됨 → 3x3, 5x5의 계층 계산의 복잡함을 감소시킴, 매개변수 제거

3. ResNet
- 스킵 연결
- 학습에서 층이 너무 많아지면 오히려 학습이 잘 되지 않게 되는 경우 발생
- → 이를 보완한게 ResNet
- 입력 데이터를 합성곱 계층을 건너뛰어 출력에 바로 더하는 구조를 말함
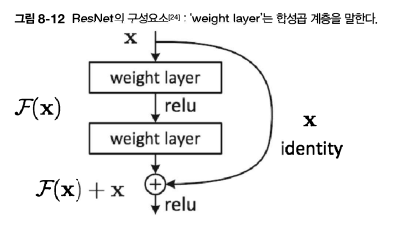
- 입력 x를 두 합성곱 계층을 건너뛰었음
- 따라서 출력값: F(x) + x
- 스킵연결의 경우, 기울기 소실을 막아줌
- 스킵연결은 입력 데이터를 그대로 흘리는 것 → 즉, 역전파 때도 상류의 기울기를 하류에 그대로 보냄 → 따라서 기울기가 작아지거나 커지지 x → 앞 층에 의미 있는 기울기가 전해짐 → 기울기 소실을 막게 해줌

- 전이학습이란?
- 데이터 셋이 적을 때 유용 ex) 기존 데이터 셋으로 학습한 가중치들을 실제 제품에 활용하는 경우
- 학습된 가중치들을 신경망에 미리 복사→ 미리 학습된 가중치를 초깃값으로 설정 → 새로운 데이터셋을 대상으로 재학습.
4. DenseNet
- ResNet의 확장된 버전임
- Resnet의 경우, 이전 layer과 다음 layer에 skip connection을 적용하는 모델임
- DenseNet의 경우, 모든 Layer에 skip을 적용. (첫번째 레이어에 대한 정보를 두번째, 세번째 마지막 레이어에도 함께 학습 시킴.

728x90
반응형
'Deep Learning > 2023 DL 기초 이론 공부' 카테고리의 다른 글
| [파이썬 딥러닝 파이토치] Part2 (0) | 2023.07.08 |
|---|---|
| [밑바닥부터 시작하는 딥러닝 1] chap7(합성곱 신경망) (0) | 2023.07.08 |
| [파이썬 딥러닝 파이토치] Part3 (0) | 2023.07.08 |
| [파이썬 딥러닝 파이토치] Part5 (0) | 2023.07.08 |
| [Standford_cs231n] Lecture 2 ) Image Classification (0) | 2023.07.08 |



