728x90
반응형
1. Intro
- 같은 read라고 해도 현재형과 과거형이 있음 -> 앞에서만 예측을 해서 출력하면 정확히 모르기 때문에, 뒤에서부터 오는 애들을 가지고 예측을 해서 read가 과거형으로 쓰인다! 라고 알려주는게 엘모의 역할
2. Overall architecture

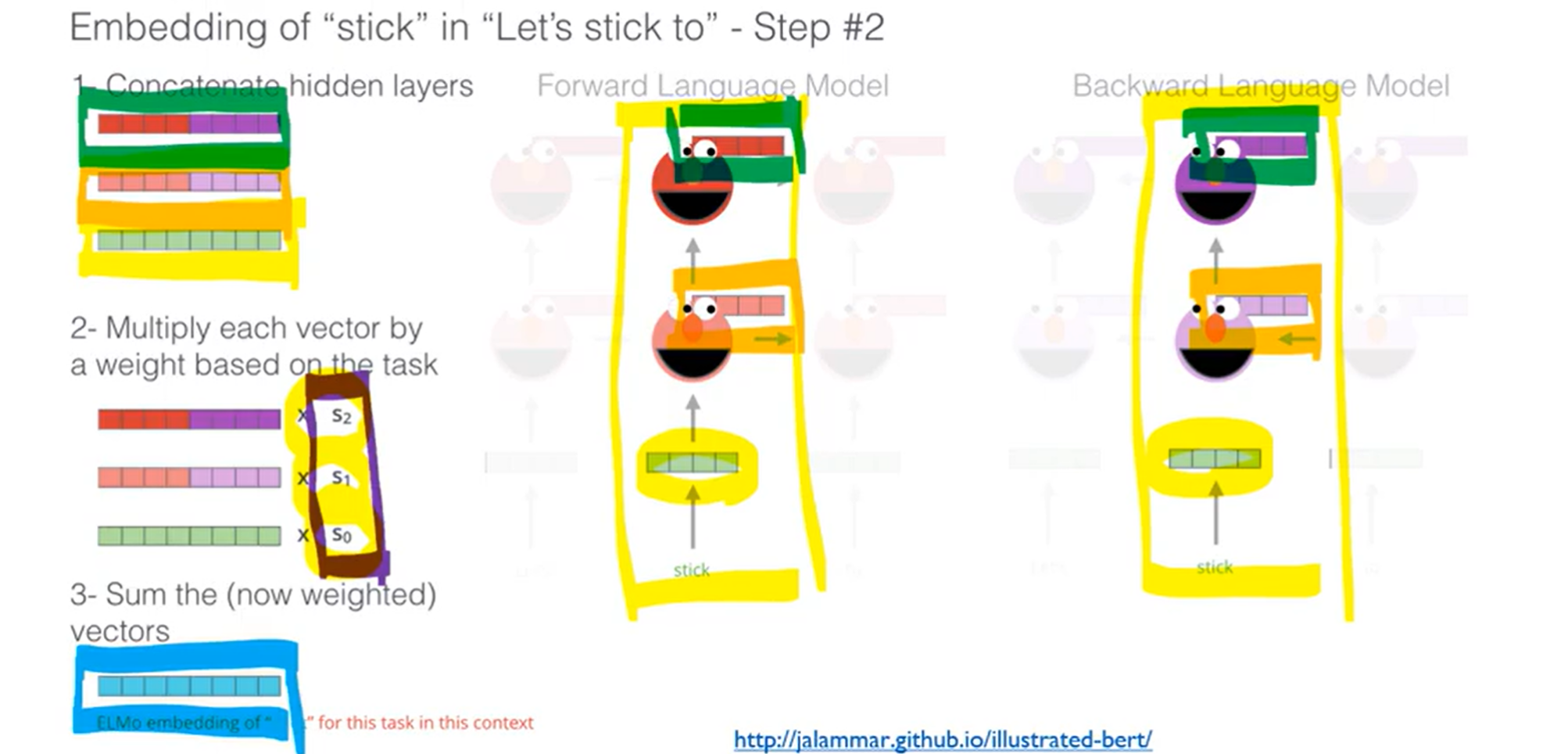
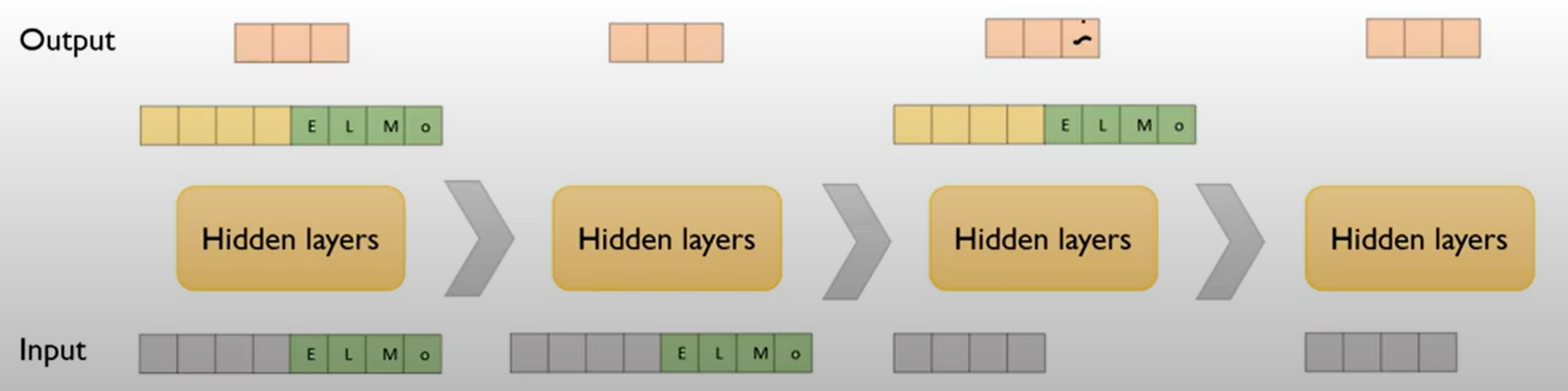
- read에 해당하는 친구를 뽑는다
- forward 부분과 backward 부분을 함께 학습시킴
- 이때, word embedding 부분, LSTM1층, LSTM2층 등 각각의embedding과 LSTM끼리 concat을 시킴
- 이후, 알맞게 가중치를 곱해줌 ( 이때 아래에 있을수록 문법적인 측면에서의 벡터이고, 위로 갈수록 문맥에 맞는 벡터라고 함)
- 이후, 가중합을 하면 하나의 벡터가 만들어짐 → read에 대한 embedding 층에 elmo 값을 붙인 후, output 전에 LSTM 층에도 옆에 elmo 값을 붙여서 학습 진행
3. Bidirectional language models (biLM)
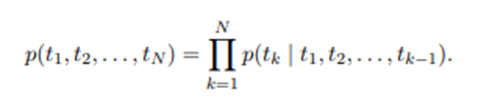
- t(k) k번째에 대한 토큰 구하는 식
- token Sequence의 확률을 계산할 때, token tk 의 확률을 이전 token들 (t1,...,tk−1)을 활용해서 모델링함
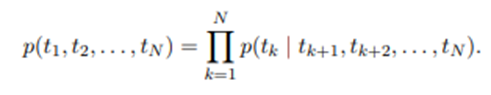
- 반대로 backward LM은 Token Sequence의 확률을 계산할 때, token tk의 확률을 k 시점 이후의 token들 (tk+1,...,tN) 을 활용하여 모델링

- 위의 forward, backward Language Model을 합쳐 함께 확률을 최대화 하는 방법으로 진행
4. ELMo

- 총 2L +1 개의 representation을 계산 (순전파 LSTM + 역전파 LSTM + input embedding)
- 즉, LSTM이 두개면, 총 5개의 representation을 계산한다고 생각하면 됨
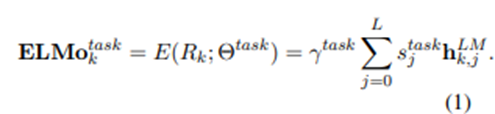
- 위의 식과 같은 설명
- (가중치(s0,s1,s2) x 각 LSTM 층의 값의 합) x scaling값
- 감마 task: ELMo vector 크기를 scaling 해줌
5. Where to include ELMo?

- input과 output 직전
- input만
- output 직전⇒ input과 output에 넣었을 때가 가장 성능 좋았음
6. Evaluation
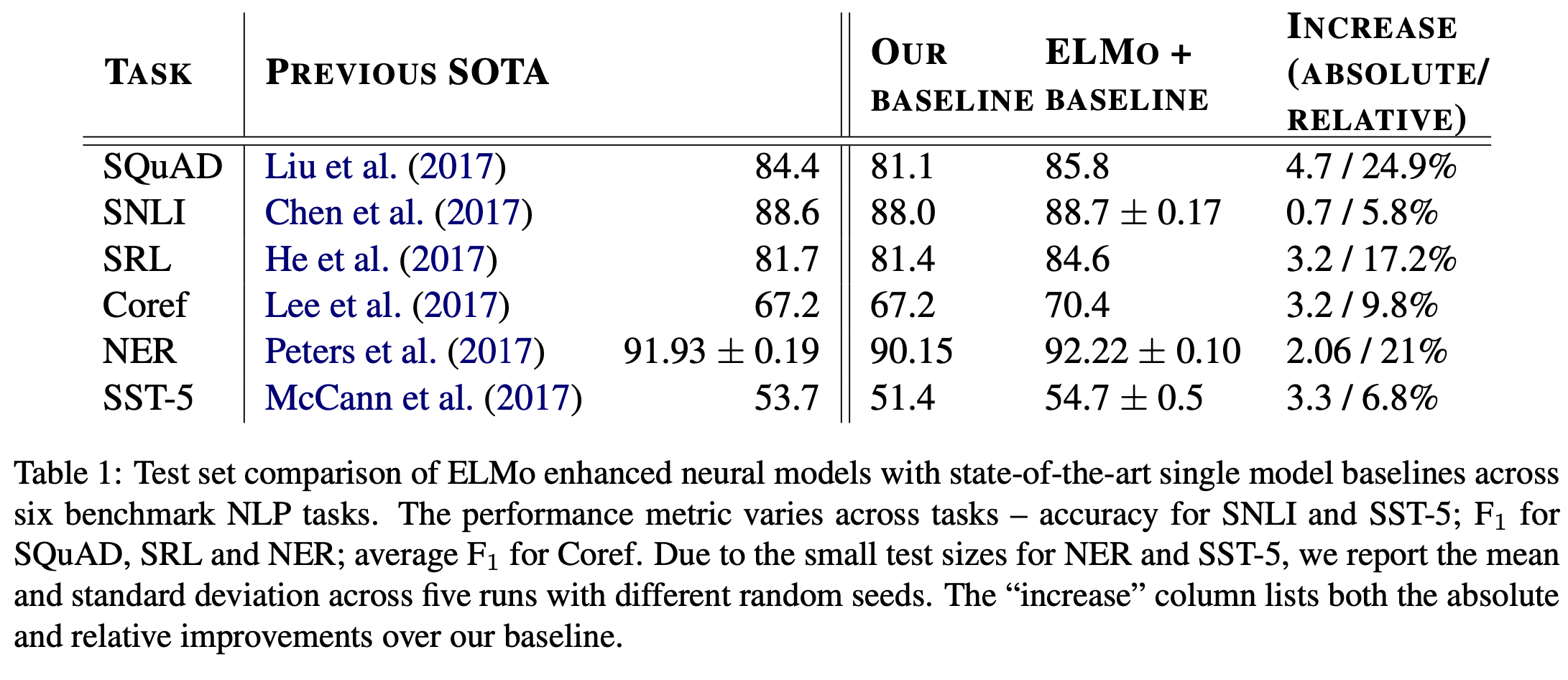
ELMo를 단순하게 추가하는 것만으로도 baseline model에 비해 성능이 향상됐고, 이를 통해 SOTA를 달성할 수 있었음
7. Outro
- biLM을 사용해 높은 수준의 context를 학습하는 ELMo model을 제안함.
- ELMo model을 사용하면 대부분의 NLP task에서 성능이 향상됨.
- layer의 층이 올라갈수록 syntax보다는 semantic한 정보를 담아낸다는 사실도 발견해냄.
- 때문에 어느 한 layer를 사용하는 것보다는 모든 layer의 representation을 결합해 사용하는 것이 전반적인 성능 향상에 도움이 된다는 결론을 내릴 수 있음.
728x90
반응형
'Deep Learning > [논문] Paper Review' 카테고리의 다른 글
| Transformer (0) | 2023.07.06 |
|---|---|
| Inception V2/3 (0) | 2023.07.06 |
| SegNet (0) | 2023.07.06 |
| CycleGAN (0) | 2023.07.05 |
| XLNet: Generalized Autoregressive Pretraining for Language Understanding (1) | 2023.07.05 |



