- XLNet은 GPT로 대표되는 auto-regressive(AR) 모델과 BERT로 대표되는 auto-encoder(AE) 모델의 장점만을 합한 generalized AR pretraining model.
- 이를 위해 permutation language modeling objective과 two-stream attention mechanism을 제안.
- 다양한 NLP 테스크에서 기존 대비 상당한 향상을 보이며 state-of-the-art 성능을 보임.
1. Intro
- 최근 많은 양의 corpus를 이용하는 unsupervised representation learning이 활발히 연구되고 있음
- Pre-training을 통해 얻어진 representation (word2vec, ELMO 등)을 직접적으로 활용하거나 pre-trained model을 downstream task에 대해 fine-tuning 하는 방법(GPT, BERT 등)이 성공적인 결과를 보여줌.
- Pre-training 단계에서도 여러 objective들이 이용되어 왔는데, 그 중 가장 대표적인 두 가지를 소개함 (AR + AE)

1-1) Autogressive(AR)
- 일반적인 Language Model (LM)의 학습 방법으로 이전 token들을 보고 다음 token을 예측하는 문제. ex) ELMO, GPT RNNLM 등이 포함
- 단일 방향 정보를 통한 예측
- AR은 방향성(forward, backward)이 정해져야 하므로, 한쪽 방향의 정보만을 이용할 수 있음
- 따라서 양방향 문맥을 활용해 문장에 대해 깊이 이해하기 어려움.
- ELMO의 경우 양방향을 이용하지만, 각각의 방향에 대해 독립적으로 학습된 모델을 이용하므로 얕은 이해만 가능함
1-2) Auto Encoding(AE)
- Auto Encoder는 주어진 input에 대해 그 input을 그대로 예측하는 문제를 풀고, Denoising Auto Encoder은 noise가 섞인 input을 원래의 input으로 예측하는 문제를 품.
- BERT같은 경우는주어진 input sequence에 임의로 추가한 noise(
[MASK]token)가 주어졌을 때,[MASK]token 을 원래 input token으로 복구하고자 함.
- 따라서 Denoising Auto Encoder의 방식으로 볼 수 있음
1-3) AR과 AE의 문제점
- AR
- 단일 방향 정보만 이용해서 학습 가능함
- AE
- [Mask] token이 독립적으로 예측 (independent assumption) 되기 때문에, token 사이의 dependency는 학습할 수 없음
- Fine tuning 과정에서 [Mask] token이 등장하지 않기 때문에, pre-training과 fine-tuning 사이에 불일치 발생할 수 있음
2. Proposed Method: XLNet
- 위의 단점을 보완하고, 장점을 살리기 위해 아래 3가지의 방법론이 제안됨
- 새로운 Objective (Permutation Language Modeling)
- 이를 반영하기 위한 Target-Aware Representation
- 위 내용들과 Transformer 구조를 동시에 이용하기 위한 새로운 Two-Stream Self-Attention 구조
1. Permutation Language Modeling Objective
- AR모델의 장점을 유지하되, 양방향 컨텍스트를 확보(AE의 장점을 활용하고자..한 듯)할 수 있도록 하는 모델.
- input sequence index(순서)의 모든 permutation을 고려한 AR 방식 사용.
- input sequence [x1,x2,x3,x4]에 대해서 index(순서)의 permutation의 집합은 총 4!=24개가 존재하며 ZT=[[1,2,3,4],[1,2,4,3],[1,3,2,4]…[4,3,2,1]]로 나타낼 수 있음

→ Permutation 집합을 통해 다양한 sequence 고려하게 됨
→ AR(단방향)으로는 추구하지 못했던 양방향성을 AR objective function에 대입함으로써 특정 토큰에 대한 양방향 context를 고려할 수 있음
➡️ AR 방식이므로 independent assumption(독립 가정)을 할 필요가 없고, [MASK] token을 이용하지 않으므로, pre-training과 fine-tuning사이의 불일치도 없고 AE방식의 한계를 극복할 수 있음.

- 예를 들어, 토큰 3에 대해 예측하고자 한다고 가정
- [3,2,4,1]→ 토큰의 정보를 가져오지 않음
- [2,4,3,1]→ 2,4,3,1 순서이기에, 2,4의 정보에 대한 토큰을 가져옴
- [1,4,2,3]→ 1,4,2의 정보에 대한 토큰을 가져옴
2. Architecture: Two-Stream Self-Attention for Target-Aware Representations
- 하지만 논문에서 제시하는 방법은, Standard Transformer parameterixation에서는 작동하지 않음→ 학습 시에 permutation해서 예측할 token이 명확하지 않는다는 문제 발생예를 들어, [1,2,3,4] 순서로 x3을 맞춰야 한다면, x1과 x2의 정보를 통해 x3을 맞춰야 함.즉, 동일한 representation으로 다른 target을 맞춰야 하는데, 위의 방식을 통해 적용한다면 뭉개지는 현상이 발생할 수 있다는 것임 (학습이 잘 안되겟죠)
- 또한 [1,2,4,3]의 경우는 x4를 맞춰야할 경우, x1,x2의 정보를 통해 x4를 맞춰야 함.

➡️ 이 문제점을 해결하기 위해서 이전의 context token들의 정보 (xz<t)뿐만 아니라 target index의 position 정보 (zt)도 함께 이용하는 새로운 Target Position-Aware Representation을 제안함 ⇒ hθ(xz<t)→gθ(xz<t,zt)
1. Two-Stream Self-Attention
→ target position 정보를 추가적으로 이용하는 gθ 를 어떻게 구성할지의 문제가 남아있음. gθ의 조건 두 가지를 고려해야 함

- 특정 시점 t에서 target position zt 의 token xzt을 예측하기 위해, hidden representation g(xz<t,zt)는 t 시점 이전의 context 정보 xz<t 와 target position 정보 zt 만을 이용해야 함.→ zt(target)의 위치만 사용하고, 내용은 사용하면 안됨
- 특정 시점 t 이후인 j (>t) 에 해당하는 xzj 를 예측하기 위해, hidden representation g(xz<t,zt) 가 t 시점의 content인 xzt 를 인코딩해야 함.→ T 시점의 context도 가지고 있어야 한다 뭐 이런말인듯.
2. Query Representation
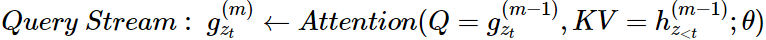
- 현재 시점을 제외한 이전 시점 token들의 content와 현재 시점의 위치정보를 이용하여 계산되는 representation

ex)
- position 3의 경우
: 3번에 해당하는 position 정보 값만 w(weight)만 가지고 학습
- position 2의 경우
: 2번의 위치 정보와 3번의 token 정보를 학습
- position 4의 경우
: 4번 위치 정보와 2,3번의 token 정보를 학습
- position 1의 경우
: 1번 위치 정보와 2,3,4번의 token 정보 학습
※ 아래의 x1,x2,x3,x4는 특정 토큰의 embedding된 값을 의미함
3. Context Representation (기존 transformer과 동일)
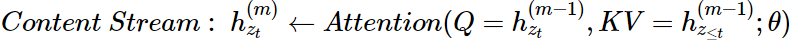
- 현재 시점 및 이전 시점 token들의 content를 이용하여 계산되는 representation
- Standard transformer의 hidden state와 동일한 역할
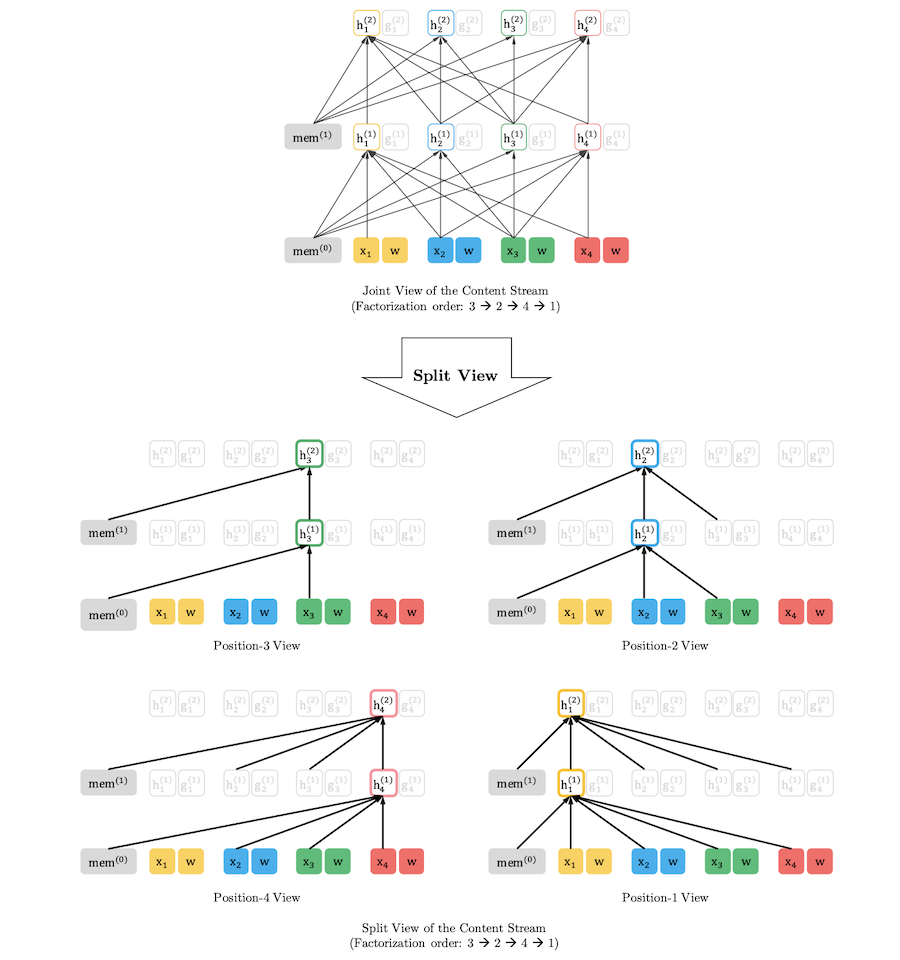
ex)
- position 3의 경우
: 3번에 해당하는 토큰 정보만 가지고 학습
- position 2의 경우
: 2번과 3번의 token 정보를 학습
- position 4의 경우
: 4, 2,3번의 token 정보를 학습
- position 1의 경우
: 1, 2,3,4번의 token 정보 학습
※ 아래의 x1,x2,x3,x4는 특정 토큰의 embedding된 값을 의미함
4. Partial Prediction
- 소개된 Objective는 Permutation을 이용하여 모든 조합의 순서로 Maximum Likelihood를 수행함
- 하지만 이는 학습 시에 느린 수렴을 유발시킴
- 이러한 Optimization difficulty를 극복하기 위해, 저자들은 특정 순서에서 마지막 몇 개의 예측만 이용하는 방법을 사용
- ex) 3 → 2 → 4 → 1 의 순서에서 마지막 2개만 예측에 이용하는 것을 의미함
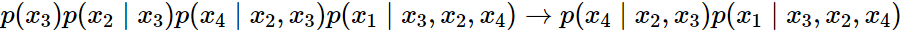
3. Incorporating Ideas from Transformer-XL
- XLNet은 긴 문장에 대한 처리를 위해 Transformer-XL (Dai et al., 2019)에서 사용된 2가지 테크닉을 차용함
- 첫 번째는 Relative Positional Encoding, 두 번째는 Segment Recurrence Mechanism
1. Relative Positional Encoding
- Self-attention을 기반으로 하는 Transformer (Vaswani et al., 2017)는 CNN이나 RNN과 달리 단어들의 상대적 혹은 절대적 위치 정보를 직접적으로 모델링하고 있지 않음.
- 대신 input에 단어의 절대적 위치에 대한 representation (absolute positional encoding)을 추가하는 방식으로 순서에 대한 모델링을 할 수 있도록 하였음.
- 하지만 이런 absolute positional encoding 방법은 하나의 segment 내에서는 위치에 대한 의미를 표현할 수 있으나 Transformer-XL과 같이 여러 segment에 대해 recurrent 모델링을 하는 경우 문제가 발생하게 됨. (절대적인 위치 정보만으로는 문장 내에서 단어 간의 관계를 충분히 모델링하기 어렵다는 것을 말함)
ex)
"The cat sat on the mat”
- 상대적인 거리:
- "cat"와 "sat" 사이의 상대적인 거리는 1입니다. 즉, 두 단어는 문장에서 바로 옆에 위치합니다.
- "on"과 "mat" 사이의 상대적인 거리는 2입니다. 두 단어 사이에 "the cat sat"라는 구가 위치하기 때문에 상대적인 거리가 더 큽니다.
- 절대적인 거리:
- "The"는 문장에서 첫 번째 단어이므로 절대적인 거리는 1입니다.
- "mat"는 문장에서 마지막 단어이므로 절대적인 거리는 6입니다.
이렇게 상대적인 거리는 단어들 간의 상대적인 위치 관계를 나타내는 반면, 절대적인 거리는 단어들이 문장 내에서 어디에 위치하는지를 나타냅니다. 각각의 정보는 문장의 구조와 단어 간의 관계를 이해하는 데에 도움을 줄 수 있습니다.

<수식 참고>
1. Term (b)와 (d)에서 기존 absolute positional embedding Uj 를 relative positional embedding Ri−j로 대체합니다. R 은 learnable parameters가 아닌 sinusoid encoding matrix (Vaswani et al., 2017)입니다.
2. Term (c) 와 (d) 에서 U⊤iW⊤q 를 각각 u⊤∈Rd와 v⊤∈Rd로 대체합니다. Query vector가 모든 query position에 대해 같기 때문에, 다른 단어들에 대한 attention bias가 query position에 상관없이 동일하게 유지되어야 합니다.
3. Wk 를 Wk,E 와 Wk,R 로 분리합니다. 이는 content 기반의 key vector와 location 기반의 key vector를 각각 만들어내기 위한 것입니다.결과적으로 각 term들은 다음의 직관적인 의미를 지닙니다: 1) Term (a)는 content를 기반의 처리를 하고, 2) (b)는 content에 의존한 positional bias를 잡아내고, 3) (c)는 global content bias를, 4) (d)는 global positional bias를 인코딩함
2. Segment Recurrence Mechanism
- 예를 들어 긴 시퀀스에서 두 개의 세그먼트를 선택한다고 가정.
- 첫 번째 세그먼트를 처리한 후 얻은 내용 표현을 캐시(cache)에 저장
- 그런 다음 두 번째 세그먼트를 처리할 때, 이전 세그먼트에서 얻은 내용 표현을 사용하여 어텐션(attention)을 업데이트 시킴
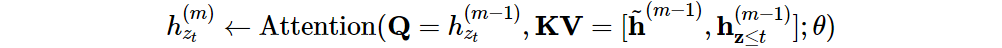
- 즉, 기존에는 단어 순서대로 정리해서 factorization order를 알았어야 했는데, segment recurrence mechanism은 문장 단위로 저장을 하기 때문에, 해당 segment 내용 표현을 메모리에 저장한 다음, 이후 segment에서 재사용할 수 있다는 것을 의미함 → 이를 통해 과거 segment에 대한 factorization order를 고려하지 않고 memory의 caching과 reusing이 가능함 (이게 위의 의미와 같은 말)
- "나는 사과를 좋아합니다."
- "사과는 맛있어요."
- 순열 기반 설정에서는 첫 번째 세그먼트를 처리한 후, 해당 세그먼트의 내용 표현을 메모리에 저장합니다. 이후 두 번째 세그먼트를 처리할 때, 이전 세그먼트에서 얻은 메모리를 활용할 수 있습니다. 이때, 이전 세그먼트의 인자화 순서를 알 필요 없이 메모리를 캐싱하고 재사용할 수 있습니다.
- 따라서, 두 번째 세그먼트에서 "사과는 맛있어요"라는 문장을 처리할 때, 첫 번째 세그먼트의 정보인 "나는 사과를 좋아합니다"를 활용할 수 있습니다. 이전 세그먼트에서 얻은 정보를 재사용함으로써 두 세그먼트 간의 관계를 학습할 수 있습니다.
'Deep Learning > [논문] Paper Review' 카테고리의 다른 글
| SegNet (0) | 2023.07.06 |
|---|---|
| CycleGAN (0) | 2023.07.05 |
| Inception-v4, Inception-ResNetand the Impact of Residual Connections on Learning (0) | 2023.07.05 |
| Seq2Seq (0) | 2023.07.05 |
| U-Net (0) | 2023.07.05 |



