728x90
반응형
1. Intro
1) DNNs(Deep Neural Networks)
- 음성 인식, 사물 인식과 같은 문제에 아주 좋음
- 하지만 이 친구는 input, output이 고정된 차원의 벡터로 인코딩 된 문제에만 적용할 수 있다는 단점 발생
- 음성인식이나 기계 번역 같은 문제들은 길이를 알 수 없는 시퀀스로 표현됨
- 대표 예로) question-answering 문제는 질문에 대한 정답 시퀀스로 매칭해줘야 함
- 따라서 DNN은 입출력 차원을 알아야 하고, 고정되어야 하기 때문에, 기존의 방법은 해결하기에 어려움이 발생
- ex) ‘나는 너를 정말 사랑해’ ⇒ ‘ I love you so much’
- ex) 문장 단어 개수에 맞춰서 I love you very 라는 어색한 문장 출력
- 그래서 나온게 LSTM이다.
- RNN vs LSTM
- RNN의 경우, 문장 구성 단어를 입력하면 그 때마다 출력을 내놓음
- LSTM의 경우, 문장 하나를 끝까지 듣고, 하나의 완전한 문장 만듬
- 문장 전체를 하나의 단위로 보기 때문에, input과 output(target)의 토큰 개수가 달라도 된다는 장점
2. Overall architecture

- encoder + decoder로 구성
- 입력 시퀀스를 하나의 context vector로 표현, 디코더에서는 context vector을 기반으로 시퀀스 출력
- encoder : 입력된 sequence를 벡터의 형태로 압축하여 decoder로 전달
- decoder : 전달 받은 벡터를 첫 셀의 hidden state로 넣어주고 이 문장이 시작한다는 start flag와 함께 모델 시작. 셀에서 나온 output을 문장의 첫 단어로 두고 이것이 다시 두번째 셀의 input과 함께 들어가는 과정 반복=> "encoder에서 모든 문장을 들은 후" decoder에서는 하나의 완전한 문장 출력
3. RNN VS LSTM
1) RNN

- 입력 (x1,x2 ~ xt)
- 출력(y1,y2 ~ yt)
- output의 경우, 위 식과 같이 계산
- but, 입출력 길이의 연관성 (나는 너를 많이 사랑해 ⇒ I love you so much I // love you very)을 알 수 없을 때는 적용하기 어려움

- LSTM 공식
4. LSTM

- encoder
- 예시의 경우, 4개의 토큰이 존재
- 첫번째 토큰을 임베딩에 통과시킨 입력값을 초기 h0(은닉값)을 인코더에 통과
- 출력된 h1과 guten을 임베딩 투여한 값과 같이 인코더에 통과
- 이런식으로 계속 반복해서 고정길이벡터(context vector)을 추출.
- decoder
- 디코더의 경우, context vector를 sos와 함께 넣어서 s1 추출.
- s1이 linear function을 거쳐서 ‘good’ 나타내는 벡터 추출
- 이 출력값(y1)을 s1과 함께 다음 디코더 입력값으로 사용.
- 이런식으로 반복
5. Add
- encoder와 decoder은 서로 다른 LSTM 구조
- 4개의 층 LSTM 사용
- 토큰 순서를 뒤집었더니 성능 향상
- ex) a,b,c/g,d,e ⇒ c,b,a/g,d,e 이런식으로.⇒ a는 g에 가깝고, b는 d에 가깝고 이런식으로 함으로써 입력과 출력의 사이에 통신을 쉽게 만듬 (데이터 변환)이라는 순서로 바꾸면, 디코더에서 출력값을 생성하기 시작하는 것을 조금 더 쉽게 만들어줌. 그래서 전체 출력값을 생성하는 것에 있어서 조금 더 적합하게 만들어줌.
- 샀다 딸기잼을 나는 → I ~로 바로 출력층에서 나오게
- ⇒ 쉽게 말하자면, 나는 딸기잼을 샀다→ 샀다 딸기잼을 나는
6. Decoding- Beam Search
1. Gready Search
- 디코더: 이전 단어를 기반으로 다음 단어를 예측함
- 기본적으로는 FC를 통과한 결과에 softmax를 통해 가장 높은 확률을 가지는 단어 하나를 선택함
- 하지만 틀린값을 내놓게 되면, 그 값이 그대로 뒤로 전달해서 학습이 되기 때문에, 잘못된 결과를 내게 됨.
2. Beam Search
- 위의 gready search의 문제점을 해결하고자, beam search가 나오게 됨
- 하나의 출력값만 내보내는 것이 아니라, beam(k)개수 만큼 출력값을 내놔서 여러 후보군을 줘서 문장을 출력시킴 ⇒ 마지막에 가장 좋은 출력 문장이 뭔지를 판단하는 방법을 말함
장점: 다양성을 줌 ⇒ 틀린 답을 내놔도 다른 후보 문장들에서 더 알맞은 답을 내놓았을 것이라고 생각함 ⇒ 최적화에 좀 더 강인해짐!
단점: 연산량 증가, 문장이 길어지게 되면 정확도 떨어질수도
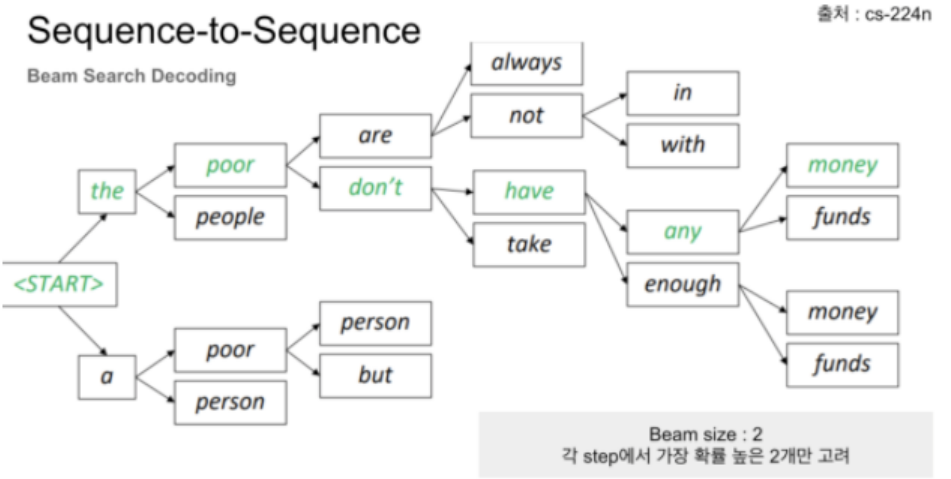
- 첫번째 decoding 단계에서 상위 k개 후보 고려(softmax 기준 확률 높은 k개)
- k개의 첫 단어에 대해 k개 두번째 단어 생성
- 첫번째, 두번째 단어를 조합해서 상위 k개 조합 선택
- 상위 k개 조합에서 k개 세번째 단어 선택 후 3,4번 반복
- 종료되면 점수가 가장 높은 문장을 선
7. Reference
728x90
반응형
'Deep Learning > [논문] Paper Review' 카테고리의 다른 글
| XLNet: Generalized Autoregressive Pretraining for Language Understanding (1) | 2023.07.05 |
|---|---|
| Inception-v4, Inception-ResNetand the Impact of Residual Connections on Learning (0) | 2023.07.05 |
| U-Net (0) | 2023.07.05 |
| Bert (0) | 2023.07.05 |
| VIT [AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE] (0) | 2023.07.05 |



